弱い比較オラクルのみを用いた距離$k$-クラスタリング
従来の$k$-クラスタリング手法が正確な距離情報を必要とするのに対し、本研究では2つのペアの距離の大小を比較する「4点オラクル」のみを利用するランクモデル(R-model)において、ノイズを含む条件下でも効率的に動作する新しいランダム化アルゴリズムを提案しました。
TL;DR(結論)
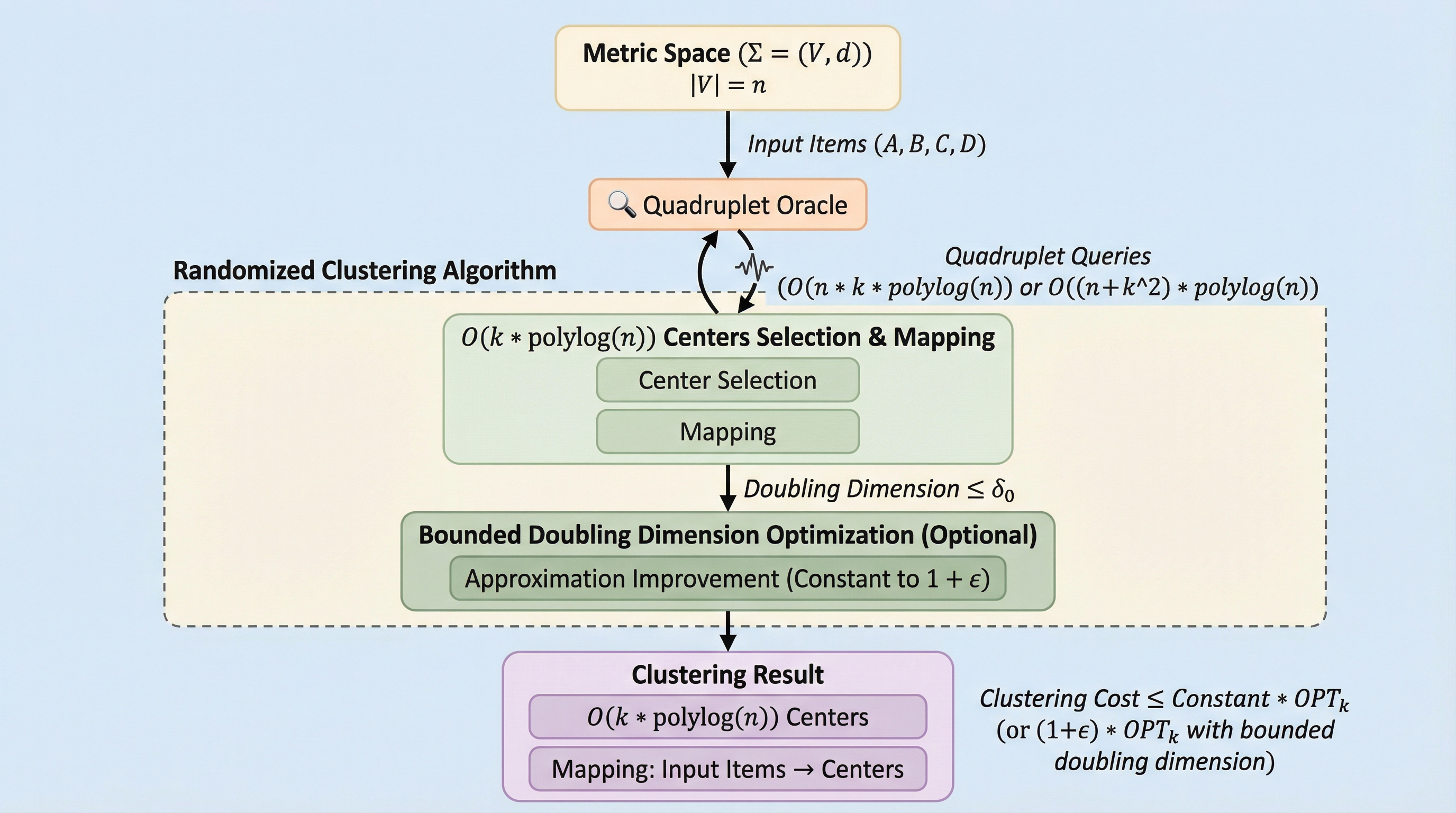
従来の$k$-クラスタリング手法が正確な距離情報を必要とするのに対し、本研究では2つのペアの距離の大小を比較する「4点オラクル」のみを利用するランクモデル(R-model)において、ノイズを含む条件下でも効率的に動作する新しいランダム化アルゴリズムを提案しました。 この手法は、一般的な距離空間において$O(nk \cdot \text{polylog}(n))$、倍増次元が制限された空間では$O((n+k^2) \cdot \text{polylog}(n))$という優れたクエリ計算量を実現しながら、最適なクラスタリングコストに対して定数倍の近似精度を持つ$O(k \cdot \text{polylog}(n))$個の中心点集合とマッピングを構築することに成功しています。 大規模言語モデル(LLM)や人間の直感といった、数値的な距離算出は困難だが相対的な比較は可能な「安価でノイズの多い情報源」を、数学的な保証を伴うスケーラブルなクラスタリングアルゴリズムへと体系的に統合するための理論的枠組みを確立し、その有効性を厳密な解析によって証明しました。
なぜこの問題か
クラスタリングは教師なし学習における最も基本的な手法の一つですが、$k$-meansや$k$-medianといった古典的なアルゴリズムは、データ点間の正確な距離(数値)を直接計算できることを前提としています。しかし、画像データや複雑な意味論的構造を持つデータにおいて、人間の感覚や意味的な類似性を正確に反映した距離尺度を設計することは極めて困難な課題です。また、たとえ適切な距離関数が定義できたとしても、膨大なデータペアのすべてに対して正確な距離を計算することは、計算コストや時間の面から現実的ではないケースが多く存在します。このような背景から、数値としての距離を直接扱うのではなく、比較に基づいた情報を活用する手法が求められてきました。 本研究が焦点を当てるランクモデル(R-model)では、数値的な距離情報は一切利用できず、代わりに「点AとBの距離は、点CとDの距離よりも近いか」という問いに答える4点オラクルのみを利用します。このオラクルは、人間によるフィードバックや機械学習モデルの出力を抽象化したものであり、実用上は判定にノイズが含まれることが避けられません。…
核心:何を提案したのか
本研究の核心的な貢献は、ノイズを伴う4点オラクルのみを使用して、$k$-medianや$k$-meansといった距離$k$-クラスタリング問題を解くための、新しいランダム化アルゴリズムの設計と解析にあります。具体的には、元のデータセットから$O(k \cdot \text{polylog}(n))$個の中心点を選び出し、すべてのデータ点をこれらの中心点のいずれかに割り当てるマッピングを構築する「Coreset+」と呼ばれる手法を開発しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related