LLMからLRMへ:推論中心モデルにおけるプルーニングの再考
大規模言語モデル(LLM)の効率化に向けたプルーニング研究は、これまで指示追従型モデル(LLM-instruct)が中心であったが、本研究では長い思考プロセスを出力する推論中心型モデル(LLM-think/LRM)における有効性を初めて体系的に調査した。
TL;DR(結論)
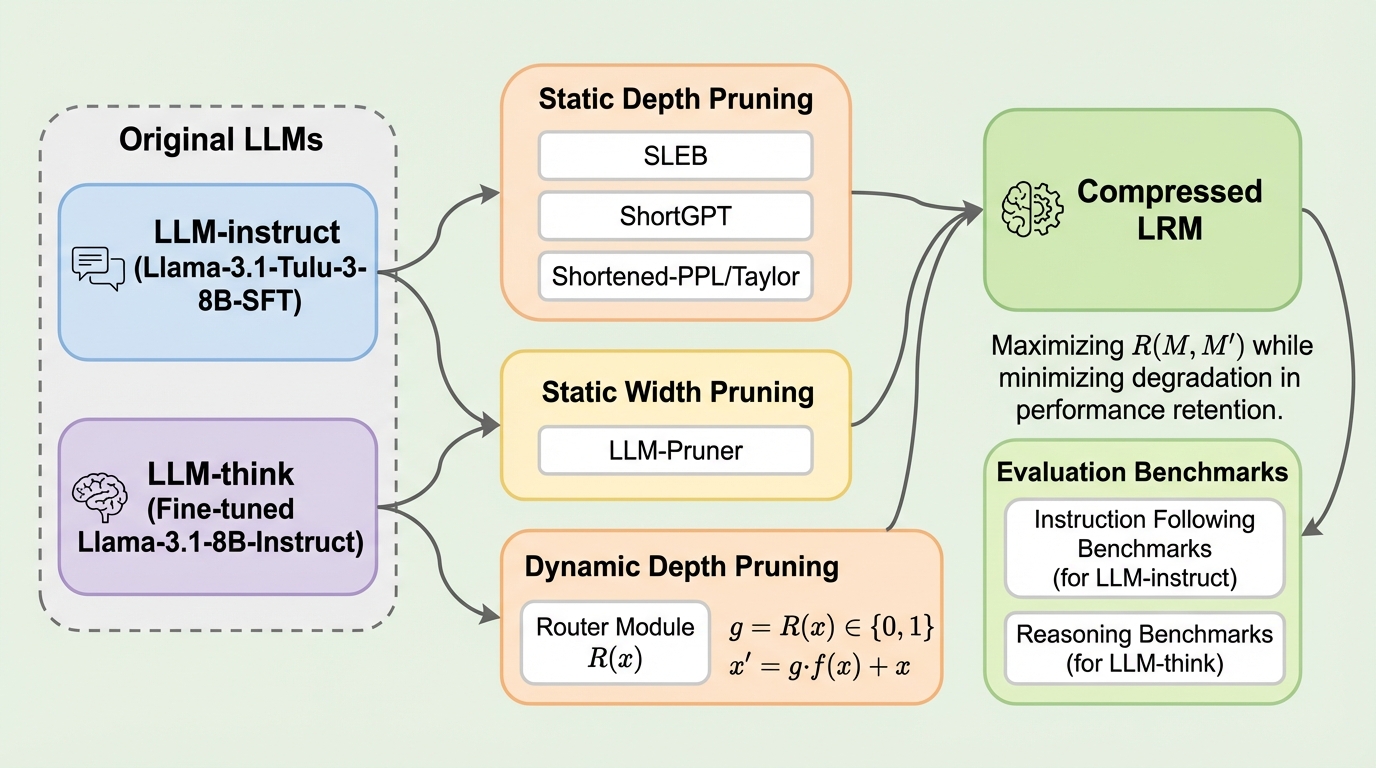
大規模言語モデル(LLM)の効率化に向けたプルーニング研究は、これまで指示追従型モデル(LLM-instruct)が中心であったが、本研究では長い思考プロセスを出力する推論中心型モデル(LLM-think/LRM)における有効性を初めて体系的に調査した。 実験の結果、プルーニング後の性能回復にはモデル本来の学習データ分布に合わせた調整が不可欠であり、一般的なコーパスを用いた場合、複雑な推論タスクでは性能がほぼ完全に崩壊する一方で、学習データを一致させることで高い性能を維持できることが判明した。 タスク特性による最適な戦略の違いも明らかになり、分類タスクでは層を削る静的深さプルーニングが有効な一方、生成や複雑な推論では次元を削る静的幅プルーニングが優れており、特に推論モデルにおいてはネットワークの深さが論理的整合性の維持に極めて重要である。
なぜこの問題か
大規模言語モデル(LLM)は自然言語処理の分野で目覚ましい進歩を遂げ、多様な領域で応用されているが、その驚異的な性能は膨大な計算コストの上に成り立っており、リソースが限られた環境での実用化において大きな障壁となっている。この課題を解決するために、モデルのパラメータを削減して効率化を図るプルーニング技術が広く採用されてきた。しかし、これまでのプルーニング研究のほとんどは、ユーザーの指示に対して直接的な回答を生成する指示追従型モデル(LLM-instruct)を主な対象としていた。一方で、現在のLLMの潮流は、最終的な回答を出す前に「思考の連鎖(CoT)」として知られる長い中間推論ステップを明示的に出力する推論中心型モデル(LLM-think、あるいはLRM)へとシフトしつつある。 LLM-thinkは、複雑な推論タスクにおいて優れた性能を発揮するが、その出力は数千トークンに及ぶこともあり、従来の指示追従型モデルとは内部的な挙動や出力特性が大きく異なると推測される。具体的には、推論型モデルは層を越えてより豊かな文脈情報を保持し、トークンレベルでのエントロピーが高い傾向にあることが先行研究で示唆されている。…
核心:何を提案したのか
本研究の核心は、プルーニングの影響を純粋に評価するために、キャリブレーション(調整)およびリカバリ(回復)に使用するデータを、各モデルの元の学習分布と厳密に一致させる「制御された実験設定」を導入したことにある。従来の研究では、プルーニング後の性能回復に用いるデータセットの選択が恣意的であり、一般的なコーパスや指示チューニングデータが混在して使用されていた。このようなデータの不一致は、プルーニング自体の効果と、学習データの分布のズレによる影響を混同させる要因となる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related