正則化$f$-ダイバージェンス・カーネル検定
本研究は、$f$-ダイバージェンスの族に基づく新しいカーネル二標本検定の枠組みを提案し、正則化された変分表現とカーネル法による尤度比推定を組み合わせることで、多様な分布間の差異を統計的に検出可能にしました。
TL;DR(結論)
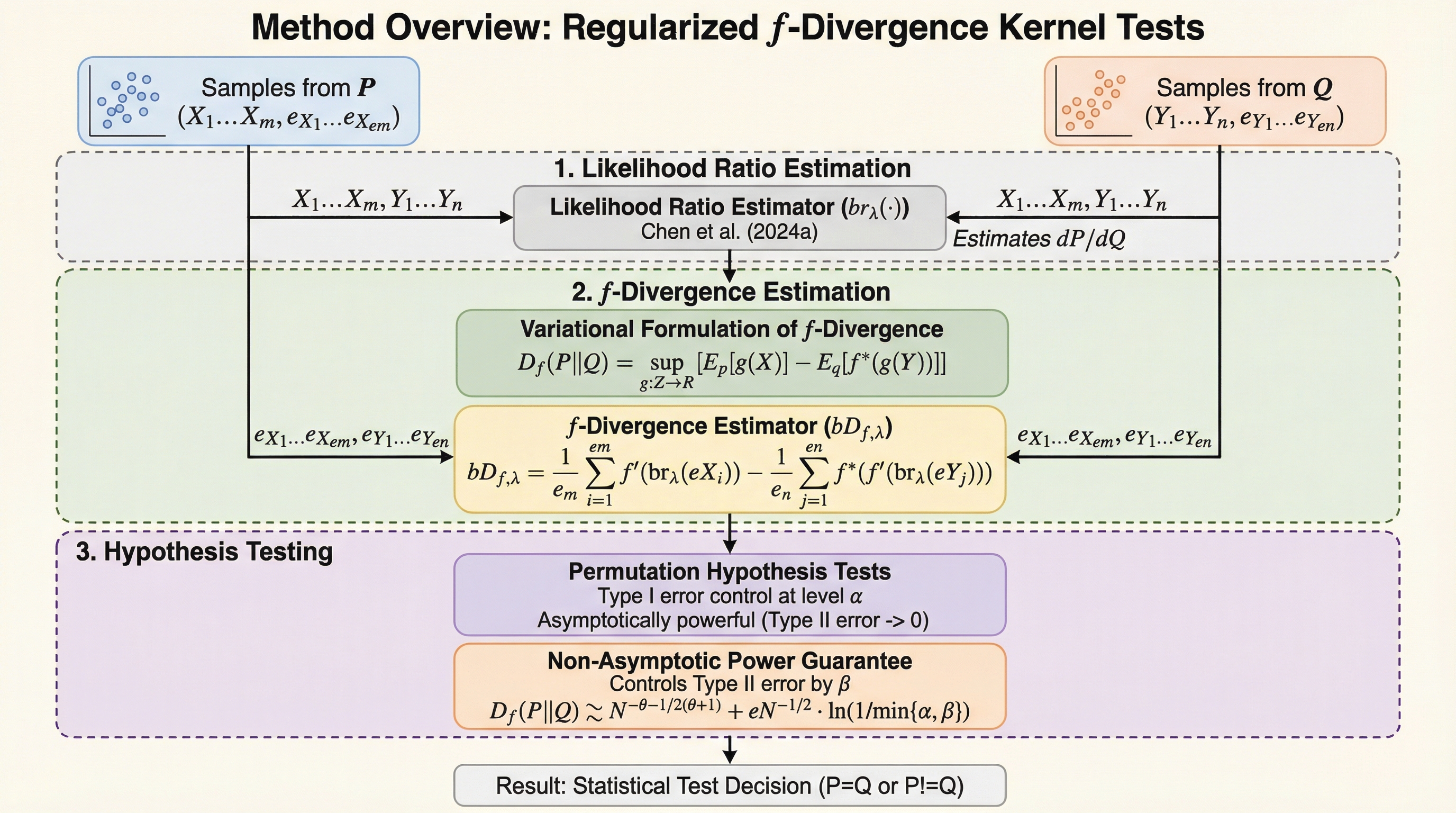
本研究は、$f$-ダイバージェンスの族に基づく新しいカーネル二標本検定の枠組みを提案し、正則化された変分表現とカーネル法による尤度比推定を組み合わせることで、多様な分布間の差異を統計的に検出可能にしました。 複数の検定を統合する「$f$-Agg」を用いることで、特定の指標では見逃される局所的な差異も高感度に捕捉でき、理論的な検出力の収束率も数学的に保証されており、ハイパーパラメータに対しても適応的な性質を持っています。 実用面では、ホッケースティック・ダイバージェンスを用いたプライバシー監査や、再学習モデルとの比較を行う「相対距離検定」によるマシンアンラーニングの評価において、従来の絶対距離検定の欠陥を克服する高い信頼性を実証しました。
なぜこの問題か
統計学における二標本検定は、二つのデータセットが同一の基礎分布から生成されたかを判定する基盤的な技術であり、現代の機械学習における信頼性評価において不可欠な役割を担っています。この手法は、機械学習モデルのプライバシー保護性能を検証する監査や、特定のデータを削除するマシンアンラーニングの効果測定、さらには物理科学におけるモデルの妥当性確認など、極めて広範な分野で応用されています。既存の代表的な手法として最大平均差異(MMD)が存在しますが、これは分布の滑らかな変化を捉えるのには適しているものの、特定の領域に限定された微妙な差異や局所的な構造の変化を見逃してしまうという弱点があります。 また、差分プライバシーやアンラーニングの文脈では、許容される情報の分離度合いを定義するために、特定の予算パラメータによって特徴付けられるダイバージェンスが必要とされます。このように、あらゆるシナリオにおいて普遍的に最適、あるいは適切な単一の二標本検定は存在しないという根本的な課題があります。…
核心:何を提案したのか
本研究では、$f$-ダイバージェンスの族から二標本検定を構築するための一般的かつ実用的なフレームワークを導入しました。このフレームワークは、$f$-ダイバージェンスの変分定式化に基づいており、特定のダイバージェンスに限定されない統一的なアプローチを提供している点が最大の特徴です。具体的には、ダイバージェンスの値を最大化する関数であるウィットネス関数が、分布間の尤度比の関数として表現されることに着目しました。そして、カーネル法と$\ell_2$正則化を用いてこの尤度比を直接推定する手法を提案しました。 これにより、従来は滑らかでなく学習が困難であったウィットネス関数を、効率的かつ数学的に扱いやすい形で近似することが可能になりました。また、単一の検定手法に頼るのではなく、複数の異なる$f$-ダイバージェンス検定を一つに統合する「$f$-Agg」という集約手法も提案しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related