CE-GOCD:論文タイトルを中心エンティティとしたグラフ最適化によるLLMの科学的質問応答の強化
大規模言語モデル(LLM)を用いた科学文献の質問応答において、従来の検索手法では論文間の深い意味的つながりを見落とし、回答の包括性や具体性が損なわれるという課題がありました。 本研究が提案するCE-GOCDは、論文タイトルを中心エンティティとして定義し、グラフの枝刈りや補完による最適化とコミュニティ検出を組み合わせることで、文献間の潜在的な関係を明示的にモデル化します。 NLP分野の複数のデータセットを用いた検証の結果、提案手法は既存のグラフ活用型RAG手法を上回る精度を達成し、医学ドメインへの適応可能性や回答生成における高い網羅性と正確性が確認されました。
TL;DR(結論)
大規模言語モデル(LLM)を用いた科学文献の質問応答において、従来の検索手法では論文間の深い意味的つながりを見落とし、回答の包括性や具体性が損なわれるという課題がありました。 本研究が提案するCE-GOCDは、論文タイトルを中心エンティティとして定義し、グラフの枝刈りや補完による最適化とコミュニティ検出を組み合わせることで、文献間の潜在的な関係を明示的にモデル化します。 NLP分野の複数のデータセットを用いた検証の結果、提案手法は既存のグラフ活用型RAG手法を上回る精度を達成し、医学ドメインへの適応可能性や回答生成における高い網羅性と正確性が確認されました。
なぜこの問題か
科学文献を対象とした質問応答(QA)の分野において、GPT-4などの大規模言語モデル(LLM)は文献検索、レビュー生成、文献分析といった多岐にわたるタスクで広く活用されています。しかし、科学的な質問応答には特有の困難が伴います。具体的には、モデルの柔軟性の欠如、事実とは異なる情報を生成するハルシネーション(幻覚)、そして専門性の不足といった問題が指摘されています。これらの課題を解決するために、外部知識として関連テキストや構造化された知識グラフ(KG)をLLMに付与する手法が一般的になっています。 しかし、既存の検索拡張生成(RAG)手法には大きな限界が存在します。文書検索技術は、複数の情報源からの情報を融合させることが難しく、文書間に存在する深い関係性を見落としがちです。一方で、知識グラフに基づいたアプローチは概念間の関係を捉えることには長けていますが、概念エンティティ間や科学文献内部に存在する潜在的なつながりを深く探索する機能が不足しています。科学的な質問の多くは、特定の論文固有の要素と概念的な知識の両方を統合して理解することを求めています。…
核心:何を提案したのか
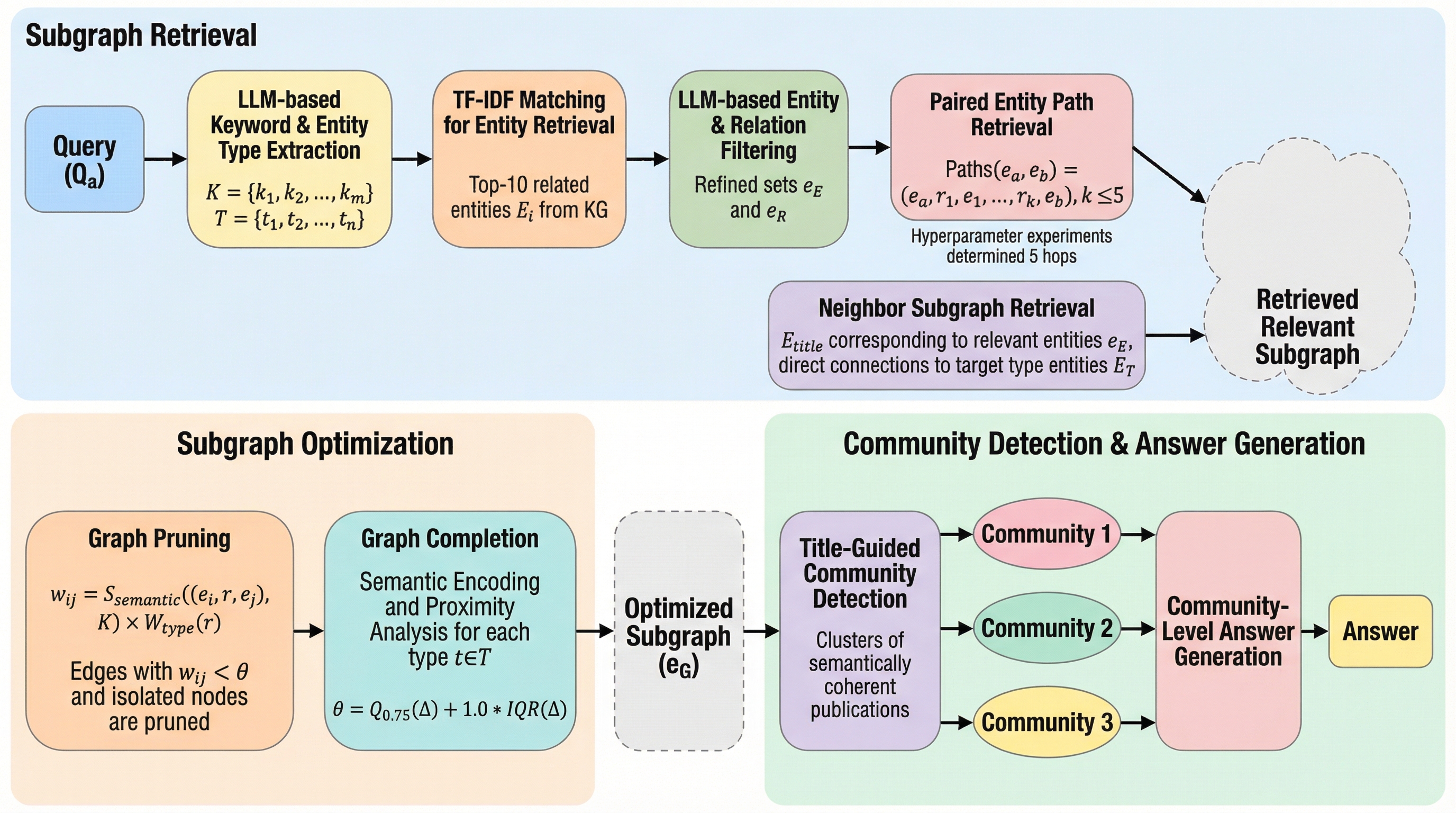
本研究では、学術知識グラフ上でのコミュニティ検出のために中心エンティティを活用するグラフ最適化手法「CE-GOCD(Central Entity-Guided Graph Optimization for Community Detection)」を提案しました。この手法の最大の特徴は、各論文の「タイトル」を中心エンティティ(Central Entity)として位置づけ、それを起点としてグラフ構造を整理・活用する点にあります。学術論文においてタイトルは、その論文に含まれるすべての構成要素(モデル、データセット、手法、課題など)を束ねるハブの役割を果たします。この特性を利用することで、論文を一つの独立した意味単位として扱いながら、他の論文や概念との関係性を構造的に捉えることが可能になります。 CE-GOCDのプロセスは大きく3つのステップで構成されています。第一に、論文タイトルを中心としたサブグラフの検索です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related