共鳴型スパース幾何ネットワーク
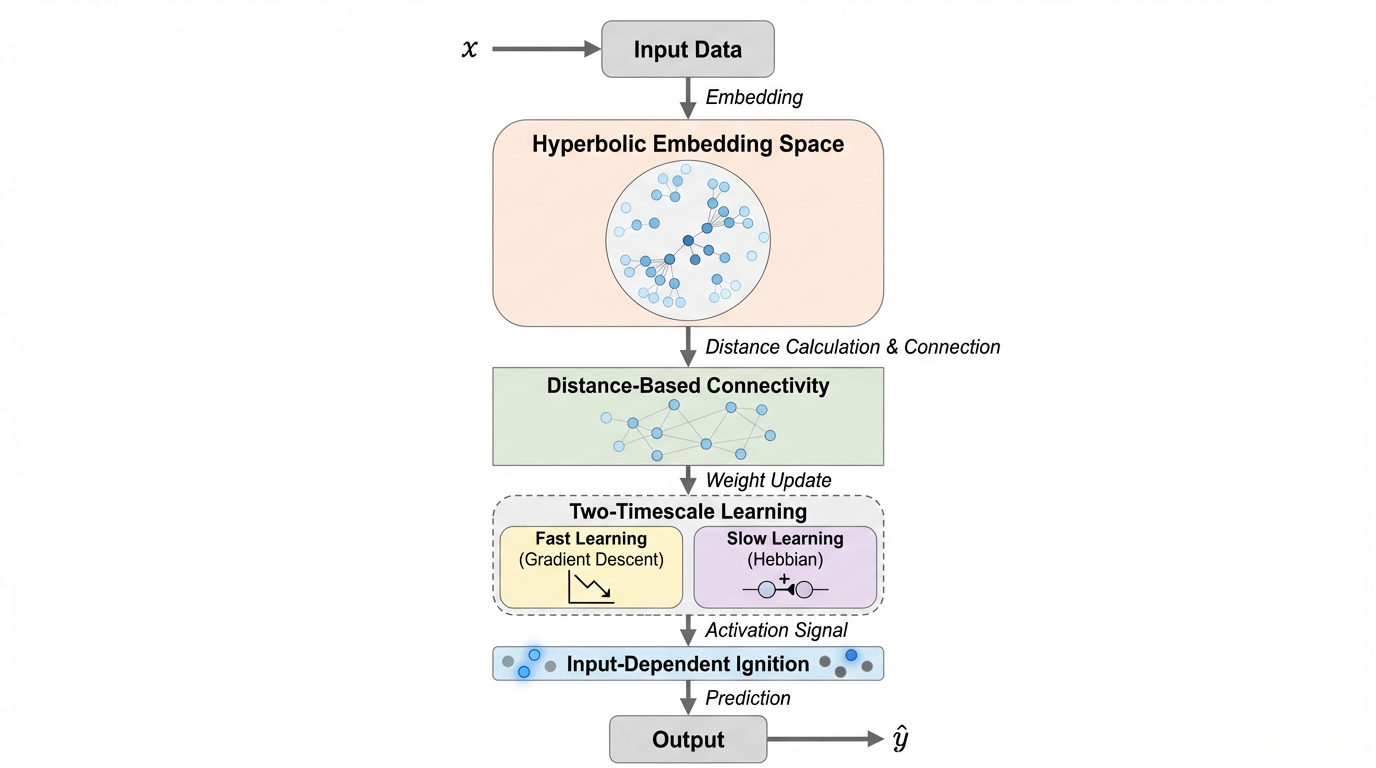
共鳴型スパース幾何ネットワーク(RSGN)は、脳の自己組織化されたスパースな接続性と動的な経路選択を模倣し、計算ノードを双曲幾何学空間(ポアンカレ球)に配置することで、従来のTransformerが抱える計算量の増大問題を根本から解決する新しいニューラルアーキテクチャである。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
共鳴型スパース幾何ネットワーク(RSGN)は、脳の自己組織化されたスパースな接続性と動的な経路選択を模倣し、計算ノードを双曲幾何学空間(ポアンカレ球)に配置することで、従来のTransformerが抱える計算量の増大問題を根本から解決する新しいニューラルアーキテクチャである。
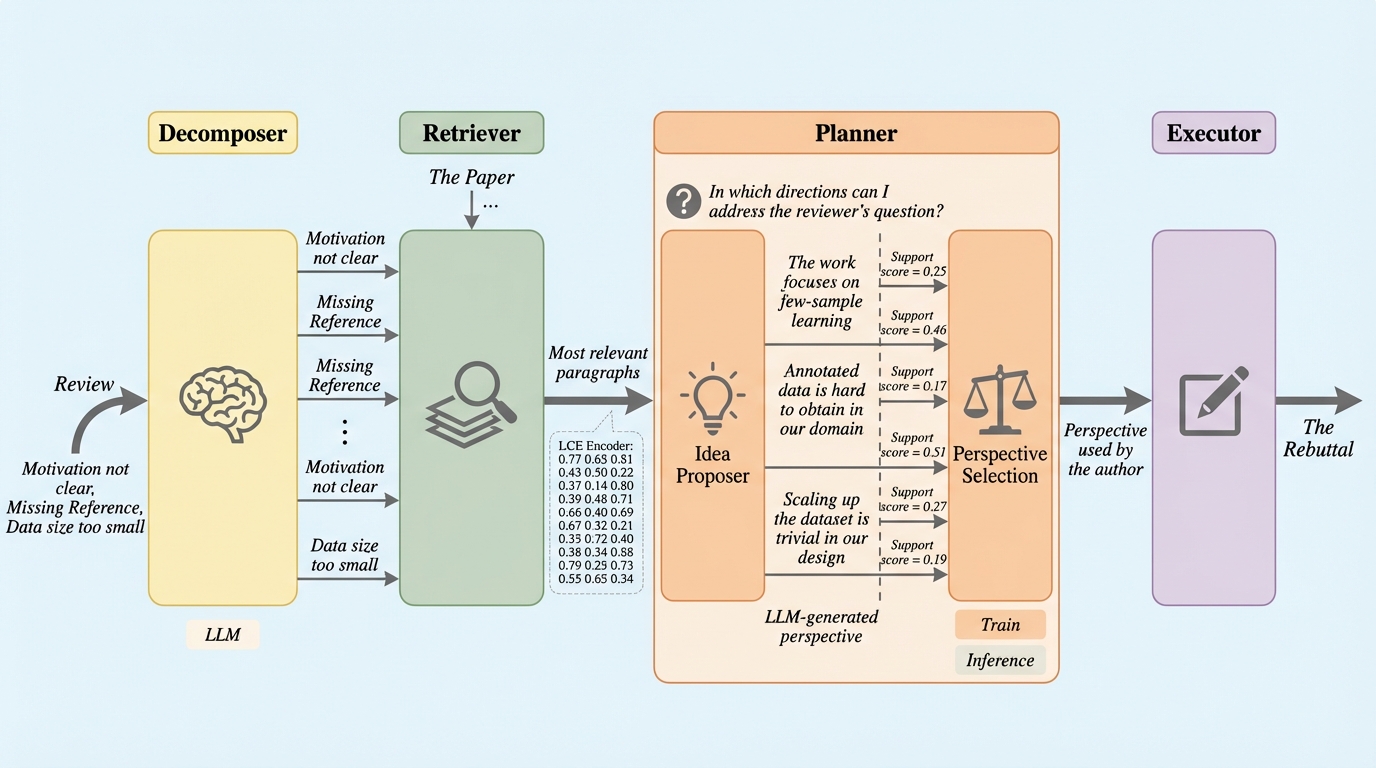
学術論文の査読に対する反論(リバッタル)を自動生成するため、査読コメントの分解、関連情報の検索、反論戦略の計画、そして最終的な回答生成という4つの段階を踏むエージェントフレームワーク「DRPG」が開発されました。
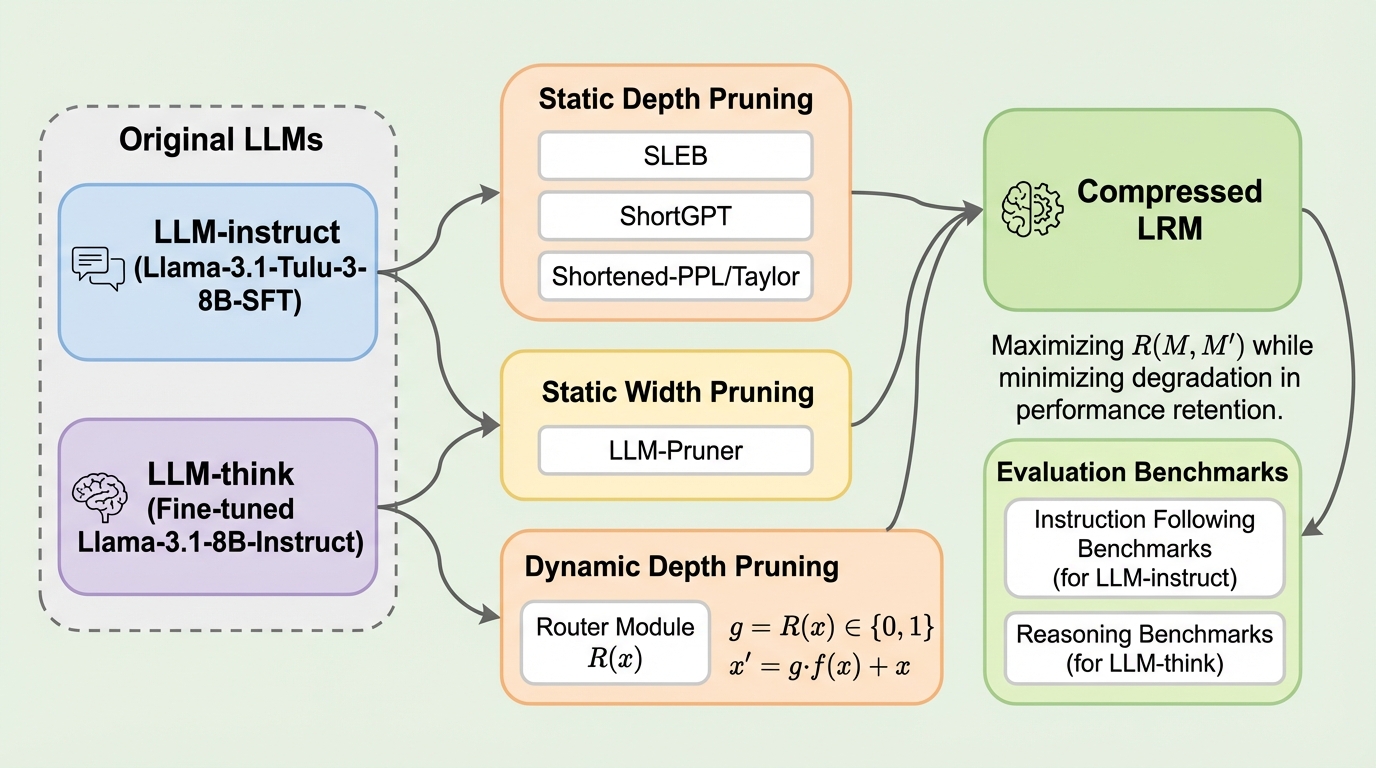
大規模言語モデル(LLM)の効率化に向けたプルーニング研究は、これまで指示追従型モデル(LLM-instruct)が中心であったが、本研究では長い思考プロセスを出力する推論中心型モデル(LLM-think/LRM)における有効性を初めて体系的に調査した。
MoReBRACは、静的なデータセットに依存する従来のオフライン強化学習の限界を打破するため、不確実性を考慮した世界モデルによる合成データ生成と、階層的なフィルタリングを統合した新しいフレームワークである。
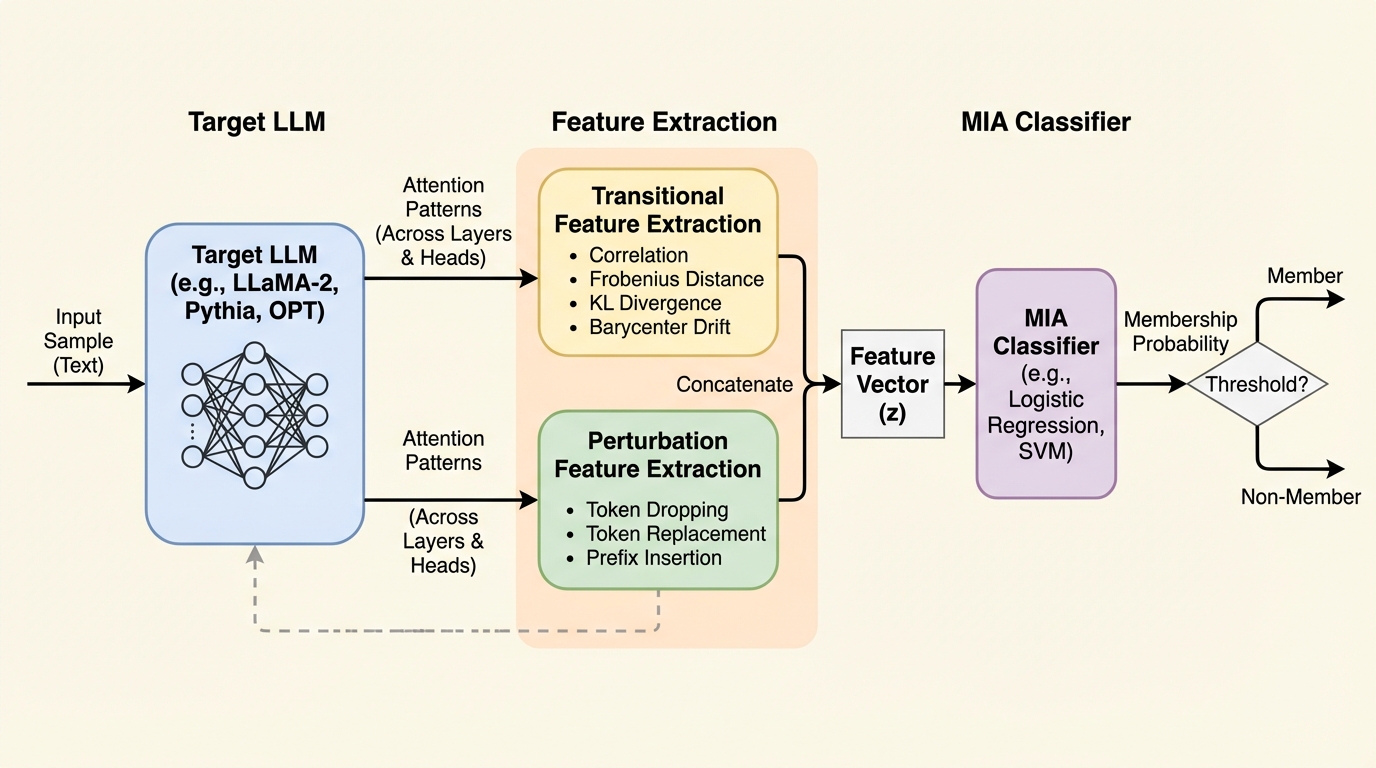
大規模言語モデル(LLM)が学習データを記憶する性質を悪用し、特定のデータが学習セットに含まれていたかを判定する新しいメンバーシップ推論攻撃(MIA)手法「AttenMIA」が開発された。この手法は、従来の出力スコアに頼る方法とは異なり、トランスフォーマー内部の自己注意(アテンション)パターンの層間遷移や、入力への微小な摂動に対する反応を分析することで、学習済みデータ特有の「記憶の署名」を極めて高い精度で識別する。Llama2やPythiaを用いた検証では、従来の最先端手法を大幅に上回る0.996のROC AUCを記録し、解釈性のための仕組みがプライバシーのリスクを増幅させている実態を浮き彫りにした。
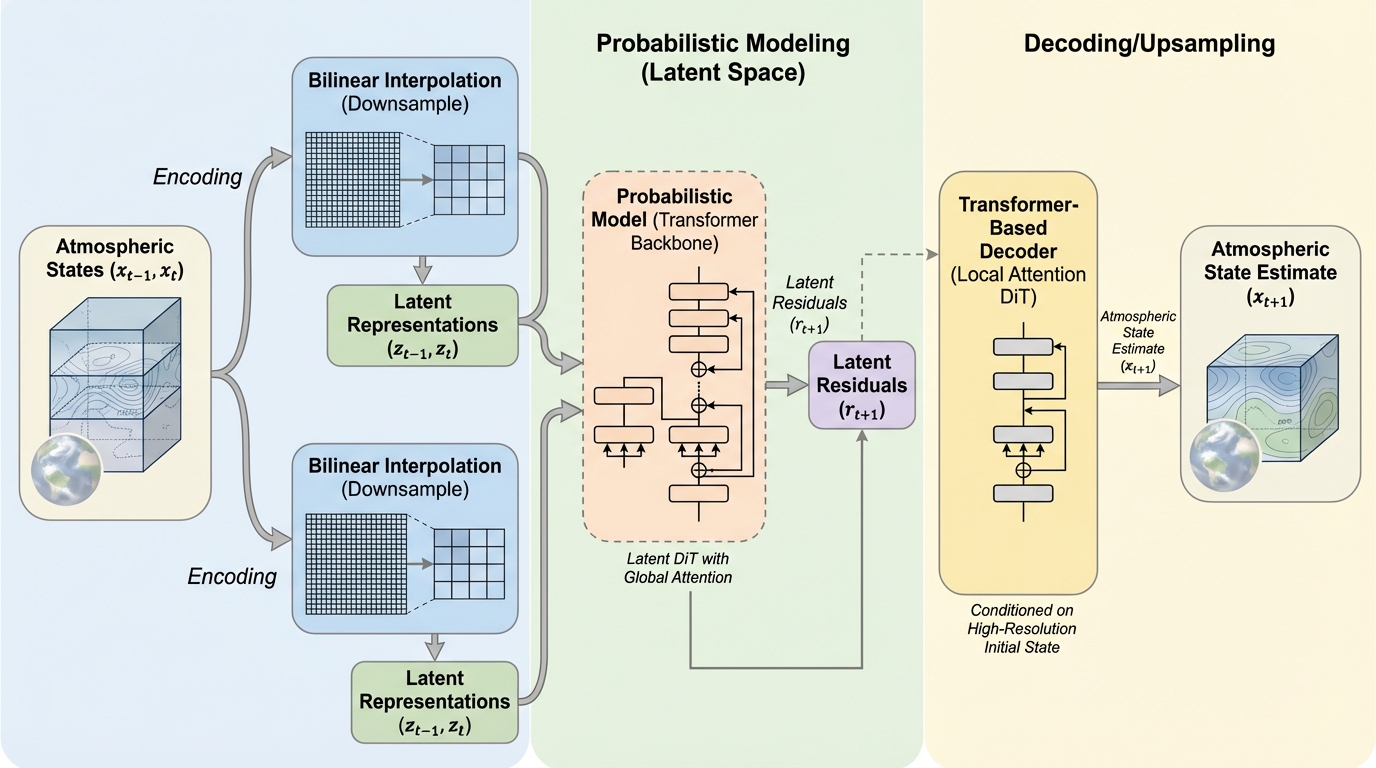
NVIDIAの研究チームは、複雑な専用アーキテクチャや特殊な学習手法を排除し、標準的なTransformerと潜在空間を活用した新しい気象予測フレームワーク「ATLAS」を開発した。 この手法は、双線形補間による単純なダウンサンプリングと潜在空間での残差予測を組み合わせることで、拡散モデルや確率的補間などの異なる確率的手法において一貫して高い精度を実現している。 ERA5データを用いた検証では、従来の数値予報システム(IFS)を大幅に上回り、既存の最先端深層学習モデルであるGenCastに対しても、多くの変数で統計的に有意な精度向上を達成した。
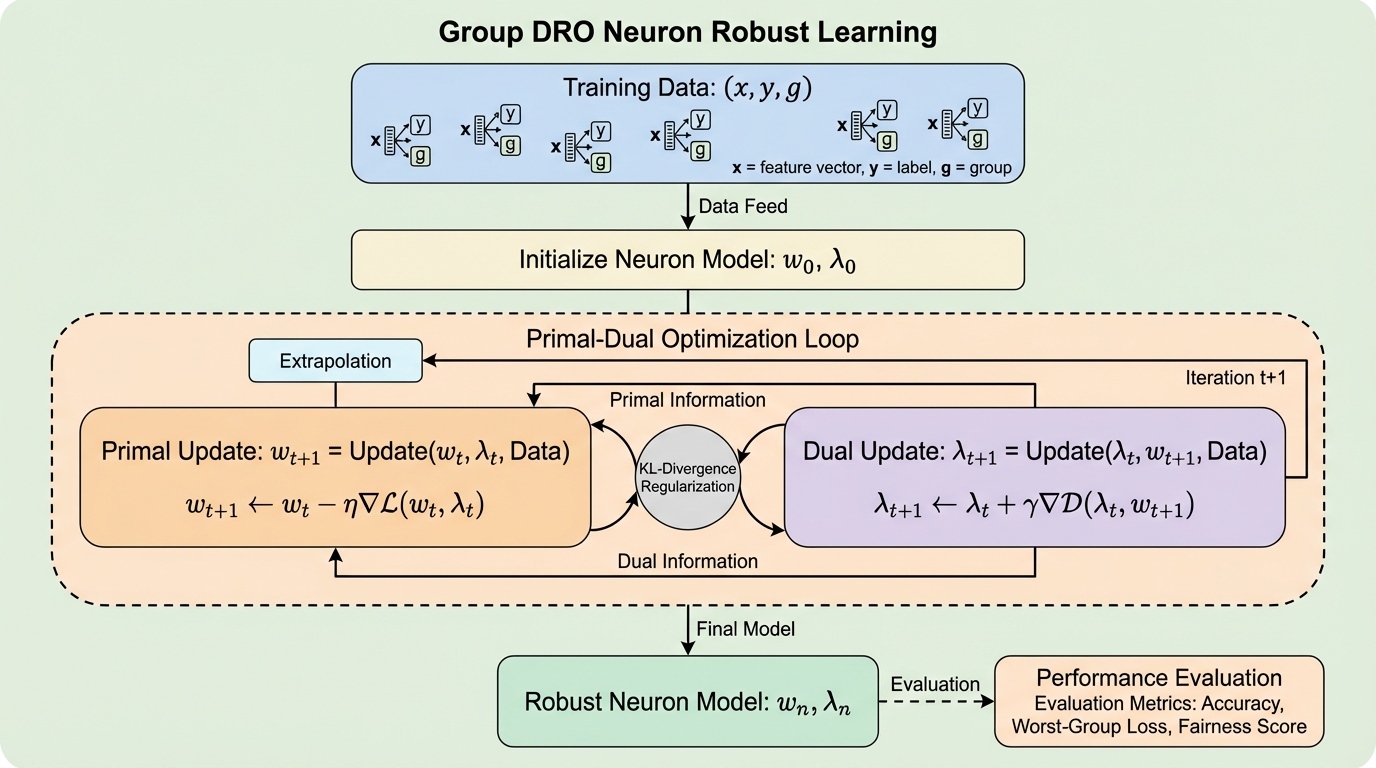
本研究は、任意のラベルノイズとグループ間の分布シフトが同時に存在する過酷な環境下で、単一ニューロンをロバストに学習するための新しいアルゴリズムを提案した。具体的には、複数のデータグループに対して最悪のケースを想定して損失を最小化するGroup DRO問題を、非凸な二乗誤差損失の設定で解くための効率的な主対偶アルゴリズムを開発している。 提案手法の核心は、高次元のモデル重みではなく低次元のグループ重み(双対変数)に対して外挿操作を行う点にあり、これによりメモリ効率を劇的に向上させつつ、理論的に最良のサンプル複雑性と定数倍の精度保証を達成した。大規模言語モデルの事前学習ベンチマークにおいてもその有効性が示唆されており、非凸最適化における分布ロバスト性の理論と実践の距離を縮める重要な成果である。 理論的な解析においては、従来の凸最適化に限定されていた保証を、ReLUなどの一般的な活性化関数を含む非凸な単一ニューロンの設定へと拡張することに成功した。特に、データの投影がサブ指数関数的な裾野を持つという仮定や、特定の領域で共分散行列が適切に条件付けられているという条件の下で、多項式時間での収束と、最悪のグループ重み付けに対する競争力のある性能を数学的に証明している。
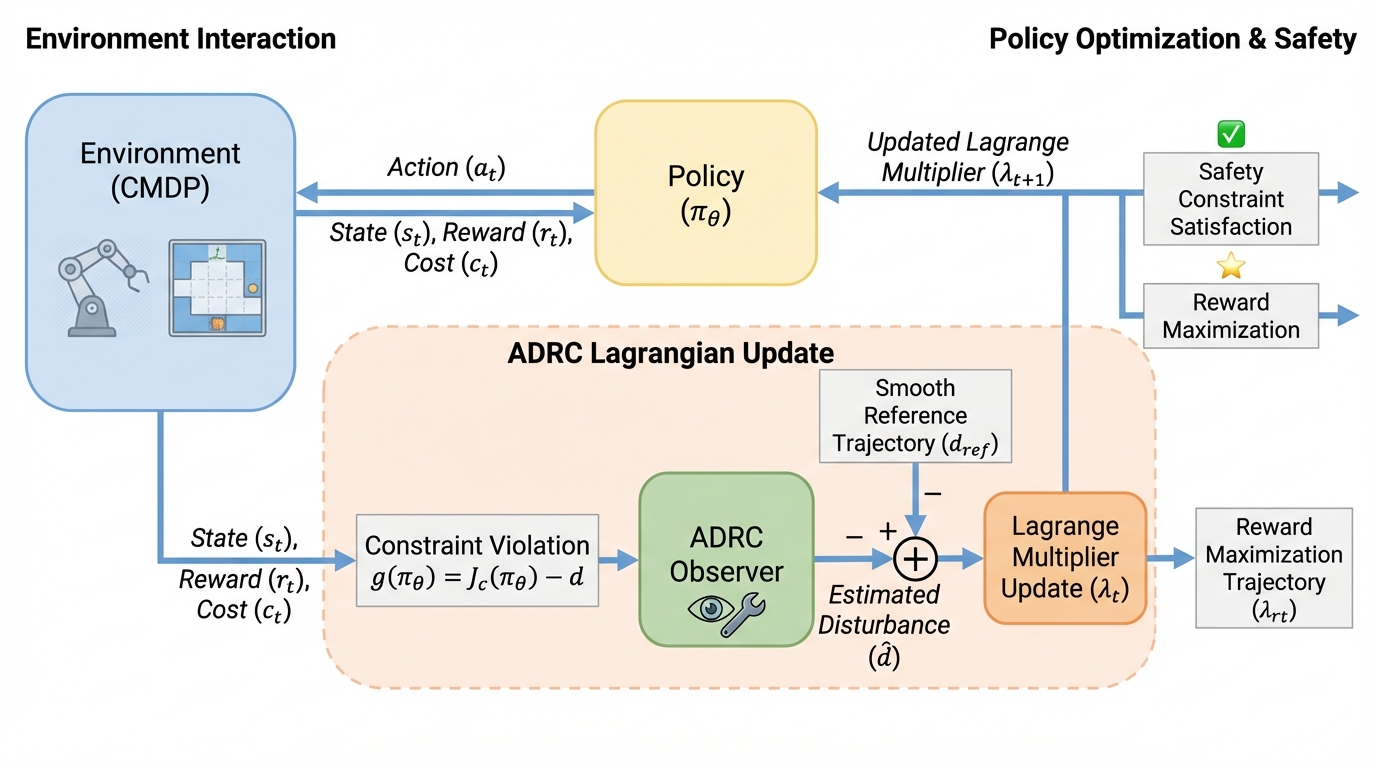
強化学習の安全性確保において、従来のラグランジュ法やPID法は学習の非定常性やノイズに起因する激しい振動と頻繁な制約違反という課題を抱えていたが、本研究は制御工学の能動的外乱抑圧制御(ADRC)を導入することで、学習中の不確実性を一括外乱としてリアルタイムに推定・相殺し、これを根本的に解決した。
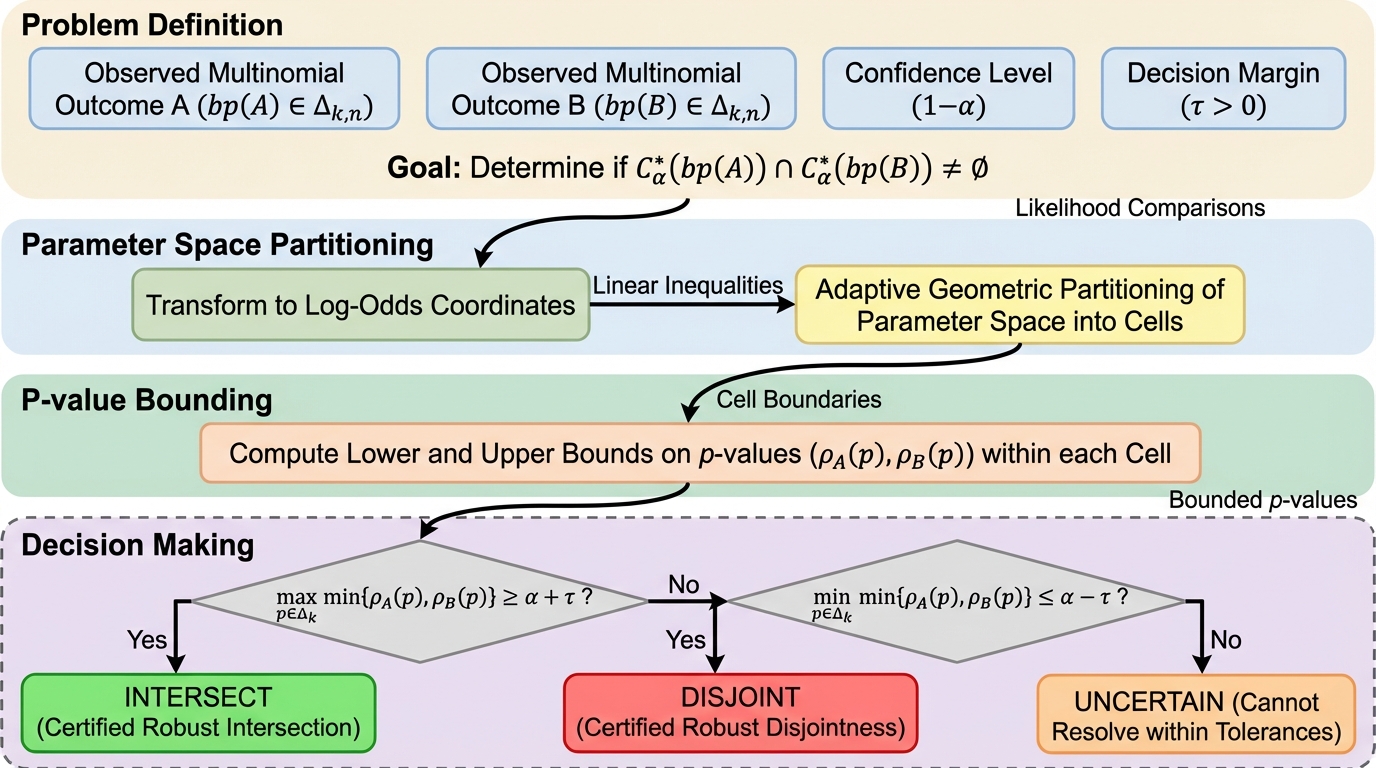
多項分布のパラメータ推定において、統計的に最適な最小体積信頼集合(MVC)は、その幾何学的形状が複雑で不連続であるため、実用的な計算が困難という課題がありました。 本研究は、対数オッズ座標系を用いることで尤度の順序関係を半空間の制約として捉え、適応的な幾何学的分割によって二つの観測結果の信頼集合が交差するかを厳密に判定するアルゴリズムを提案しました。 この手法は、従来の漸近近似では誤った結論を導きやすい小標本環境においても、交差、分離、または判定不能のいずれかを保証付きで出力し、A/Bテストや強化学習の精度向上に寄与します。
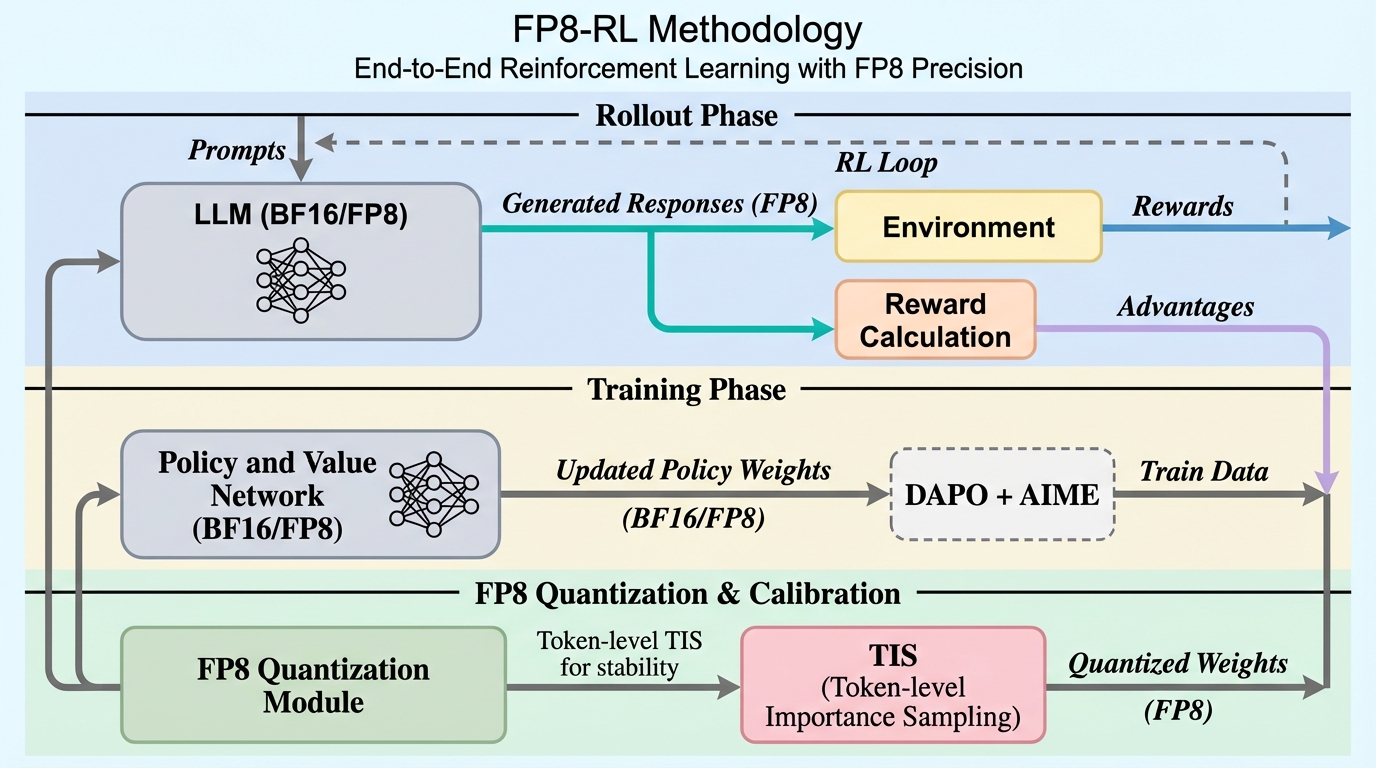
大規模言語モデルの強化学習において、実行時間の約8割を占めるロールアウト(生成)フェーズのボトルネックを解消するため、FP8精度を全面的に活用した計算スタック「FP8-RL」を提案しました。 ステップごとに更新されるポリシー重みの動的な量子化同期、KVキャッシュのFP8化、および重要度サンプリング(TIS/MIS)による不一致補正を導入することで、低精度化に伴う学習の不安定性を克服しています。 高密度モデルと混合専門家(MoE)モデルの両方で検証を行い、BF16と同等の学習性能を維持しながらロールアウトのスループットを最大44%向上させ、長文脈生成における計算効率を大幅に改善することに成功しました。