DRPG(分解・検索・計画・生成):学術的な反論のためのエージェントフレームワーク
学術論文の査読に対する反論(リバッタル)を自動生成するため、査読コメントの分解、関連情報の検索、反論戦略の計画、そして最終的な回答生成という4つの段階を踏むエージェントフレームワーク「DRPG」が開発されました。
TL;DR(結論)
学術論文の査読に対する反論(リバッタル)を自動生成するため、査読コメントの分解、関連情報の検索、反論戦略の計画、そして最終的な回答生成という4つの段階を踏むエージェントフレームワーク「DRPG」が開発されました。この手法は、従来の言語モデルが抱えていた長大な論文内容の把握漏れや、説得力に欠ける一般的な回答しか生成できないという課題を、論文の内容に基づいた最適な反論の方向性を98%以上の精度で特定する「プランナー」モジュールの導入によって解決しています。大規模な実験の結果、DRPGは既存のパイプライン手法を大幅に上回る性能を示し、わずか8Bパラメータの小規模なモデルを用いながらも、実際の人間が作成した反論の平均的な質を超える高い評価を得ることに成功しました。これにより、著者の負担を大幅に軽減し、学術的な議論の質を向上させる可能性が示されています。
なぜこの問題か
学術研究のサイクルにおいて、大規模言語モデル(LLM)はアイデアの生成や論文の執筆、さらには査読のシミュレーションなど、多岐にわたる段階で活用され始めています。しかし、著者と査読者が意見を交わす「反論(リバッタル)」のプロセスを自動で支援する試みは、その重要性にもかかわらず、これまで十分に探索されてきませんでした。査読プロセスは論文の公平性と客観性を担保するために不可欠なものですが、近年のコンピュータサイエンス分野の爆発的な拡大に伴い、著者が質の高い反論を準備するための負担は増大の一途をたどっています。例えば、NeurIPSやICLRといった主要な国際会議では、2025年に25,000件を超える投稿が行われており、著者と査読者の間のコミュニケーションを効率化する仕組みが切実に求められています。 しかし、学術的な反論を自動化することには大きな困難が伴います。反論は、正確な理解、説得力のある論証、そして高度な専門知識が要求される「対抗的なマルチエージェント・シナリオ」という特殊な性質を持っているからです。既存の言語モデルをそのまま使用したり、単純な処理手順を構築したりするだけでは、いくつかの致命的な問題が発生します。…
核心:何を提案したのか
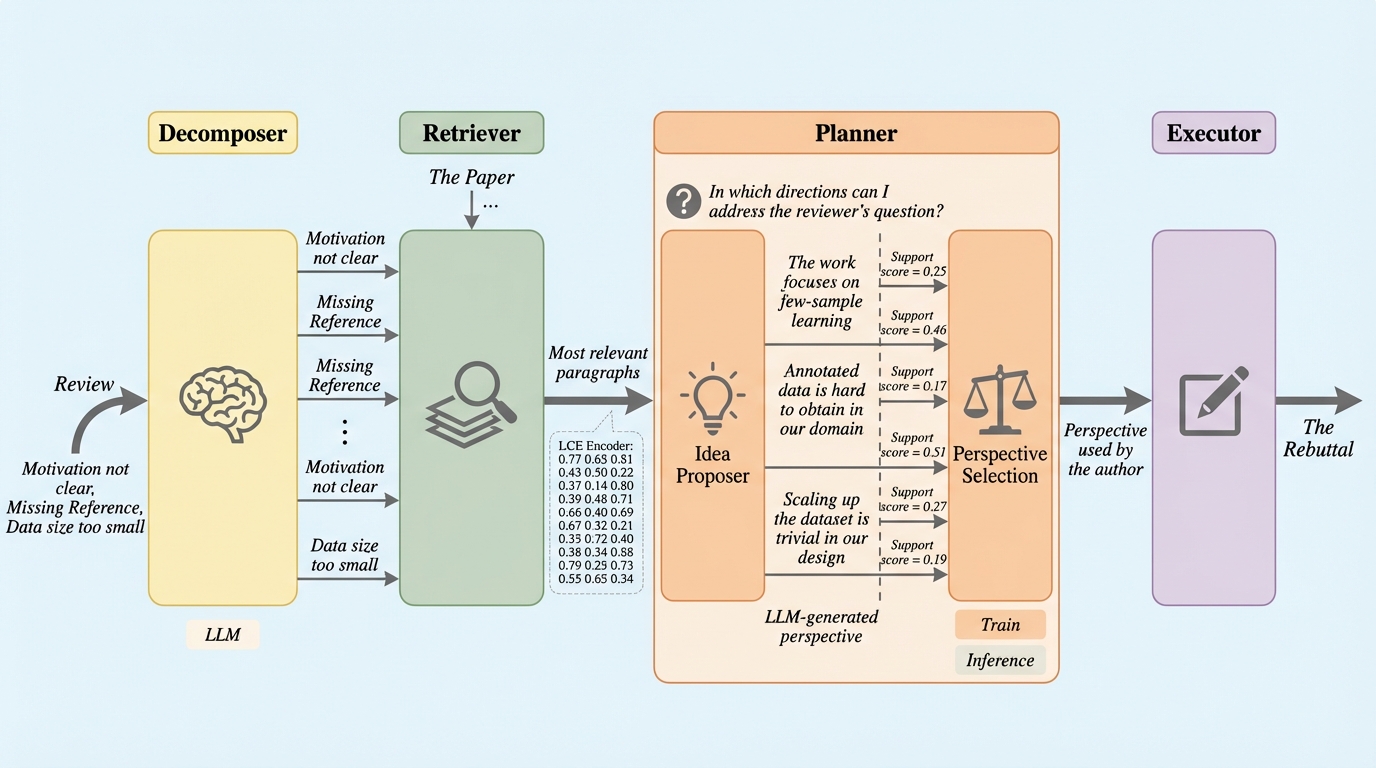
本研究では、高品質な学術的反論を自動生成するための4段階のエージェントフレームワーク「DRPG(Decompose, Retrieve, Plan, Generate)」を提案しています。このフレームワークの核心は、複雑な査読コメントを管理可能な最小単位の論点に分解し、それぞれの論点に対して論文内の最も関連性の高い証拠を紐付けた上で、最適な反論の方向性を戦略的に決定する点にあります。特に、生成の前に「計画(Planner)」の工程を挟むことで、単に論文の内容を繰り返すのではなく、査読者の意図を汲み取った効果的な反論を可能にしています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related