ADRCラグランジュ法による強化学習における安全性の向上
強化学習の安全性確保において、従来のラグランジュ法やPID法は学習の非定常性やノイズに起因する激しい振動と頻繁な制約違反という課題を抱えていたが、本研究は制御工学の能動的外乱抑圧制御(ADRC)を導入することで、学習中の不確実性を一括外乱としてリアルタイムに推定・相殺し、これを根本的に解決した。
TL;DR(結論)
強化学習の安全性確保において、従来のラグランジュ法やPID法は学習の非定常性やノイズに起因する激しい振動と頻繁な制約違反という課題を抱えていたが、本研究は制御工学の能動的外乱抑圧制御(ADRC)を導入することで、学習中の不確実性を一括外乱としてリアルタイムに推定・相殺し、これを根本的に解決した。 提案手法は、拡張状態観測器(ESO)による外乱の動的な補償と、現在のコストから目標閾値までを滑らかに誘導する参照軌道設計を組み合わせることで、既存のラグランジュ法やPID法を数学的な特殊例として包含しつつ、複雑な動的環境下でも極めて高い頑健性と安定した制約遵守能力を実現する統一的な枠組みである。 広範なベンチマーク実験の結果、既存手法と比較して安全違反率を最大74%、違反規模を89%、平均コストを67%削減することに成功し、自動運転やロボット制御のような実世界のタスクにおいて、報酬性能を損なうことなく極めて高い信頼性を持って安全制約を維持できることを実証した。
なぜこの問題か
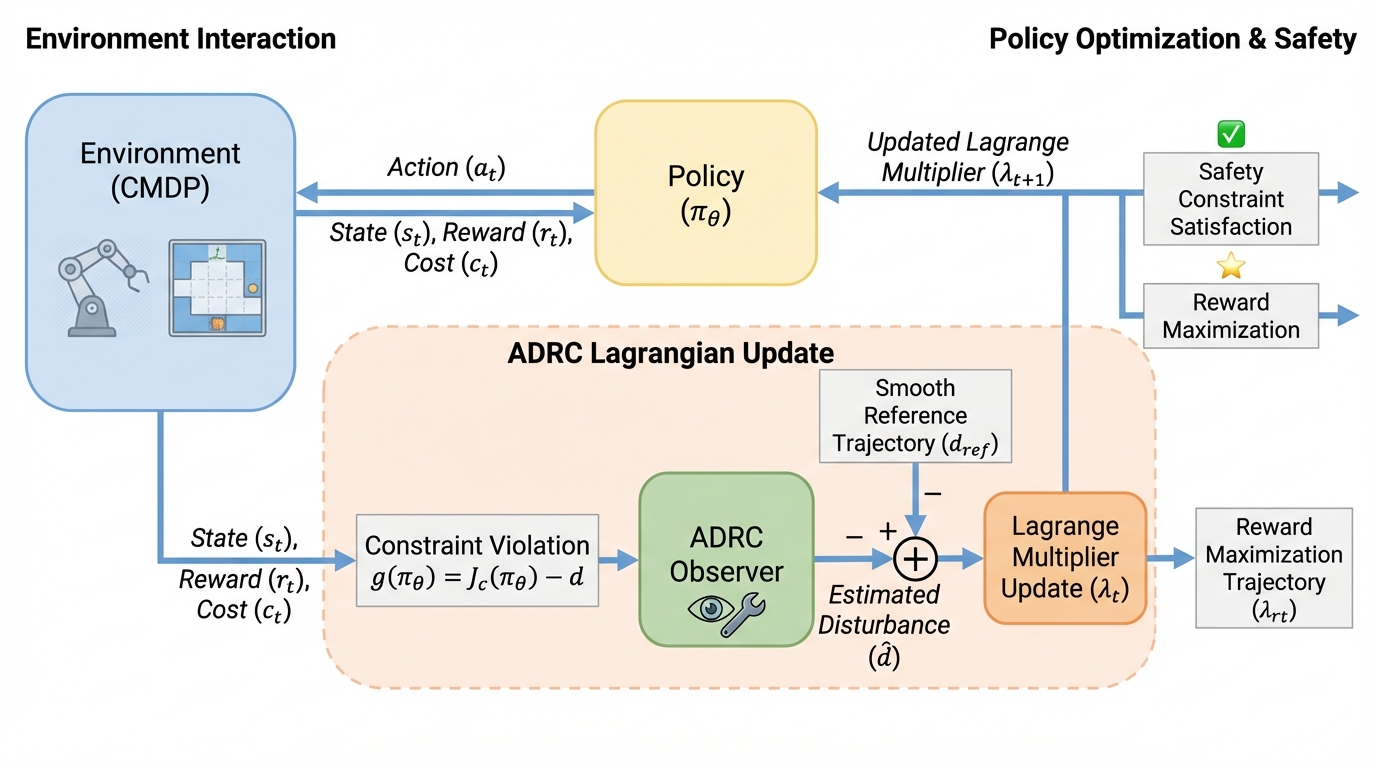
安全な強化学習(Safe RL)は、エージェントが未知の環境で報酬を最大化しつつ、あらかじめ定義された安全制約を厳格に守ることを目的としている。この問題は通常、制約付きマルコフ決定過程(CMDP)として定式化され、ラグランジュ法を用いて制約付き最適化問題を解くアプローチが一般的である。しかし、従来のラグランジュ更新には深刻な制御上の課題が存在する。古典的なラグランジュ更新は、制約違反信号に対する純粋な積分制御(I制御)として機能するが、強化学習のプロセスは本質的に非定常である。方策が更新されるたびにデータの分布が変化し、コスト推定には統計的なノイズが混入するため、積分制御だけでは環境の変化に対して反応が遅れてしまう。この「位相の遅れ」は、制約閾値付近での激しいオーバーシュートや持続的な振動を引き起こし、結果として頻繁な安全違反を招く原因となっている。 この振動問題を解決するために、比例項や微分項を追加したPIDラグランジュ法も提案されているが、これにも限界がある。PID制御はパラメータ感度が極めて高く、比例・積分・微分の各ゲインをタスクごとに精密にチューニングしなければならない。…
核心:何を提案したのか
本研究の核心的な提案は、制御工学の分野で高い堅牢性が認められている「能動的外乱抑圧制御(ADRC)」の思想を、強化学習のラグランジュ更新プロセスに統合したことである。ADRCは、システムのモデル誤差、外部からのノイズ、および学習に伴う非定常性をすべて「一括外乱」として定義し、これをリアルタイムで推定して動的に相殺する手法である。本研究では、このADRCをSafe RLの枠組みに適合させるために、拡張状態観測器(ESO)を導入した。ESOは、観測可能なコスト信号のみを用いて、システムに影響を与えている未知の外乱を逐次的に推定する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related