静的データセットを超えて:検証済み合成遷移によるロバストなオフライン方策最適化
MoReBRACは、静的なデータセットに依存する従来のオフライン強化学習の限界を打破するため、不確実性を考慮した世界モデルによる合成データ生成と、階層的なフィルタリングを統合した新しいフレームワークである。
TL;DR(結論)
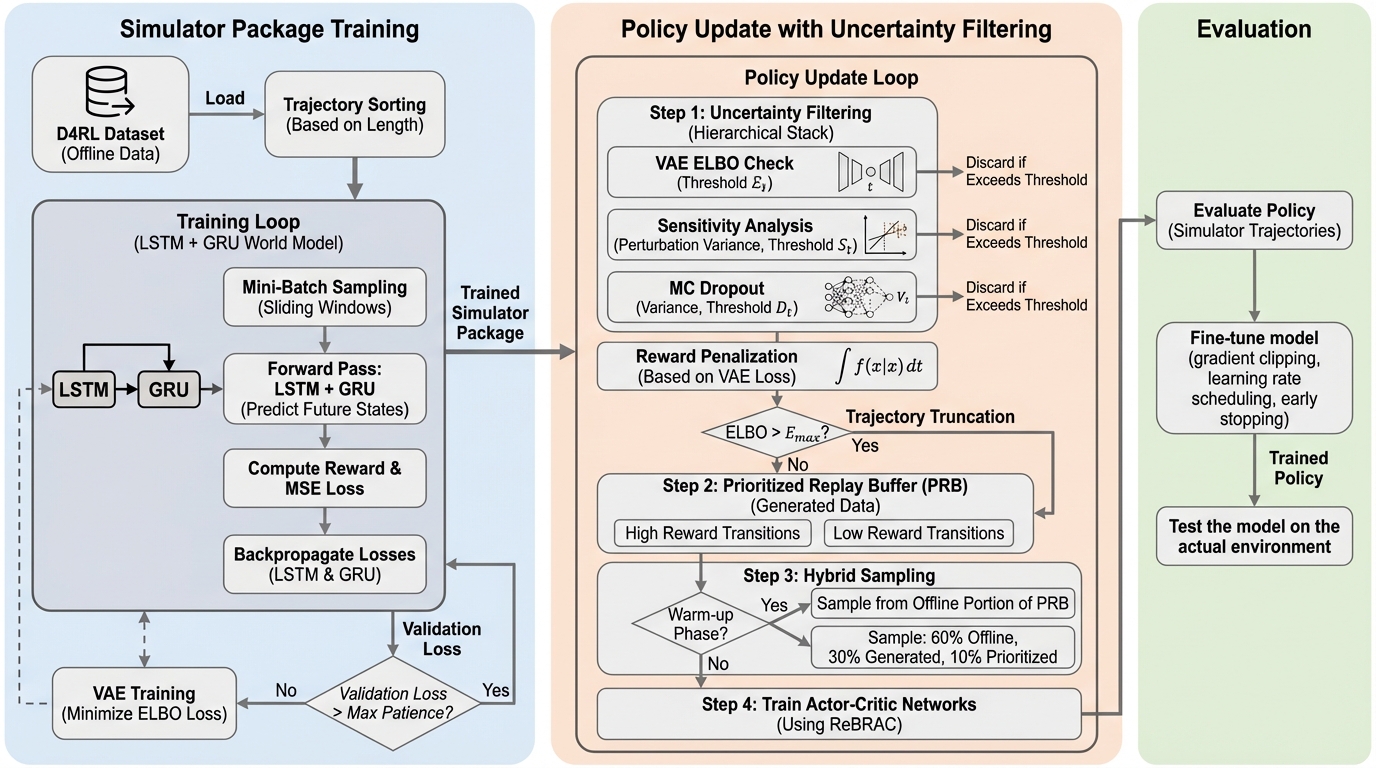
MoReBRACは、静的なデータセットに依存する従来のオフライン強化学習の限界を打破するため、不確実性を考慮した世界モデルによる合成データ生成と、階層的なフィルタリングを統合した新しいフレームワークである。 二重再帰構造を持つLSTMとGRUを用いた高度な世界モデルで高精度な遷移を生成し、VAEによる多様体検出、感度分析、MCドロップアウトを組み合わせた3段階の不確実性パイプラインによって、信頼性の高い遷移のみを学習に利用する。 この手法は、既存のデータセットに含まれる断片的な軌跡を繋ぎ合わせる「接続組織」として機能し、特に低品質なデータセットにおいて従来手法を大きく上回る性能を記録するとともに、VAEがデータの幾何学的な境界を維持するアンカーとして極めて重要な役割を果たすことを示した。
なぜこの問題か
オフライン強化学習(ORL)は、産業用ロボット、医療、自動運転といった安全性が極めて重視される領域において、実環境とのリアルタイムな対話を必要とせずに既存のデータから方策を学習できるため、非常に大きな期待を寄せられている。しかし、ORLにおける主要な障害は、固定された静的なデータセットと学習された方策との間に生じる分布の乖離、すなわち分布シフトの問題である。標準的なオフライン学習アルゴリズムは、エージェントが訓練データに含まれていない未知の行動を選択した際、関数近似の誤差や環境からのフィードバックの欠如により、Q値を過大評価してしまう傾向がある。この過大評価はブートストラップ学習の性質によって増幅され、結果として壊滅的な方策の失敗を招く可能性がある。 既存の解決策は、既知の行動に制限をかける方策制約手法と、未知の状態行動ペアに対してペナルティを与える価値関数の悲観的評価手法の二つに大別される。これらの手法は学習を安定させる効果がある一方で、過度な保守性を引き起こし、エージェントが環境のダイナミクスにおいてより優れた戦略を発見することを妨げてしまうという課題がある。…
核心:何を提案したのか
本研究では、不確実性を考慮した潜在的な合成プロセスを通じて、堅牢な世界モデルを構築する「MoReBRAC(Model-based Restrictive Enhanced Behavior-Regularized Actor-Critic)」を提案している。このフレームワークは、ReBRACによる保守的な方策制約と、高度なデータ生成およびフィルタリングパイプラインを統合することで、訓練データの多様体を効果的に拡張することを目指している。MoReBRACの核心は、学習された世界モデルを通じて高精度な合成遷移を生成する「不確実性ガイド下のシミュレーション探索」というメカニズムにある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related