共鳴型スパース幾何ネットワーク
共鳴型スパース幾何ネットワーク(RSGN)は、脳の自己組織化されたスパースな接続性と動的な経路選択を模倣し、計算ノードを双曲幾何学空間(ポアンカレ球)に配置することで、従来のTransformerが抱える計算量の増大問題を根本から解決する新しいニューラルアーキテクチャである。
TL;DR(結論)
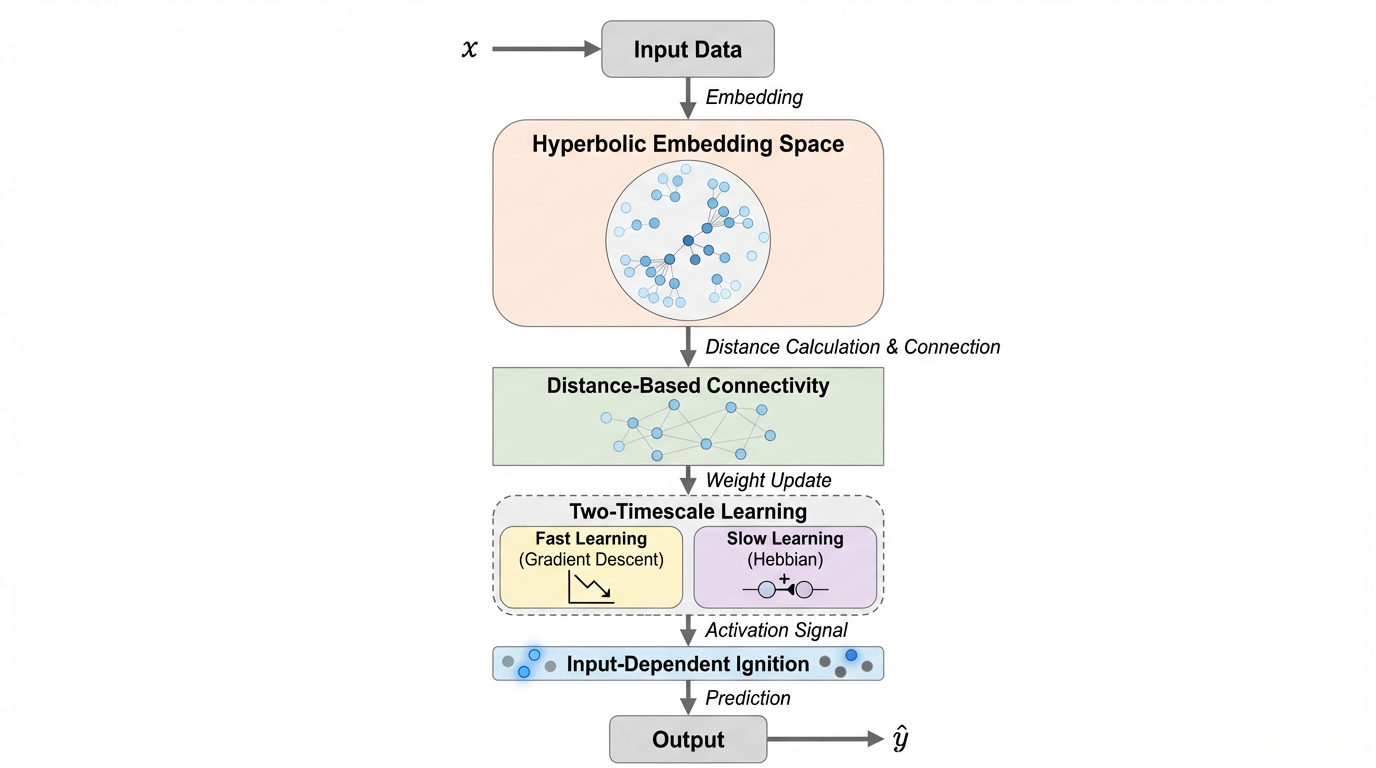
共鳴型スパース幾何ネットワーク(RSGN)は、脳の自己組織化されたスパースな接続性と動的な経路選択を模倣し、計算ノードを双曲幾何学空間(ポアンカレ球)に配置することで、従来のTransformerが抱える計算量の増大問題を根本から解決する新しいニューラルアーキテクチャである。 このモデルは、入力データに応じて「火花」のように活性化するノードを動的に選択する仕組みと、高速な勾配降下法および低速なヘブ学習を組み合わせた二重の時間スケールでの学習を採用しており、情報の階層構造を歪みなく埋め込みながら極めて高い計算効率を実現している。 実験では、長距離依存性タスクにおいて96.5%の精度を維持しつつ、Transformerの約15分の1のパラメータ数で動作することを確認し、20クラスの階層的分類においても、標準的なモデルの約10分の1のパラメータ数で実用的な性能を示すなど、次世代の省リソースAIとしての可能性を実証した。
なぜこの問題か
現代のディープラーニングにおいて、Transformerアーキテクチャは自然言語処理やコンピュータビジョンなどの分野で圧倒的な成果を収めているが、その核心である自己注意(Self-Attention)メカニズムには深刻な課題が存在する。自己注意はシーケンス内のすべてのトークン間の関係を計算するため、計算コストがシーケンス長の2乗に比例して増大するという性質があり、これが長文の理解や大規模なコンテキストを扱う際の大きな障壁となっている。例えば、1,000トークンの処理には100万回の計算が必要だが、10万トークンになると100億回もの操作が必要になり、標準的なハードウェアでは計算資源が枯渇してしまう。このスケーリングの限界は、より長い情報を効率的に処理しようとする現代のAI開発において、根本的なパラダイムシフトを求めている。 一方で、人間の脳はわずか20ワット程度の電力で動作しながら、極めて複雑な情報の処理や記憶の保持を同時に行っている。この驚異的な効率性は、約860億個のニューロンと約100兆個のシナプスによって支えられているが、その計算原理は現在の人工知能システムとは根本的に異なっている。…
核心:何を提案したのか
本論文では、上述した4つの生物学的原則を統合した「共鳴型スパース幾何ネットワーク(RSGN)」を提案している。RSGNの最大の特徴は、計算ノードを$d$次元の双曲空間、具体的にはポアンカレ球モデルの中に埋め込んでいる点にある。双曲空間は、半径に対して体積が指数関数的に増大するという性質を持っており、木構造のような階層的な関係を歪みなく埋め込むのに非常に適している。ユークリッド空間では階層構造を表現する際に大きな歪みが生じやすいが、双曲空間であれば、中心に近い抽象的な概念から境界に近い具体的な詳細までを自然に配置できる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related