言語生成におけるノイズの影響の定量化
本研究は、言語モデルの生成能力が訓練データに含まれる有限個のノイズから受ける影響を理論的に解明し、クリーンなデータとわずか1つのノイズの間には生成可能な言語集合の厳密な減少を伴う決定的な断絶があることを数学的に証明した。
TL;DR(結論)
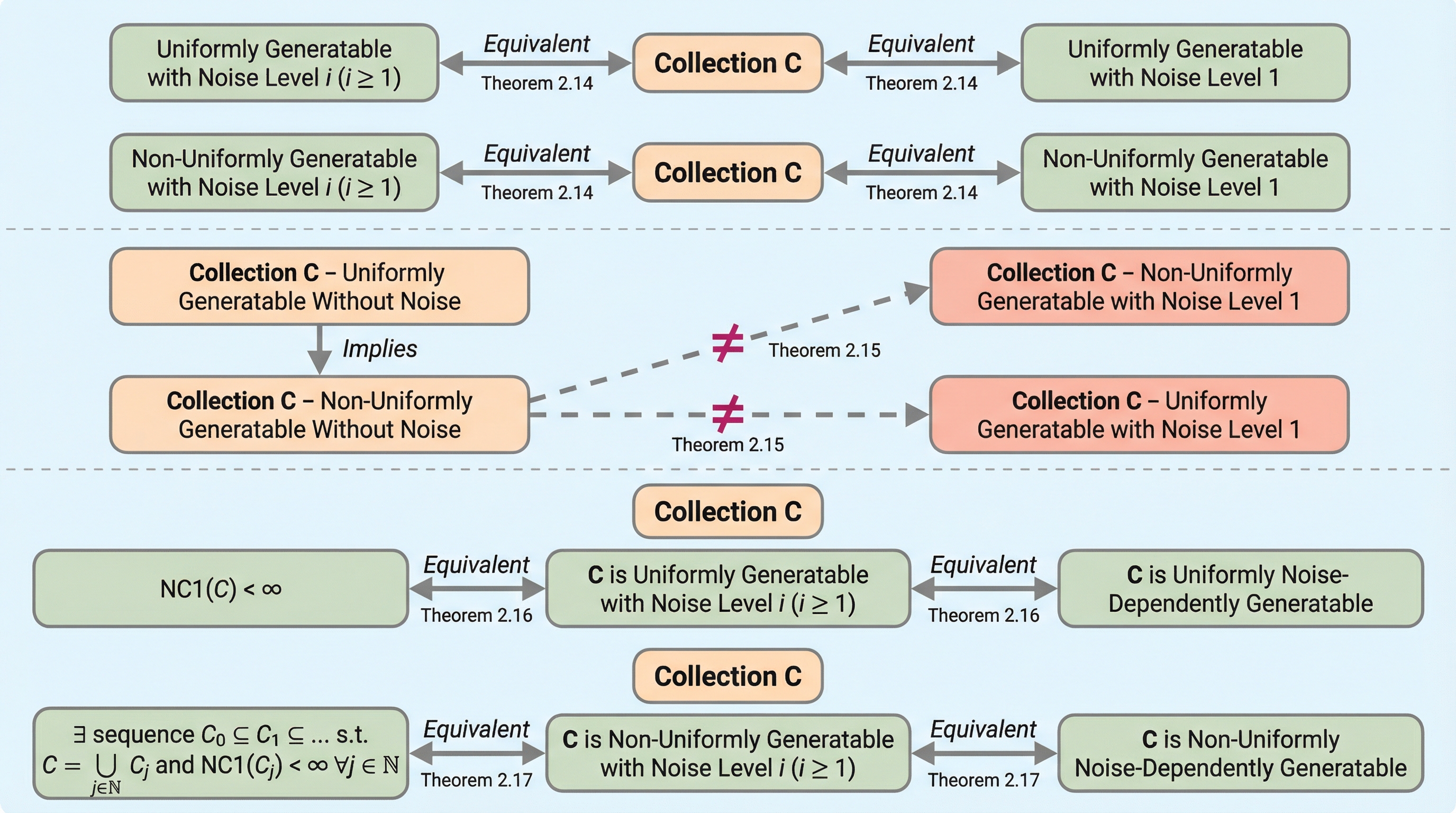
本研究は、言語モデルの生成能力が訓練データに含まれる有限個のノイズから受ける影響を理論的に解明し、クリーンなデータとわずか1つのノイズの間には生成可能な言語集合の厳密な減少を伴う決定的な断絶があることを数学的に証明した。 一方で、一様および非一様生成の枠組みにおいては、1つのノイズに対処可能なアルゴリズムは任意の有限個のノイズにも対処できるという「ノイズの等価性」を見出し、ノイズの数が増えるごとに能力が制限されるという従来の階層的な予測を覆した。 これらの成果に基づき、ノイズが存在する現実的な環境下で言語生成が可能となるための数学的な構造的特徴付けを世界で初めて提示し、ノイズレベル1の「閉包次元」が有限であることが生成可能性の鍵であることを明らかにした。
なぜこの問題か
現代の人工知能、特に大規模言語モデル(LLM)の急速な発展に伴い、その能力と限界を理論的に把握することは極めて重要な課題となっている。近年の研究では、モデルが事実に基づかない情報を出力するハルシネーションの抑制や、モデル内部で構築される世界モデルの解明など、実証的なアプローチが盛んに行われている。しかし、実用上の大きな懸念事項である「訓練データに含まれるノイズ」が、モデルの生成能力の限界にどのような影響を与えるかという問いに対しては、まだ十分な理論的回答が得られていなかった。多くの実証研究は、ラベルのノイズがモデルの性能を低下させることを示しており、それに対する堅牢性を高める手法が提案されてきたが、これらは統計的な性質に依存することが多く、生成の根本的な限界を定義するものではなかった。 本研究が焦点を当てるのは、クラインバーグ(Kleinberg)とマライナサン(Mullainathan)が提唱した「極限における言語生成(language generation in the limit)」という理論的枠組みである。…
核心:何を提案したのか
本論文の最大の貢献は、言語生成におけるノイズの影響について「不連続性」と「飽和性」という二つの対照的な性質を明らかにした点にある。第一に、ノイズが全くないクリーンな状態と、たった1つのノイズ文字列が存在する状態の間には、生成能力において明確な「分離(Separation)」があることを証明した。これは、ノイズの混入が言語モデルの生成能力を単に統計的に低下させるだけでなく、理論的に生成可能な言語のクラスそのものを厳密に縮小させてしまうことを意味している。この結果は、非一様生成と非一様ノイズ依存生成が等価であるかという、先行研究における重要な未解決問題に対して否定的な回答を与えるものである。つまり、クリーンなデータで学習できるからといって、わずかなノイズがある環境で同様の生成ができるとは限らないという厳格な境界線を示した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related