FP8-RL:LLM強化学習のための実用的かつ安定した低精度スタック
大規模言語モデルの強化学習において、実行時間の約8割を占めるロールアウト(生成)フェーズのボトルネックを解消するため、FP8精度を全面的に活用した計算スタック「FP8-RL」を提案しました。 ステップごとに更新されるポリシー重みの動的な量子化同期、KVキャッシュのFP8化、および重要度サンプリング(TIS/MIS)による不一致補正を導入することで、低精度化に伴う学習の不安定性を克服しています。 高密度モデルと混合専門家(MoE)モデルの両方で検証を行い、BF16と同等の学習性能を維持しながらロールアウトのスループットを最大44%向上させ、長文脈生成における計算効率を大幅に改善することに成功しました。
TL;DR(結論)
大規模言語モデルの強化学習において、実行時間の約8割を占めるロールアウト(生成)フェーズのボトルネックを解消するため、FP8精度を全面的に活用した計算スタック「FP8-RL」を提案しました。 ステップごとに更新されるポリシー重みの動的な量子化同期、KVキャッシュのFP8化、および重要度サンプリング(TIS/MIS)による不一致補正を導入することで、低精度化に伴う学習の不安定性を克服しています。 高密度モデルと混合専門家(MoE)モデルの両方で検証を行い、BF16と同等の学習性能を維持しながらロールアウトのスループットを最大44%向上させ、長文脈生成における計算効率を大幅に改善することに成功しました。
なぜこの問題か
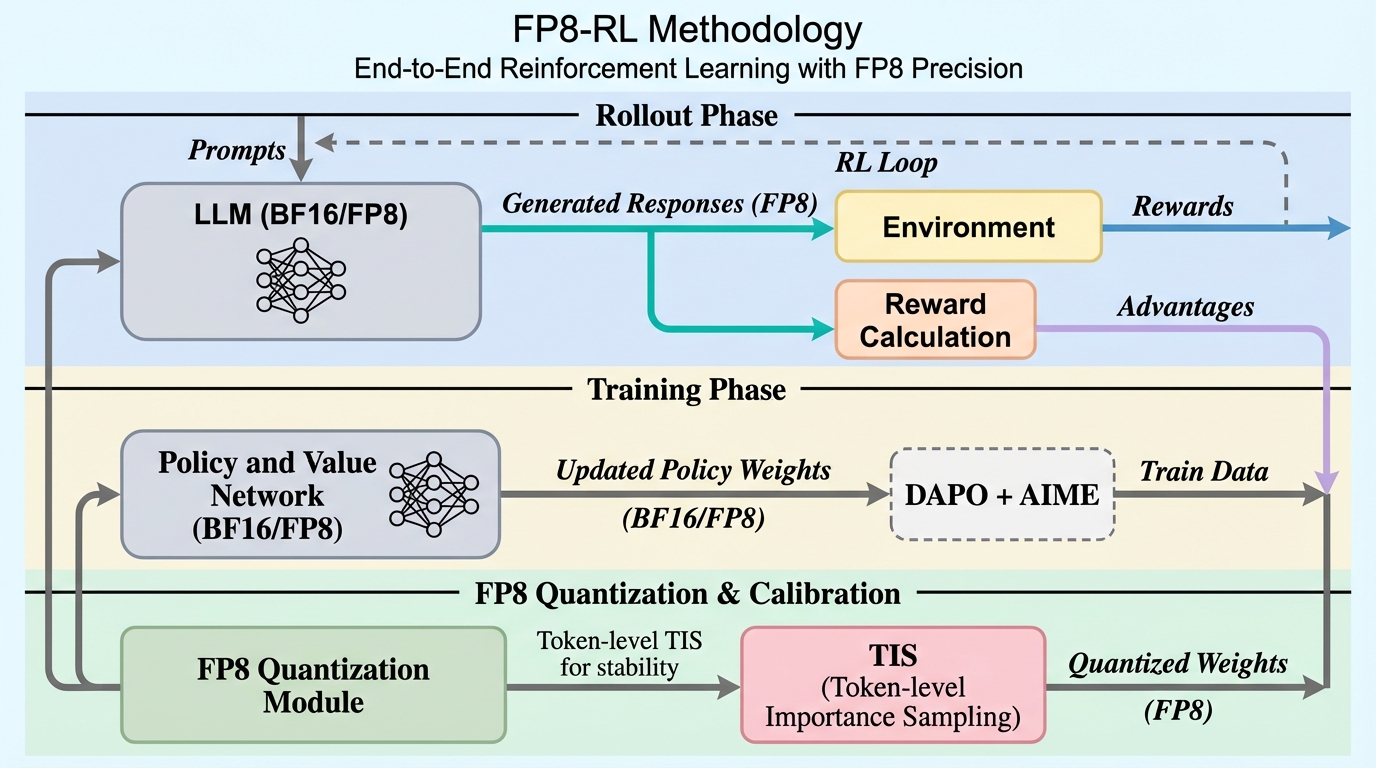
大規模言語モデル(LLM)の強化学習(RL)は、事前学習や教師あり微調整(SFT)とは異なる特有のシステム上の課題を抱えています。強化学習の最適化プロセスでは、各ステップにおいて現在のポリシーを用いて新しい応答を生成する「ロールアウト」フェーズが必要不可欠ですが、このフェーズが全実行時間の大部分を占めることが大きな問題となっています。先行研究の分析によれば、同期的なLLM強化学習の設定において、ロールアウトフェーズは全反復時間の約80%を消費していることが報告されています。このため、ロールアウトの高速化は、強化学習全体の効率を向上させ、実験サイクルを短縮するための最も直接的かつ効果的な手段となります。しかし、推論において普及しつつあるFP8低精度演算を強化学習に適用するには、特有の技術的・アルゴリズム的課題が存在します。 第一に、強化学習ではポリシーの重みがステップごとに更新されるため、推論エンジンに対して頻繁な量子化と重みの同期を行う必要があり、エンジニアリング上の負担が非常に大きくなります。…
核心:何を提案したのか
本研究では、LLMの強化学習におけるロールアウトを高速化するための実用的なFP8計算スタック「FP8-RL」を提案しました。このスタックは、veRLエコシステム内に実装されており、FSDPやMegatron-LMといった主要な学習バックエンド、およびvLLMやSGLangといった高度な推論エンジンをサポートしています。提案手法の核心は、単に計算を低精度化するだけでなく、強化学習特有の動的な性質に対応するための包括的なワークフローを構築した点にあります。具体的には、線形層に対するブロック単位のFP8 W8A8量子化、長文脈生成時のメモリボトルネックを解消するためのKVキャッシュのFP8量子化、そして低精度化によるポリシーの乖離を補正する重要度サンプリングベースのアルゴリズムを統合しています。 これにより、モデルの重みが頻繁に更新される環境下でも、安定してFP8の恩恵を享受することが可能となりました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related