大規模言語モデルのための時間的ガイダンス:TeGu
大規模言語モデル(LLM)の生成品質を向上させるため、モデル自身の過去の不完全な予測を「アマチュア」として利用し、現在の予測と対比させる新しいデコーディング戦略「TeGu(Temporal Guidance)」が提案されました。
TL;DR(結論)
大規模言語モデル(LLM)の生成品質を向上させるため、モデル自身の過去の不完全な予測を「アマチュア」として利用し、現在の予測と対比させる新しいデコーディング戦略「TeGu(Temporal Guidance)」が提案されました。 この手法は、マルチトークン予測(MTP)の仕組みを応用し、直近の文脈を欠いた過去の予測分布から一般的なノイズを特定して抑制することで、数学的推論やコード生成、指示追従における正確性と事実性を大幅に高めます。 従来の対照的デコーディング(CD)のような外部モデルや、レイヤー間対比(DoLa)のような不安定な層選択を必要とせず、単一モデル内で完結する軽量なプロジェクターを用いることで、極めて高い計算効率と堅牢性を実現しました。
なぜこの問題か
大規模言語モデル(LLM)は、複雑な推論や創造的な文章作成において驚異的な能力を発揮していますが、標準的な自己回帰生成プロセスには依然として解決すべき課題が山積しています。特に、生成された文章が同じフレーズを繰り返すループに陥ったり、具体的で有用な情報の代わりに一般的で退屈な応答を返したり、事実に基づかない「ハルシネーション(幻覚)」を引き起こしたりする問題は、実用化における大きな障壁となっています。これらの問題を解決するために、能力の高い「エキスパート」モデルの出力から、意図的に能力を下げた「アマチュア」モデルの出力を差し引くことで、推論の信号を増幅し、言語の一般的な偏りを抑制する「対照的デコーディング(CD)」という手法が注目されてきました。 しかし、標準的な対照的デコーディングには実用上の大きな欠点があります。それは、推論時にエキスパートとアマチュアという2つの独立したモデルを同時に動作させる必要があるため、計算コストが大幅に増大し、ビデオメモリ(VRAM)の消費量や推論の遅延が深刻化する点です。…
核心:何を提案したのか
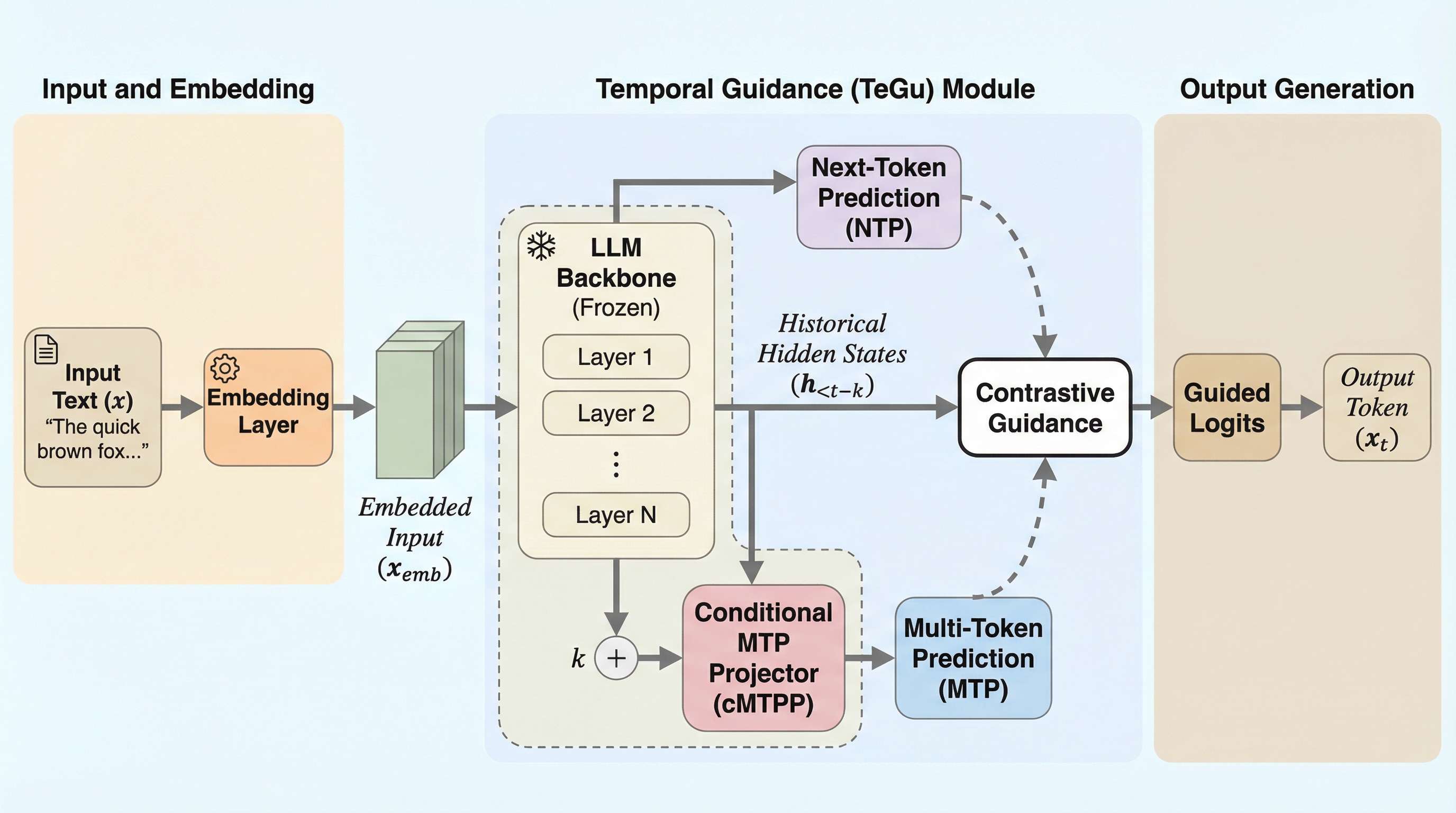
本論文では、LLMの時間的次元(Temporal Dimension)を巧みに利用した、堅牢かつ効率的なデコーディング戦略である「TeGu(Temporal Guidance)」を提案しています。この手法の核心的なアイデアは、モデル自身の「過去の自分」をアマチュアとして利用するという点にあります。具体的には、マルチトークン予測(MTP)の設定において、ある時点の隠れ状態から数手先のトークンを予測させると、その予測は直近の重要な文脈を欠いているため、必然的に「不完全で一般的な予測(アマチュア分布)」になります。この文脈が不足した過去の予測と、現在の完全な文脈を持つ「エキスパート分布」を対比させることで、生成プロセスをより正確な方向へと導くことが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related