Group DROニューロンのロバスト学習
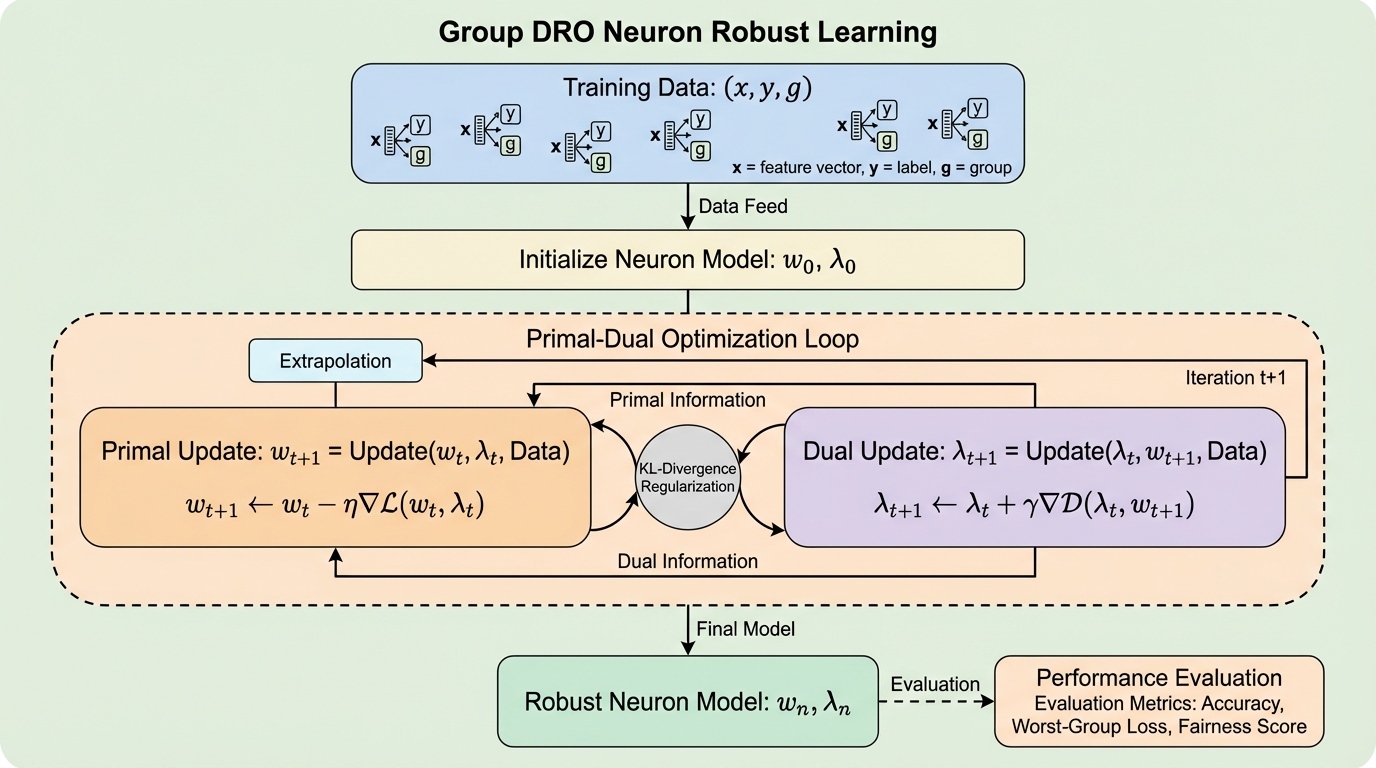
本研究は、任意のラベルノイズとグループ間の分布シフトが同時に存在する過酷な環境下で、単一ニューロンをロバストに学習するための新しいアルゴリズムを提案した。具体的には、複数のデータグループに対して最悪のケースを想定して損失を最小化するGroup DRO問題を、非凸な二乗誤差損失の設定で解くための効率的な主対偶アルゴリズムを開発している。 提案手法の核心は、高次元のモデル重みではなく低次元のグループ重み(双対変数)に対して外挿操作を行う点にあり、これによりメモリ効率を劇的に向上させつつ、理論的に最良のサンプル複雑性と定数倍の精度保証を達成した。大規模言語モデルの事前学習ベンチマークにおいてもその有効性が示唆されており、非凸最適化における分布ロバスト性の理論と実践の距離を縮める重要な成果である。 理論的な解析においては、従来の凸最適化に限定されていた保証を、ReLUなどの一般的な活性化関数を含む非凸な単一ニューロンの設定へと拡張することに成功した。特に、データの投影がサブ指数関数的な裾野を持つという仮定や、特定の領域で共分散行列が適切に条件付けられているという条件の下で、多項式時間での収束と、最悪のグループ重み付けに対する競争力のある性能を数学的に証明している。
TL;DR(結論)
本研究は、任意のラベルノイズとグループ間の分布シフトが同時に存在する過酷な環境下で、単一ニューロンをロバストに学習するための新しいアルゴリズムを提案した。具体的には、複数のデータグループに対して最悪のケースを想定して損失を最小化するGroup DRO問題を、非凸な二乗誤差損失の設定で解くための効率的な主対偶アルゴリズムを開発している。 提案手法の核心は、高次元のモデル重みではなく低次元のグループ重み(双対変数)に対して外挿操作を行う点にあり、これによりメモリ効率を劇的に向上させつつ、理論的に最良のサンプル複雑性と定数倍の精度保証を達成した。大規模言語モデルの事前学習ベンチマークにおいてもその有効性が示唆されており、非凸最適化における分布ロバスト性の理論と実践の距離を縮める重要な成果である。 理論的な解析においては、従来の凸最適化に限定されていた保証を、ReLUなどの一般的な活性化関数を含む非凸な単一ニューロンの設定へと拡張することに成功した。特に、データの投影がサブ指数関数的な裾野を持つという仮定や、特定の領域で共分散行列が適切に条件付けられているという条件の下で、多項式時間での収束と、最悪のグループ重み付けに対する競争力のある性能を数学的に証明している。
なぜこの問題か
現代の機械学習において、訓練データとテストデータの分布が異なる「分布シフト」は、モデルの信頼性を損なう深刻な課題である。特に、データが複数の異なる属性やドメイン(グループ)から構成されている場合、特定のグループにおいて極端に精度が低下する現象が頻発する。この問題に対処するため、グループごとの損失の最大値を最小化するGroup DROという枠組みが注目されており、大規模言語モデルのドメイン重み付け調整などで成果を上げている。しかし、既存のGroup DROの理論的保証の多くは、目的関数が凸である場合に限定されていた。実際の深層学習で直面する最適化問題は非凸であり、理論と実践の間には依然として大きな隔たりが存在している。 単一ニューロンの学習は、深層学習の最も基本的な構成要素でありながら、二乗誤差損失を用いると非凸な性質を持つため、計算量的に困難な問題として知られている。特に、ReLUやシグモイドといった一般的な活性化関数を用いる場合、ラベルに任意のノイズが含まれる「不可知論的学習」の設定では、多項式時間で最適解を得ることはNP困難であるという報告もある。…
核心:何を提案したのか
本研究の核心は、任意のラベルノイズとグループ単位の分布シフトが存在する条件下で、単一ニューロンをロバストに学習するための、計算効率に優れた新しい主対偶アルゴリズムを提案したことにある。このアルゴリズムは、K個の異なる分布から得られるサンプルにアクセスできる状況を想定し、それらの凸結合として表される最悪のグループ重み付けに対して、二乗誤差損失を最小化する重みベ…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related