言語生成におけるノイズの影響の定量化
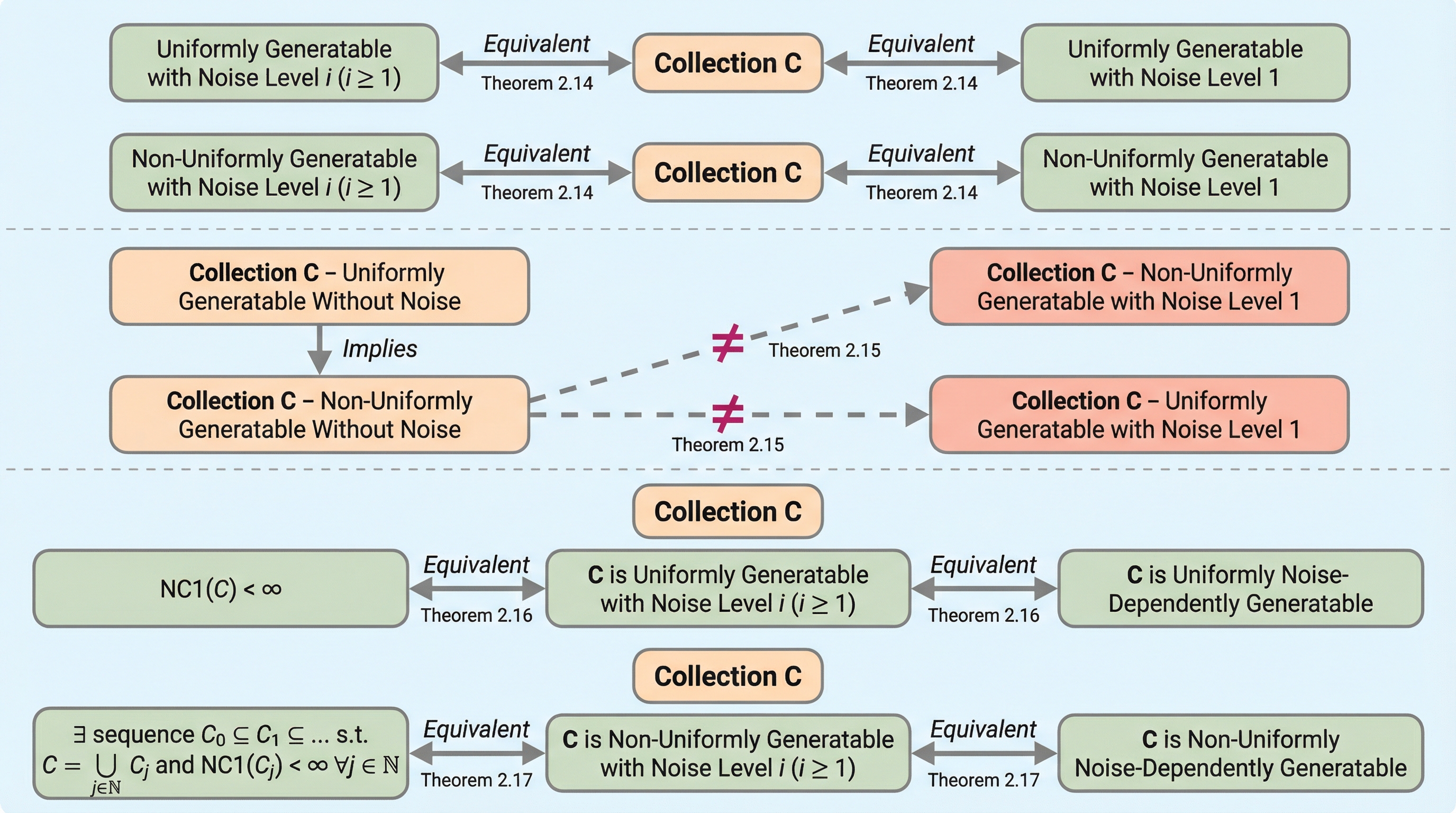
本研究は、言語モデルの生成能力が訓練データに含まれる有限個のノイズから受ける影響を理論的に解明し、クリーンなデータとわずか1つのノイズの間には生成可能な言語集合の厳密な減少を伴う決定的な断絶があることを数学的に証明した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究は、言語モデルの生成能力が訓練データに含まれる有限個のノイズから受ける影響を理論的に解明し、クリーンなデータとわずか1つのノイズの間には生成可能な言語集合の厳密な減少を伴う決定的な断絶があることを数学的に証明した。
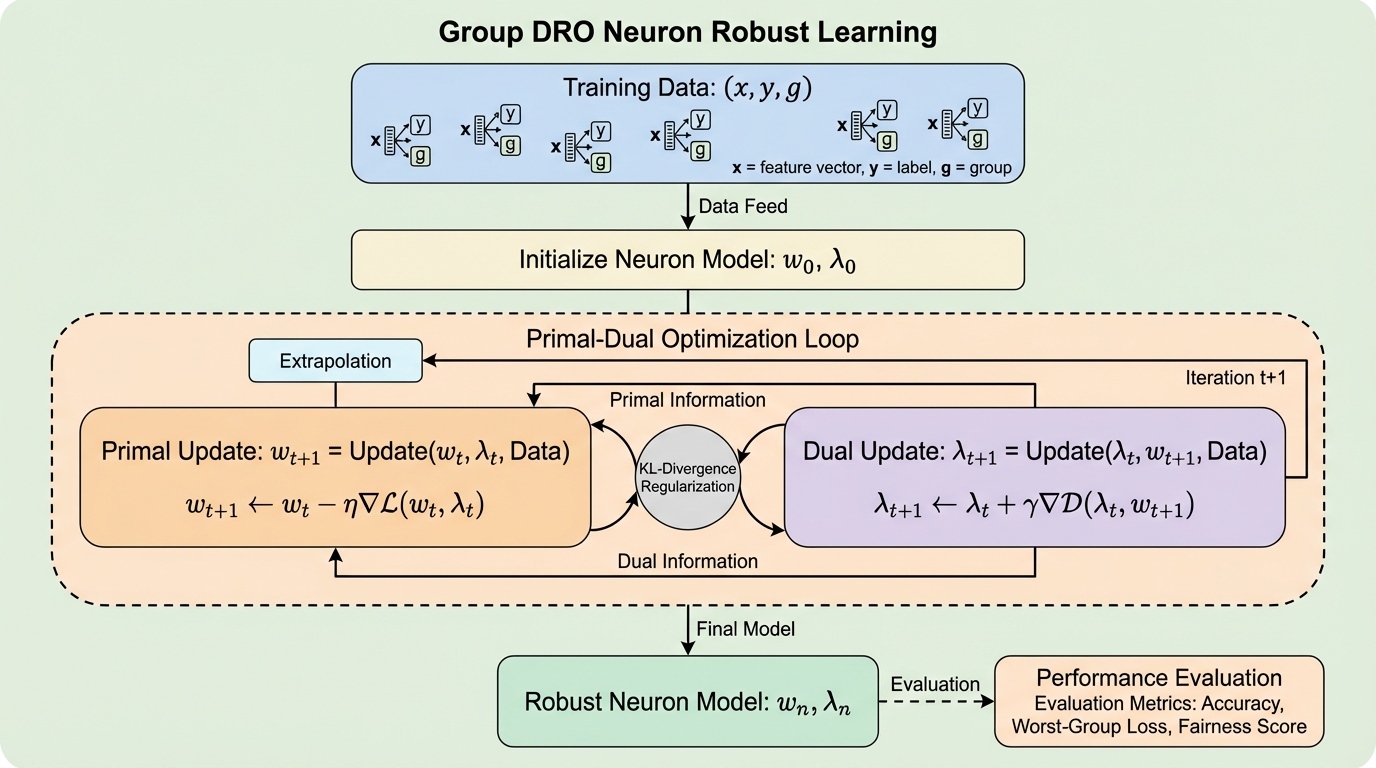
本研究は、任意のラベルノイズとグループ間の分布シフトが同時に存在する過酷な環境下で、単一ニューロンをロバストに学習するための新しいアルゴリズムを提案した。具体的には、複数のデータグループに対して最悪のケースを想定して損失を最小化するGroup DRO問題を、非凸な二乗誤差損失の設定で解くための効率的な主対偶アルゴリズムを開発している。 提案手法の核心は、高次元のモデル重みではなく低次元のグループ重み(双対変数)に対して外挿操作を行う点にあり、これによりメモリ効率を劇的に向上させつつ、理論的に最良のサンプル複雑性と定数倍の精度保証を達成した。大規模言語モデルの事前学習ベンチマークにおいてもその有効性が示唆されており、非凸最適化における分布ロバスト性の理論と実践の距離を縮める重要な成果である。 理論的な解析においては、従来の凸最適化に限定されていた保証を、ReLUなどの一般的な活性化関数を含む非凸な単一ニューロンの設定へと拡張することに成功した。特に、データの投影がサブ指数関数的な裾野を持つという仮定や、特定の領域で共分散行列が適切に条件付けられているという条件の下で、多項式時間での収束と、最悪のグループ重み付けに対する競争力のある性能を数学的に証明している。
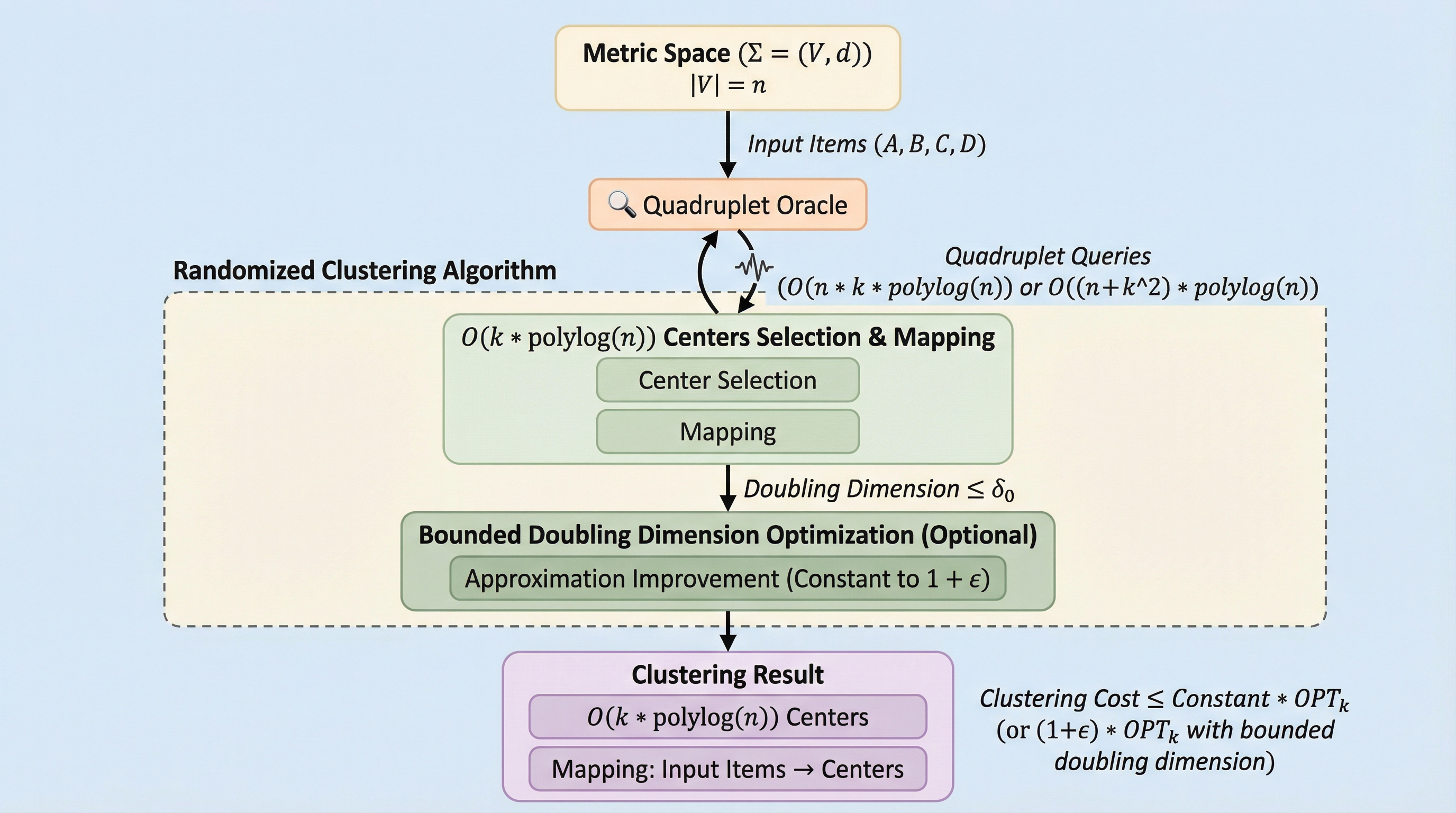
従来の$k$-クラスタリング手法が正確な距離情報を必要とするのに対し、本研究では2つのペアの距離の大小を比較する「4点オラクル」のみを利用するランクモデル(R-model)において、ノイズを含む条件下でも効率的に動作する新しいランダム化アルゴリズムを提案しました。
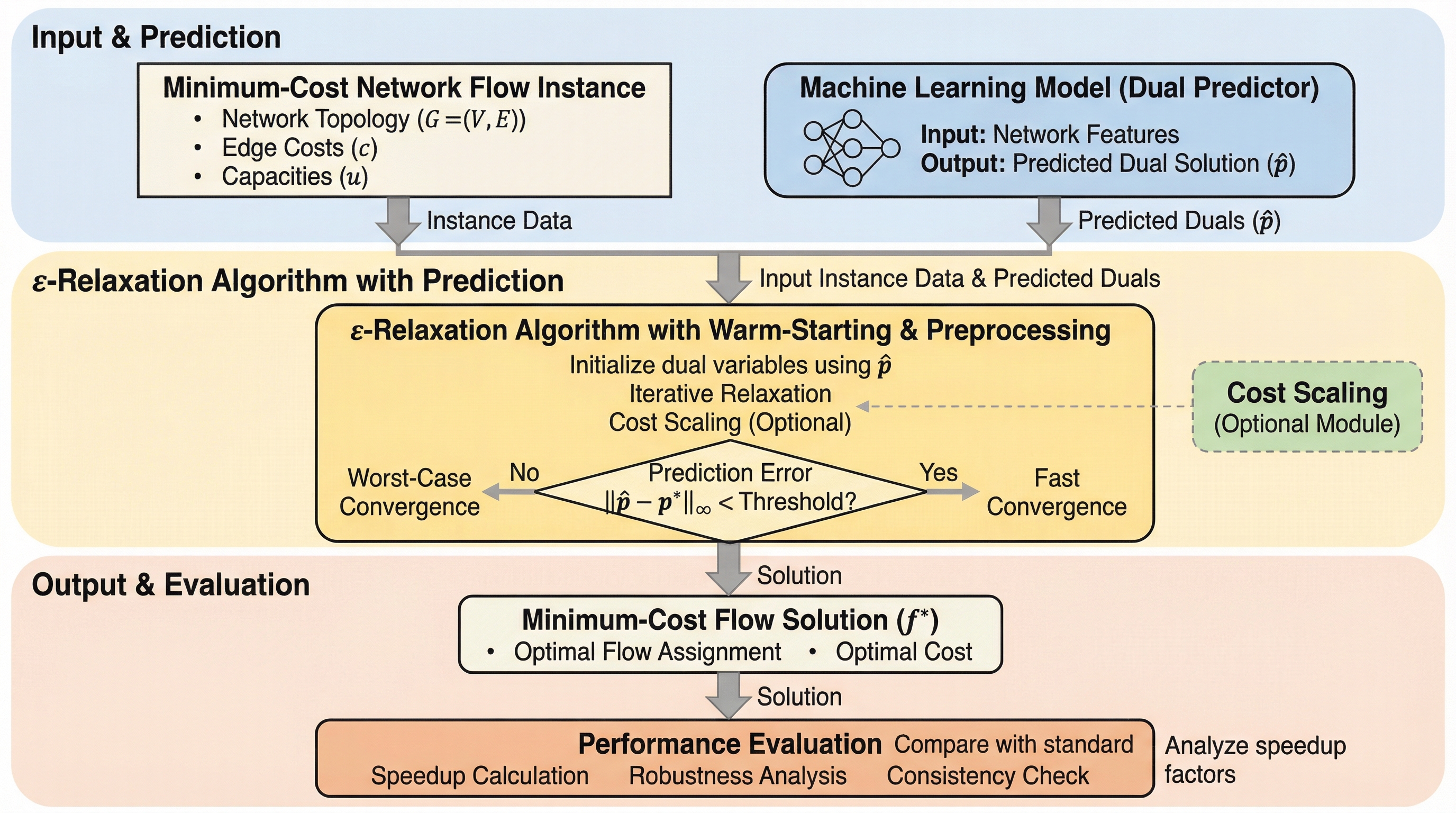
本研究は、機械学習による予測を活用して古典的なアルゴリズムを強化する「学習強化型アルゴリズム」の枠組みを、ネットワーク最適化の重要課題である最小費用流問題(MCF)に初めて適用した。具体的には、古典的なエプシロン・リラクゼーション法を基盤とし、二元的な予測値である「双対予測」を組み込むことで、予測精度が高い場合には大幅な計算高速化を実現し、予測が外れた場合でも従来の最悪時間計算量を維持する堅牢な手法を提案している。 理論面では、予測誤差の無限大ノルムに基づいた時間計算量の改善を証明し、実証面では交通ネットワークやチップのエスケープルーティングにおいて、従来のアルゴリズムと比較して平均で最大12.74倍、特定の条件下では21.4倍という劇的な実行時間の短縮を達成した。 さらに、データ駆動型アルゴリズム設計の観点から、予測値を学習するためのサンプル複雑性の理論的限界も明らかにしており、実用的なニューラルネットワークモデルを用いた予測器の構築から理論的な性能保証までを一貫して提供する画期的な成果となっている。