AttenMIA:アテンションシグナルを通じたLLMメンバーシップ推論攻撃
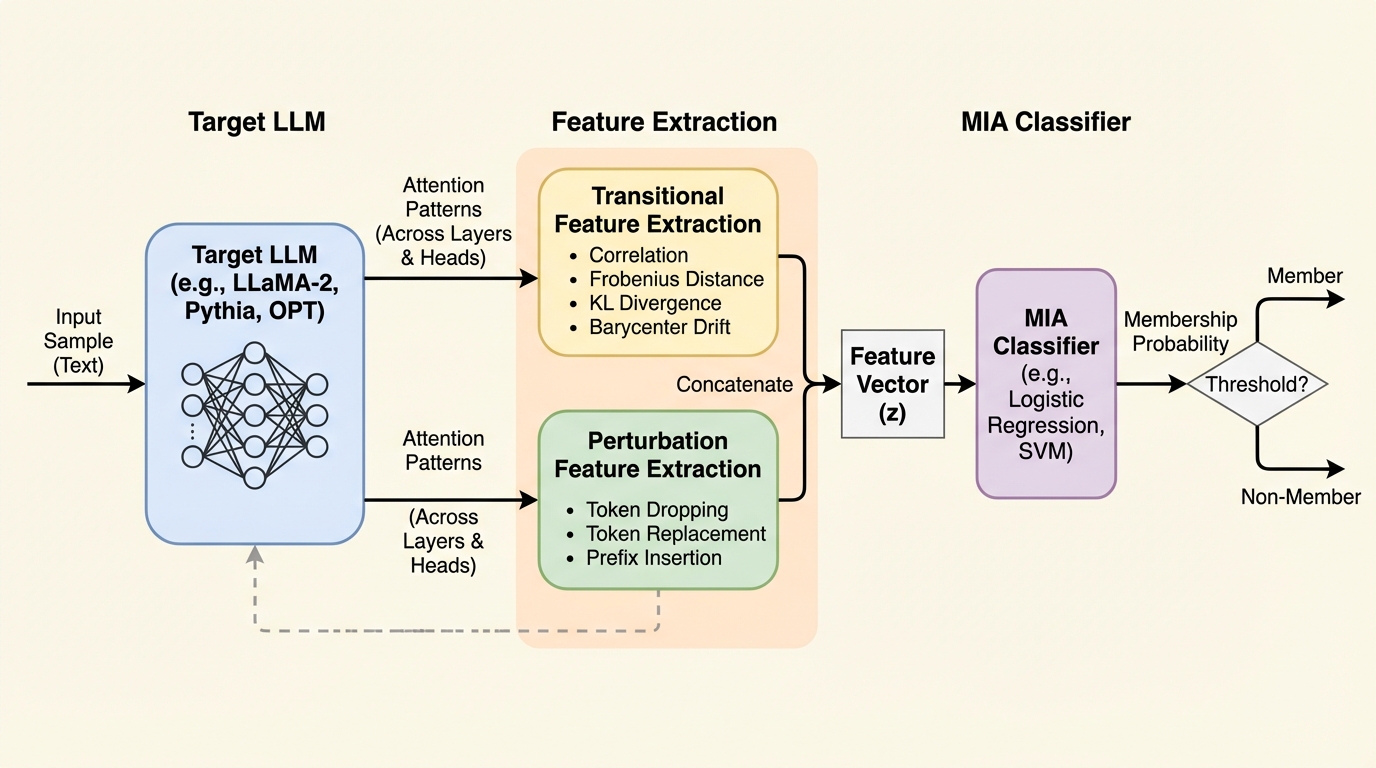
大規模言語モデル(LLM)が学習データを記憶する性質を悪用し、特定のデータが学習セットに含まれていたかを判定する新しいメンバーシップ推論攻撃(MIA)手法「AttenMIA」が開発された。この手法は、従来の出力スコアに頼る方法とは異なり、トランスフォーマー内部の自己注意(アテンション)パターンの層間遷移や、入力への微小な摂動に対する反応を分析することで、学習済みデータ特有の「記憶の署名」を極めて高い精度で識別する。Llama2やPythiaを用いた検証では、従来の最先端手法を大幅に上回る0.996のROC AUCを記録し、解釈性のための仕組みがプライバシーのリスクを増幅させている実態を浮き彫りにした。
TL;DR(結論)
大規模言語モデル(LLM)が学習データを記憶する性質を悪用し、特定のデータが学習セットに含まれていたかを判定する新しいメンバーシップ推論攻撃(MIA)手法「AttenMIA」が開発された。この手法は、従来の出力スコアに頼る方法とは異なり、トランスフォーマー内部の自己注意(アテンション)パターンの層間遷移や、入力への微小な摂動に対する反応を分析することで、学習済みデータ特有の「記憶の署名」を極めて高い精度で識別する。Llama2やPythiaを用いた検証では、従来の最先端手法を大幅に上回る0.996のROC AUCを記録し、解釈性のための仕組みがプライバシーのリスクを増幅させている実態を浮き彫りにした。
なぜこの問題か
大規模言語モデル(LLM)は、対話アシスタントやコーディング支援、バイオ医学研究など、現実世界の多様なアプリケーションに不可欠な要素となっている。これらのモデルは膨大なデータセットを用いて学習されることで高い汎用性を獲得するが、その一方で学習データをそのまま記憶してしまう「メモライゼーション」という現象が報告されている。この特性は、個人のプライバシー侵害や、データセットに含まれる知的財産の漏洩といった深刻なセキュリティ上の懸念を引き起こす。特定のデータサンプルがモデルの学習セットに含まれていたかどうかを判定するメンバーシップ推論攻撃(MIA)は、こうしたプライバシーのリスクを評価し、データの機密性を脅かす重要な脅威である。 既存のLLM向けMIA手法の多くは、モデルが出力する確信度スコア、対数尤度、パープレキシティ、あるいはトークンレベルの損失値といった「出力ベース」の信号に依存している。しかし、これらの手法には二つの大きな限界がある。第一に、学習済みサンプル(メンバー)と未学習サンプル(ノンメンバー)の決定境界においてスコアが重なりやすく、特に誤検知を低く抑える必要がある実用的なシナリオでは性能が著しく低下する。…
核心:何を提案したのか
本研究では、トランスフォーマー内部の自己注意パターンを直接利用してメンバーシップを推論する、初のホワイトボックス型フレームワーク「AttenMIA」を提案している。この手法の核心的な洞察は、自己注意パターンが情報の流れを促進するだけでなく、モデルの記憶に関する微細かつ系統的な署名をエンコードしているという点にある。研究チームは、学習済みサンプルはモデル内部でより構造化され、集中したアテンションパターンを誘発し、その信号は層やヘッドを横断して持続するという仮説を立てた。 AttenMIAは、単にアテンションの値を観察するだけでなく、トランスフォーマー独自のマルチヘッド構造を活用し、層間の変化率に基づいた詳細なプライバシー信号を追跡する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related