CoFrGeNet: 連分数に着想を得た新しい言語生成アーキテクチャ
IBM Researchの研究チームは、連分数(Continued Fractions)の数学的構造を言語生成モデルに組み込んだ新アーキテクチャ「CoFrGeNet」を提案しました。このモデルは、従来のTransformerにおけるマルチヘッドアテンションやフィードフォワードネットワーク(FFN)を、より少ないパラメータ数で代替可能な連分数コンポーネントへと置き換えることに成功しています。 独自の「コンティニュアント(Continuants)」を用いた計算手法を導入することで、連分数計算のボトルネックであった除算回数を劇的に削減し、学習および推論の効率を飛躍的に向上させました。これにより、計算リソースの消費を抑えつつ、高度な言語生成能力を維持することが可能になります。 GPT2-xlやLlama3を用いた大規模な実験の結果、元のモデルの半分から3分の2程度のパラメータ数でありながら、分類、質疑応答、推論などの多様なタスクにおいて、標準的なTransformerと同等以上の性能をより短い学習時間で達成できることを実証しました。
TL;DR(結論)
IBM Researchの研究チームは、連分数(Continued Fractions)の数学的構造を言語生成モデルに組み込んだ新アーキテクチャ「CoFrGeNet」を提案しました。このモデルは、従来のTransformerにおけるマルチヘッドアテンションやフィードフォワードネットワーク(FFN)を、より少ないパラメータ数で代替可能な連分数コンポーネントへと置き換えることに成功しています。 独自の「コンティニュアント(Continuants)」を用いた計算手法を導入することで、連分数計算のボトルネックであった除算回数を劇的に削減し、学習および推論の効率を飛躍的に向上させました。これにより、計算リソースの消費を抑えつつ、高度な言語生成能力を維持することが可能になります。 GPT2-xlやLlama3を用いた大規模な実験の結果、元のモデルの半分から3分の2程度のパラメータ数でありながら、分類、質疑応答、推論などの多様なタスクにおいて、標準的なTransformerと同等以上の性能をより短い学習時間で達成できることを実証しました。
なぜこの問題か
現在の自然言語処理の分野において、Transformerアーキテクチャは言語生成の標準的な枠組みとして君臨していますが、その計算コストとパラメータの膨大さは深刻な課題となっています。特に、マルチヘッドアテンション(Multihead Attention)とフィードフォワードネットワーク(FFN)は、モデルの規模が拡大するにつれて膨大な計算リソースを要求し、系列長に対して計算量が二乗で増加するという性質を持っています。これまでにも、アテンションの近似手法や状態空間モデル(SSM)など、効率化を目指した様々なアプローチが提案されてきましたが、Transformerの構成要素そのものを全く異なる数学的関数クラスに置き換える試みは、依然として未開拓で重要な研究領域です。 連分数は、実数を合理的に近似するための優れた数学的特性を持っており、任意の関数を近似する能力(万能近似能力)を備えていることが数学的に知られています。先行研究では、教師あり学習の設定において連分数を用いたネットワーク(CoFrNets)が提案されていましたが、これを言語生成のような生成モデリングの設定に適用する方法は確立されていませんでした。…
核心:何を提案したのか
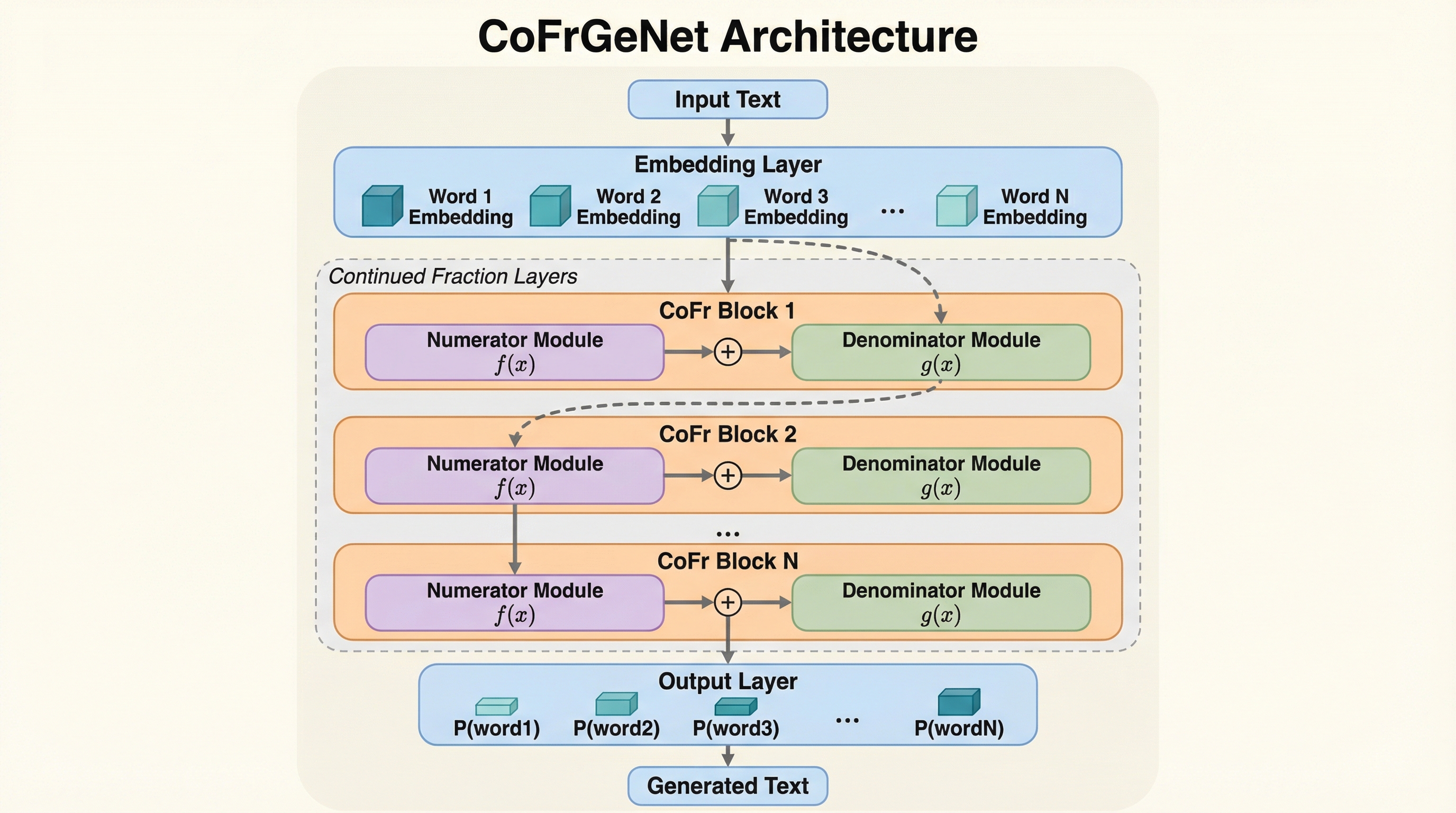
本論文の核心は、連分数に着想を得た新しい関数クラスを実装するアーキテクチャ群「CoFrGeNets(Continued Fraction Generative Networks)」の提案にあります。このアーキテクチャは、Transformerブロック内のアテンション層やFFN層を直接置き換えることができる新しいコンポーネントで構成されています。連分数の標準形である「a0 + 1 / (a1 + 1 / (a2 + ...…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related