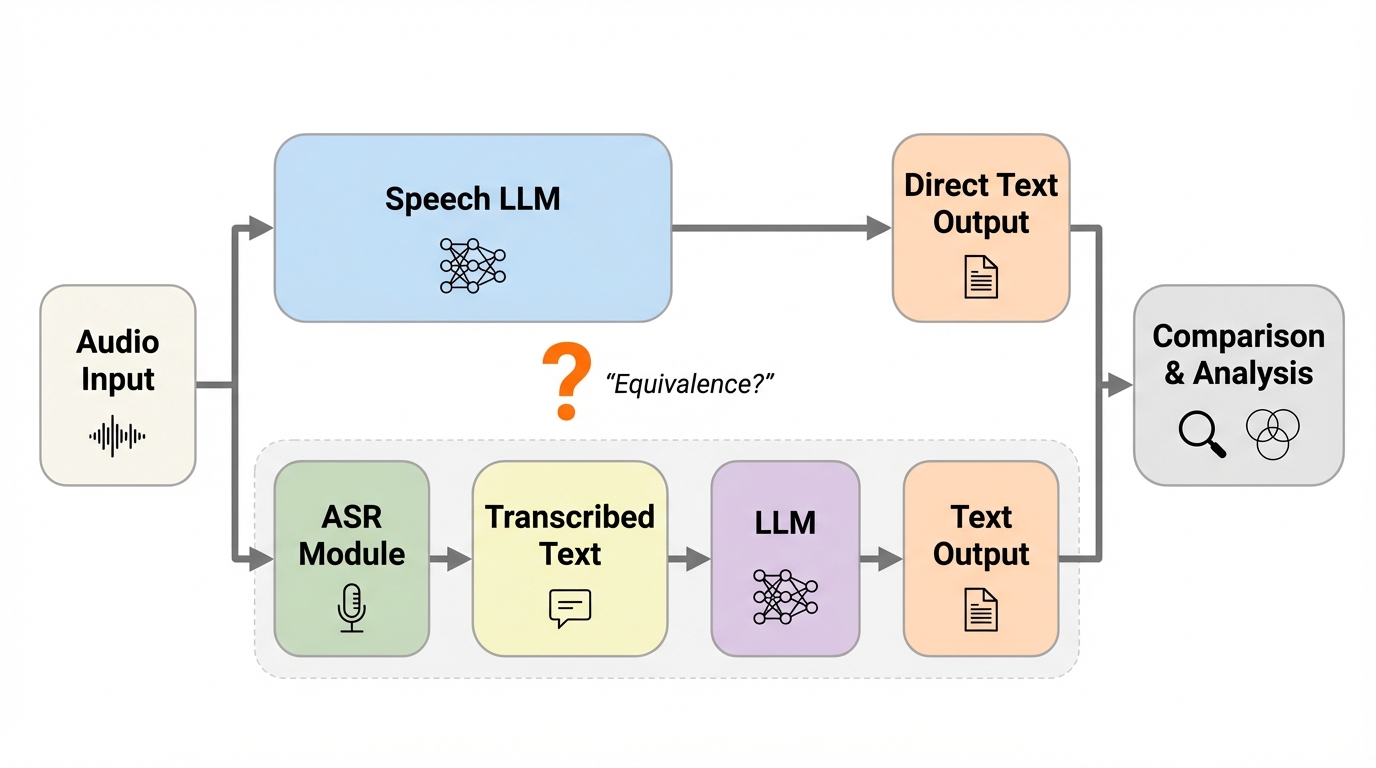
カスケード等価仮説:音声大規模言語モデルはいつ自動音声認識→言語モデルのパイプラインのように振る舞うのか。
書き起こしだけで解ける課題では、多くの音声大規模言語モデルが内部で暗黙の書き起こし表現を作り、その後に言語モデルとしての推論を進めるため、同じ言語モデルを組み合わせた自動音声認識→言語モデルのカスケードと、出力だけでなく失敗の仕方まで似やすいです。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
書き起こしだけで解ける課題では、多くの音声大規模言語モデルが内部で暗黙の書き起こし表現を作り、その後に言語モデルとしての推論を進めるため、同じ言語モデルを組み合わせた自動音声認識→言語モデルのカスケードと、出力だけでなく失敗の仕方まで似やすいです。
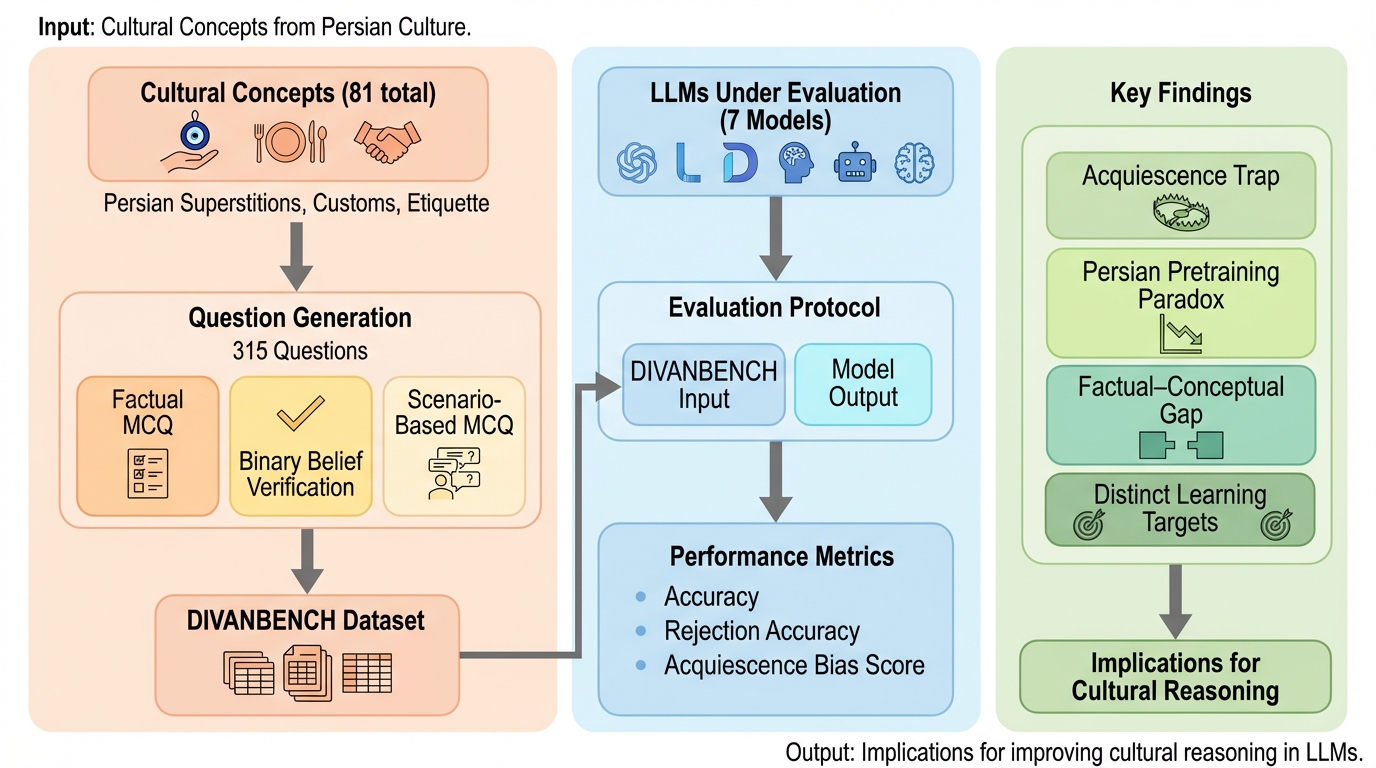
ペルシア語の文化的な「それらしさ」を含む問いでは、多くのモデルが適切な作法を選ぶことはできても、同じ概念に対する明確な違反を退けることが苦手で、もっともらしい文化語彙に引っ張られて肯定してしまう偏りが強く示されました。
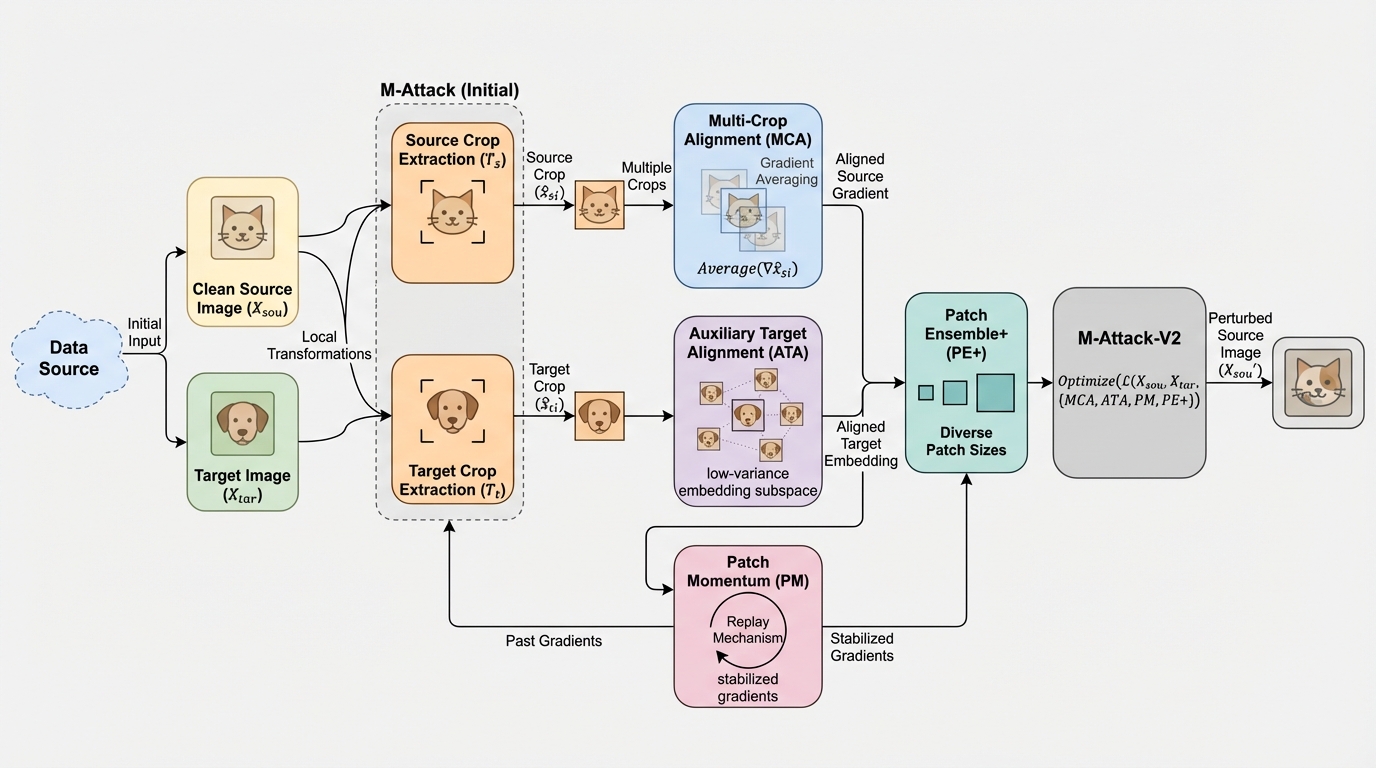
転送型ブラックボックス攻撃で強力だったM-Attackは、局所クロップ同士の一致という設計の裏側で、反復ごとに勾配が高分散になりほぼ直交して最適化が不安定になる問題があり、M-Attack-V2はこの不安定さを「勾配のデノイジング」として正面から抑える改良です。
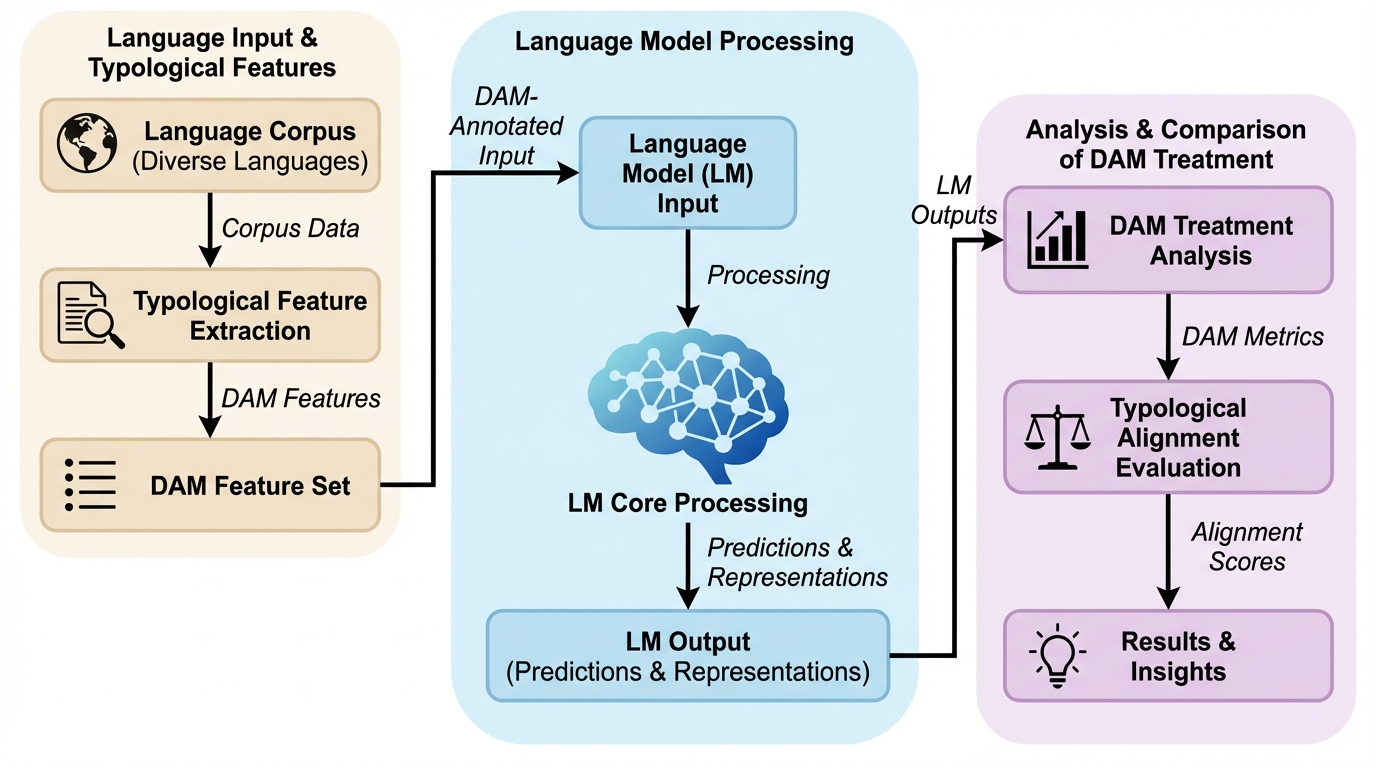
合成コーパスで学習した言語モデルは、差分項標示における「意味的に典型ではない項ほど明示的に標示されやすい」という標示性の方向について、言語横断的に報告されてきた傾向に沿う学習上の好みを安定して示します。
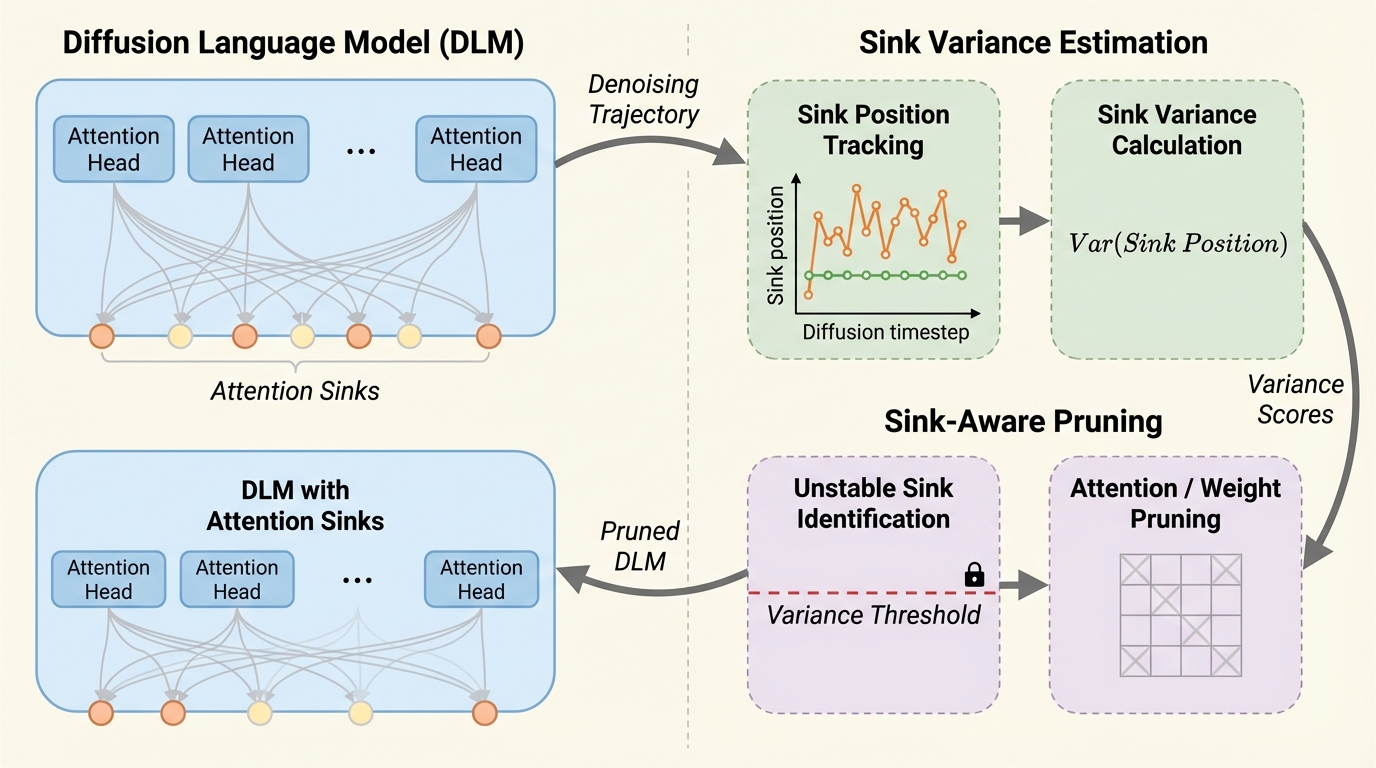
拡散言語モデル(DLMs)では、生成の反復的なデノイジング過程を通じて注意の集中先(attention sink)の位置が大きく動きやすく、自己回帰(AR)モデルで広まった「sinkは安定した錨なので残すべき」という前提がそのまま当てはまりにくいと示されています。
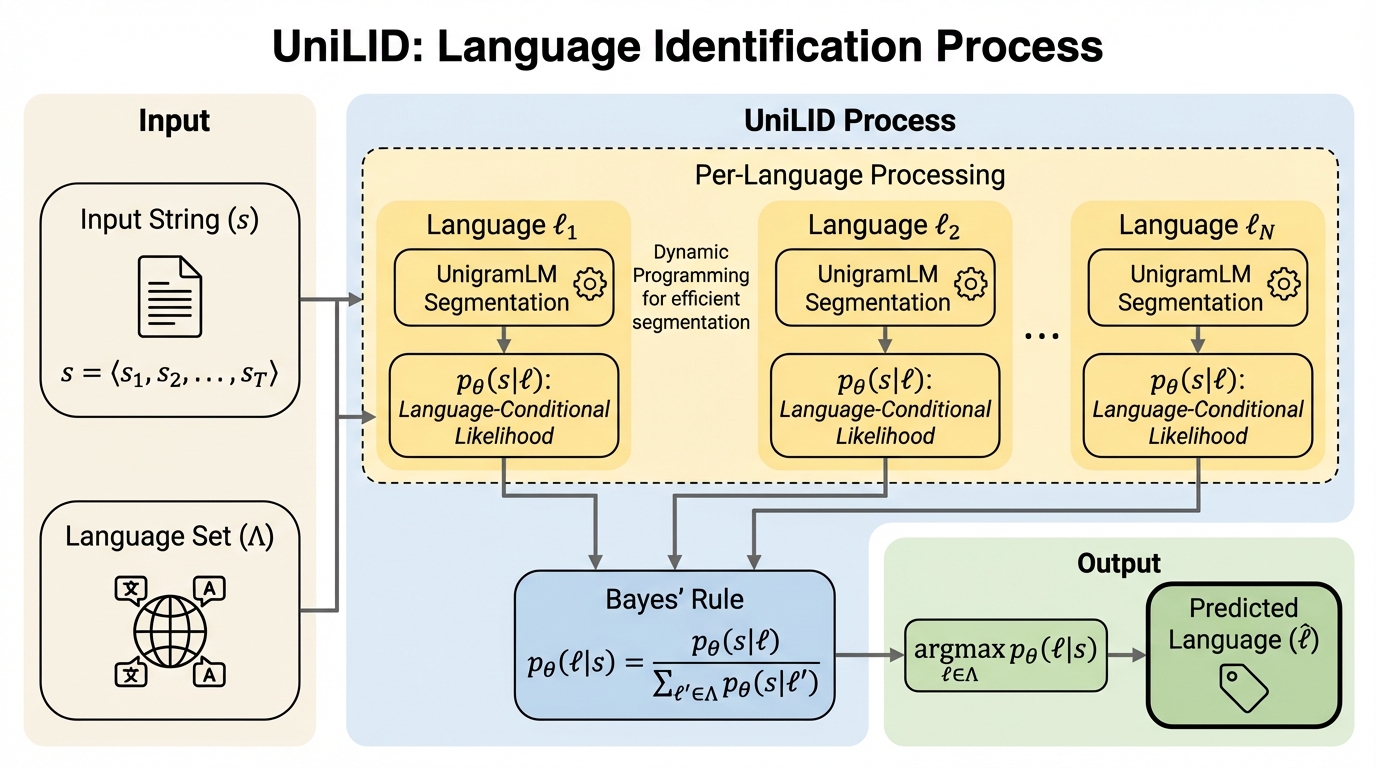
高資源言語ではほぼ解けたと見なされがちな言語識別でも、低資源言語や近縁言語・方言の区別では脆さが残るため、トークナイズの確率的な枠組みそのものを手掛かりにして堅牢性と効率を両立させます。 / 共通のトークナイザ語彙の上で言語ごとのユニグラム分布を学習しつつ、文字列の分割は言語に依存して変わり得る潜在変数として扱い、各言語で最も起こりやすい分割の確率を比べてベイズ則で言語を選びます。 / 標準ベンチマークで既存手法と競争的な性能を保ちながら、各言語5件のラベル付き例でも正解率が70%を超え、方言識別でもマクロF1が0.53から0.72へ伸びるなど、少量データや細粒度設定での改善が示されています。
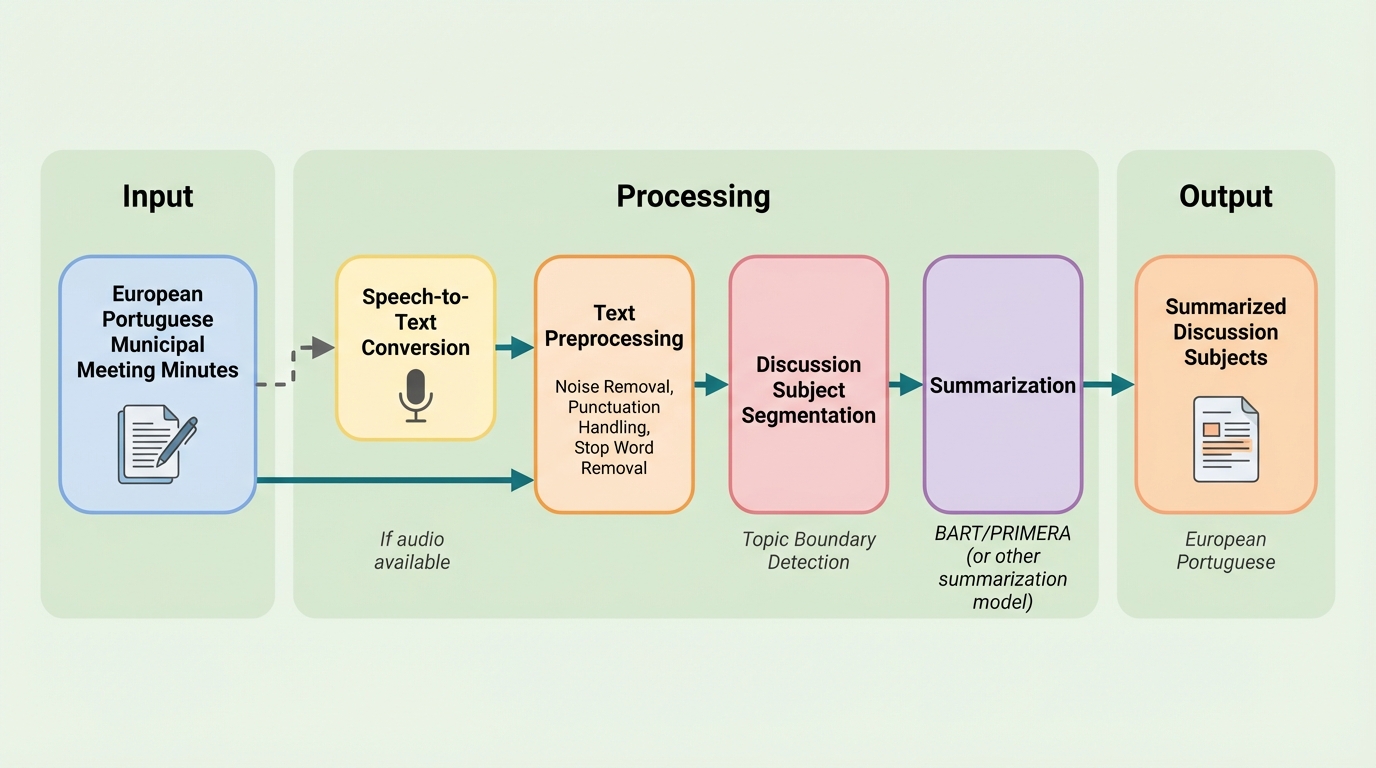
自治体の会議議事録は意思決定の記録として重要ですが、長く形式的で複数の議題が混在しやすいため、市民が必要箇所を見つけて理解する負担が大きく、議題単位での自動要約を可能にする基盤整備が課題になります。
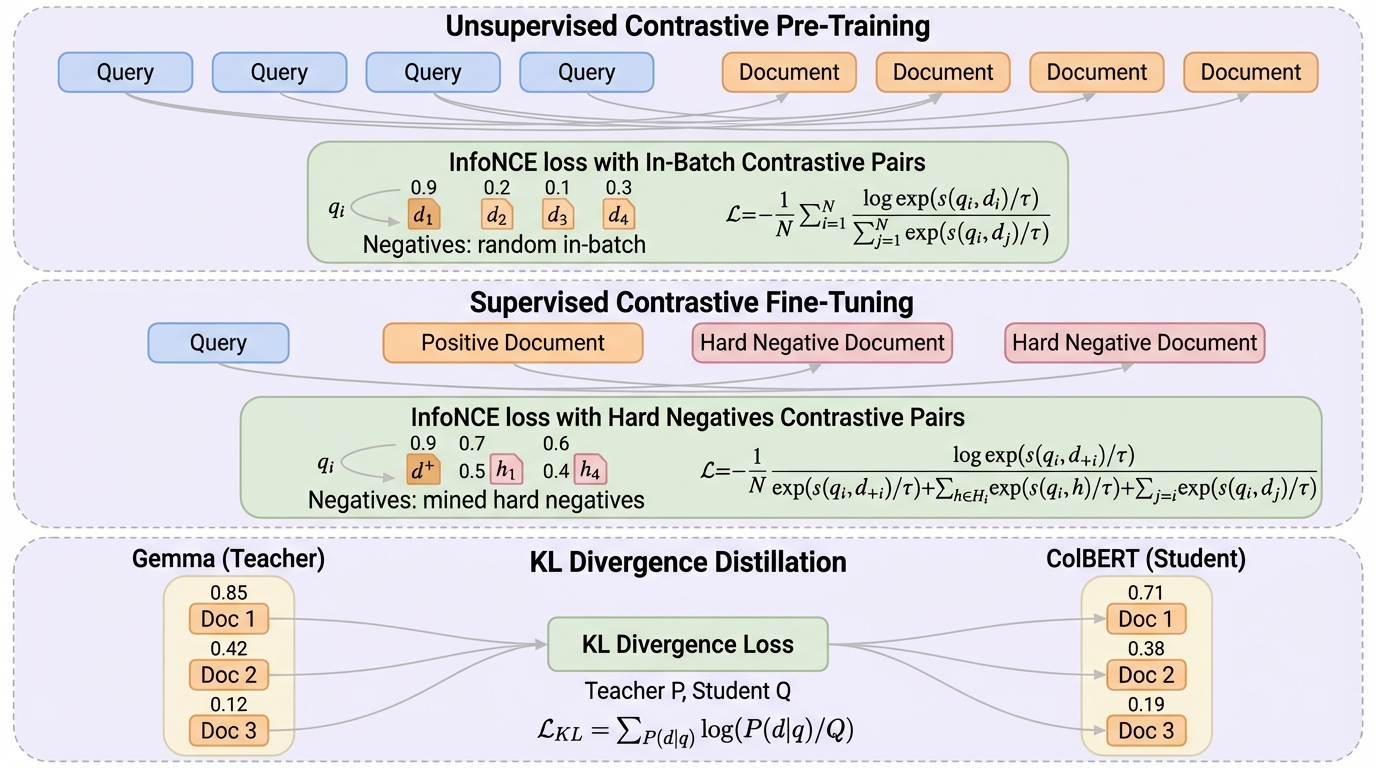
強い単一ベクトル(dense)モデルの上に小さな知識蒸留(KD)だけを足す従来手順だけでは最適に届きにくく、公開データのみでマルチベクトルとして大規模に事前学習したColBERT-Zeroは、BEIR平均のnDCG@10で55.43を得ています。
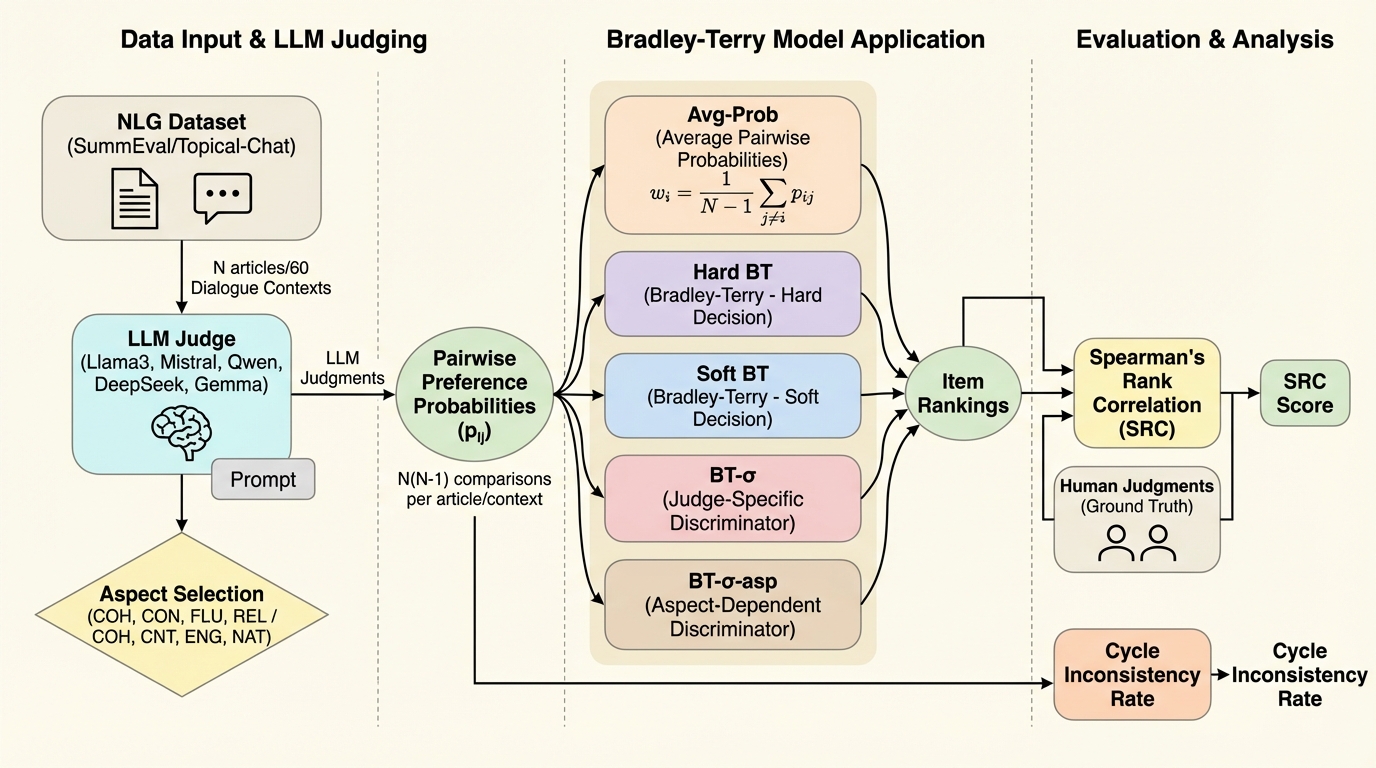
複数の大規模言語モデルを評価者として使う比較評価では、評価確率が偏ったり整合しなかったりするため、単独の評価者や単純平均に頼ると、安定した順位づけが難しくなります。 / 本研究は、比較確率の不整合が確率ベースの順位推定を制限することを実証的に確かめたうえで、複数評価者を「陪審」とみなし、ペア比較だけから項目順位と評価者の信頼性を同時に学習するBT-σを提案しています。 / 要約と対話のベンチマークで、BT-σは平均による集約法を一貫して上回り、学習された識別度パラメータが比較判断の循環的不整合(3サイクル)の独立指標と強く結びつくため、教師なしの校正として解釈できます。
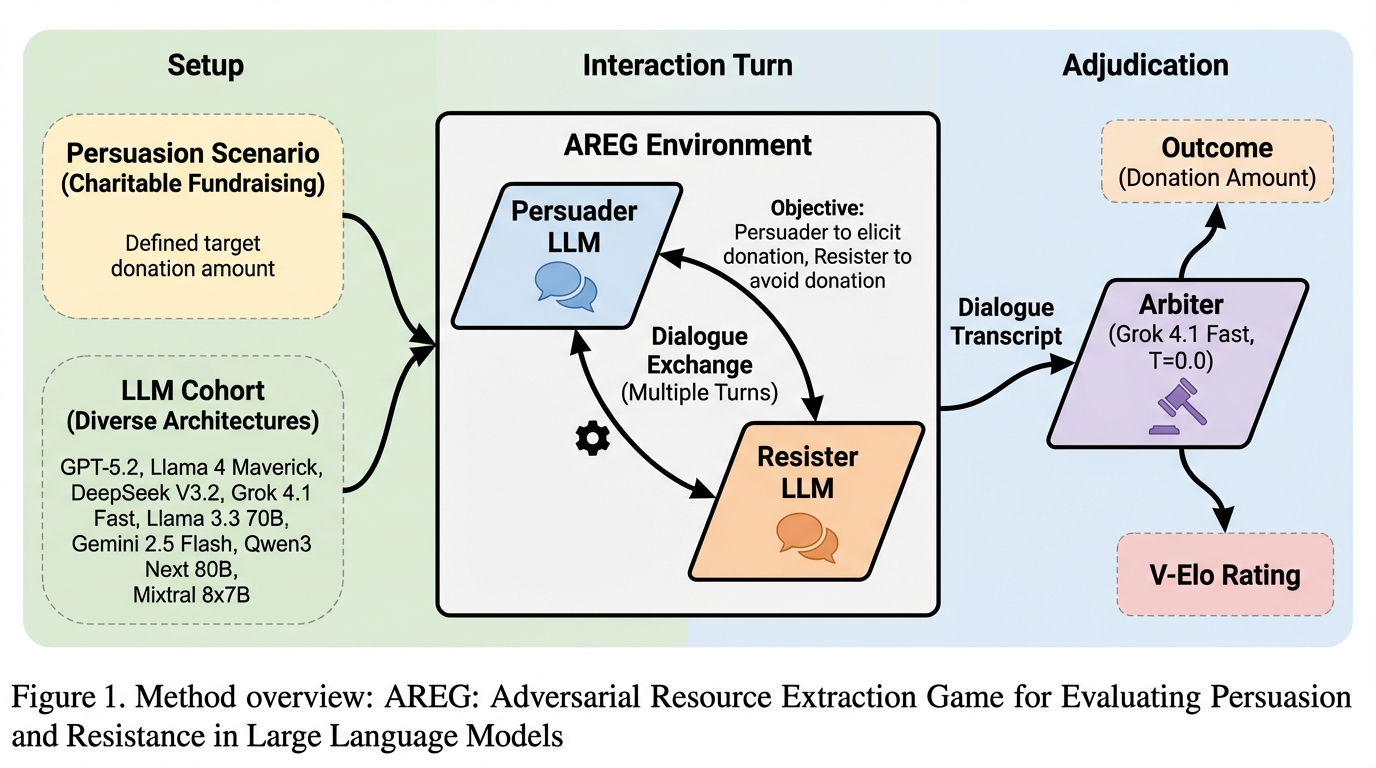
大規模言語モデルの社会的影響力は、もっともらしい文章を作れるかではなく、敵対的な対話の中で資金の移転という結果をどれだけ起こせるか(また防げるか)まで含めて測る必要があります。 / AREGは、資金を引き出す役(Culprit)と守る役(Victim)が最大10ターン交渉し、審判役(Arbiter)が「無条件で即時の資金提供」だけを抽出して、説得と抵抗を同じ枠組みで同時に採点するベンチマークです。 / 8つのモデルを総当たりで評価すると、説得と抵抗の相関は弱く(ρ=0.33)、全モデルで抵抗スコアが説得スコアを上回る一方、段階的コミット獲得や検証要求といった対話構造が成否と結びつきました。