テキスト検索モデルのドメイン適応における影響度ガイド付きサンプリング
検索モデルの学習において、膨大で多様なデータセットから最適な訓練データを抽出する戦略は極めて重要ですが、従来の均等サンプリングや専門家の手動設定、あるいは勾配ベースの動的手法には、計算コストの増大や学習の不安定さという課題がありました。
TL;DR(結論)
検索モデルの学習において、膨大で多様なデータセットから最適な訓練データを抽出する戦略は極めて重要ですが、従来の均等サンプリングや専門家の手動設定、あるいは勾配ベースの動的手法には、計算コストの増大や学習の不安定さという課題がありました。 本研究が提案する「Inf-DDS」は、強化学習の枠組みを用いてターゲットドメインに対する各データの「影響度」を報酬として算出し、サンプリングの重みを動的に最適化することで、既存手法よりも安定した学習と高い検索性能を実現する新しいフレームワークです。 実証実験の結果、Inf-DDSは多言語モデルbge-m3においてNDCG@10を5.03ポイント向上させ、さらに既存の勾配ベース手法と比較してGPUの計算コストを1.5倍から4倍削減することに成功しており、効率的かつ効果的なドメイン適応が可能であることを示しました。
なぜこの問題か
汎用的なオープンドメインの密ベクトル検索システムは、通常、多様なコーパスや検索タスクを混合した大規模なデータセットを用いて学習されます。しかし、これらの多様なデータからどのように訓練サンプルを抽出するかという戦略は、モデルの最終的な性能に多大な影響を与えることが知られています。従来のアプローチでは、すべてのデータを均等に扱う手法や、各データのインスタンス数に比例させる手法、あるいは人間による専門的な監視に基づいたサンプリングが行われてきました。しかし、データセットが大規模になるほど、単にデータ量を増やすだけでは埋め込みモデルの品質向上には繋がらず、どのデータセットが最も有益であるかを特定し、その最適な比率を見出すことが極めて重要な課題となっています。 既存の動的なサンプリング手法として、勾配を利用して学習分布をオンラインで調整する手法や、プロキシモデルを用いてデータの有用性を推定する手法が提案されてきました。しかし、これらの手法には実用上の大きな障壁が2点存在します。第一に、確率的勾配に起因する不安定さと高い分散が学習を阻害することです。…
核心:何を提案したのか
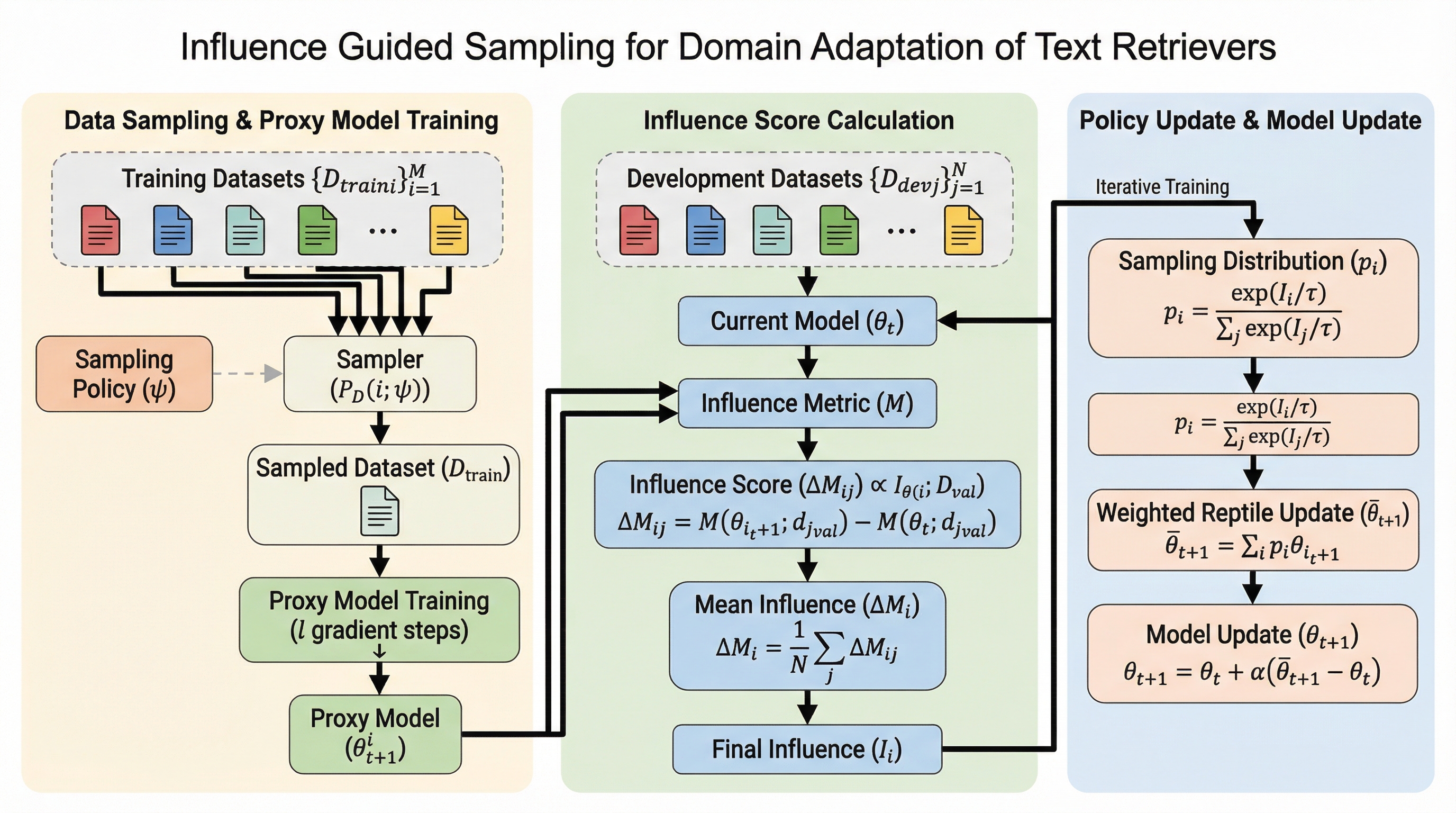
本論文では、計算効率に優れた新しいアルゴリズムである「影響度ガイド付き動的データサンプリング(Inf-DDS: Influence-guided Dynamic Data Sampling)」を提案しています。これは、強化学習をベースとしたサンプリングフレームワークであり、影響度に基づいた報酬信号を利用して訓練データセットの重みを適応的に再調整するものです。Inf-DDSは、各ドメインのデータに対して小さな勾配更新ステップを繰り返し実行し、その更新が下流の評価指標にどのような影響を与えるかを監視します。そして、より大きな性能向上に寄与したドメインに対して、より高い報酬とサンプリング重みを割り当てる仕組みとなっています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related