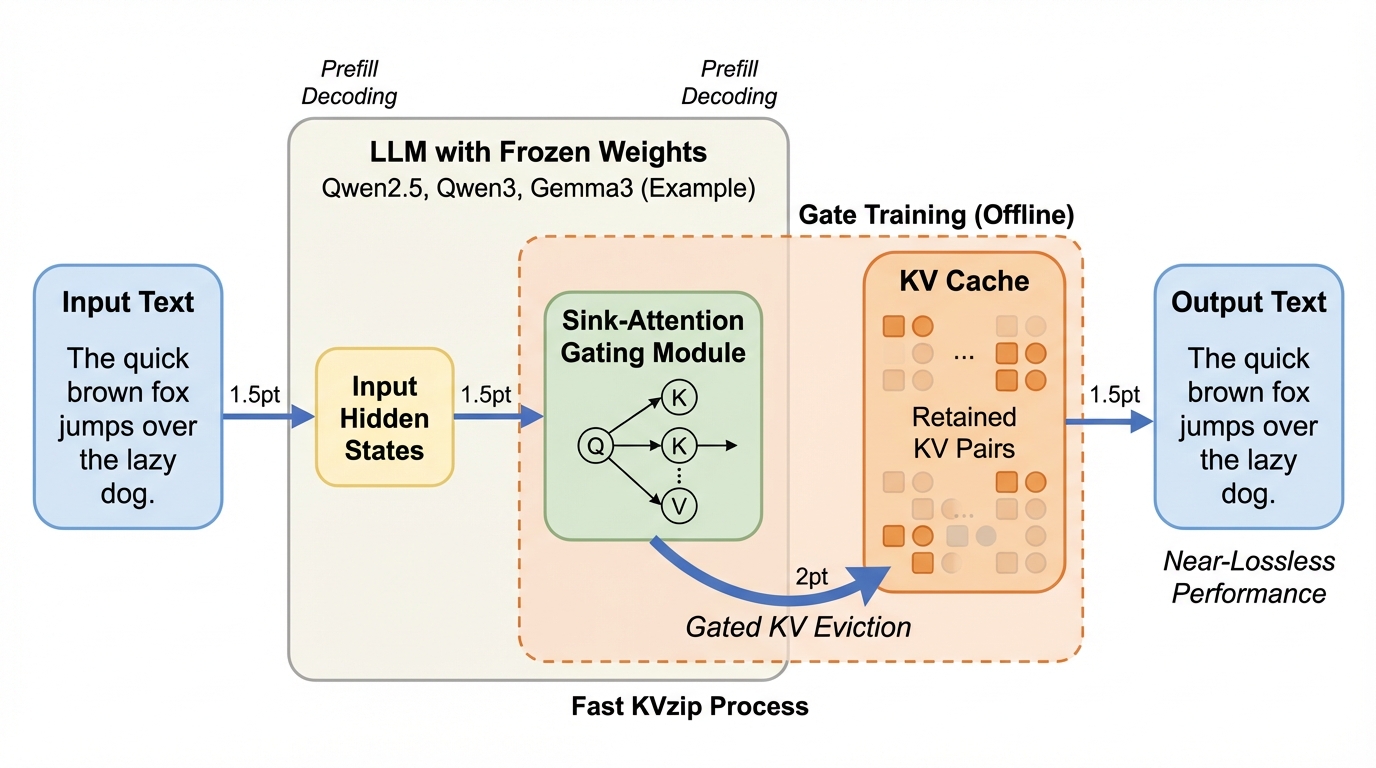
Fast KVzip:ゲート付きKV排除による効率的かつ高精度なLLM推論
大規模言語モデル(LLM)の推論において、文脈長に比例して増大するKVキャッシュのメモリ消費を劇的に抑えるため、軽量なゲート機構を用いて不要な情報を動的に排除する新手法「Fast KVzip」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)の推論において、文脈長に比例して増大するKVキャッシュのメモリ消費を劇的に抑えるため、軽量なゲート機構を用いて不要な情報を動的に排除する新手法「Fast KVzip」が提案されました。
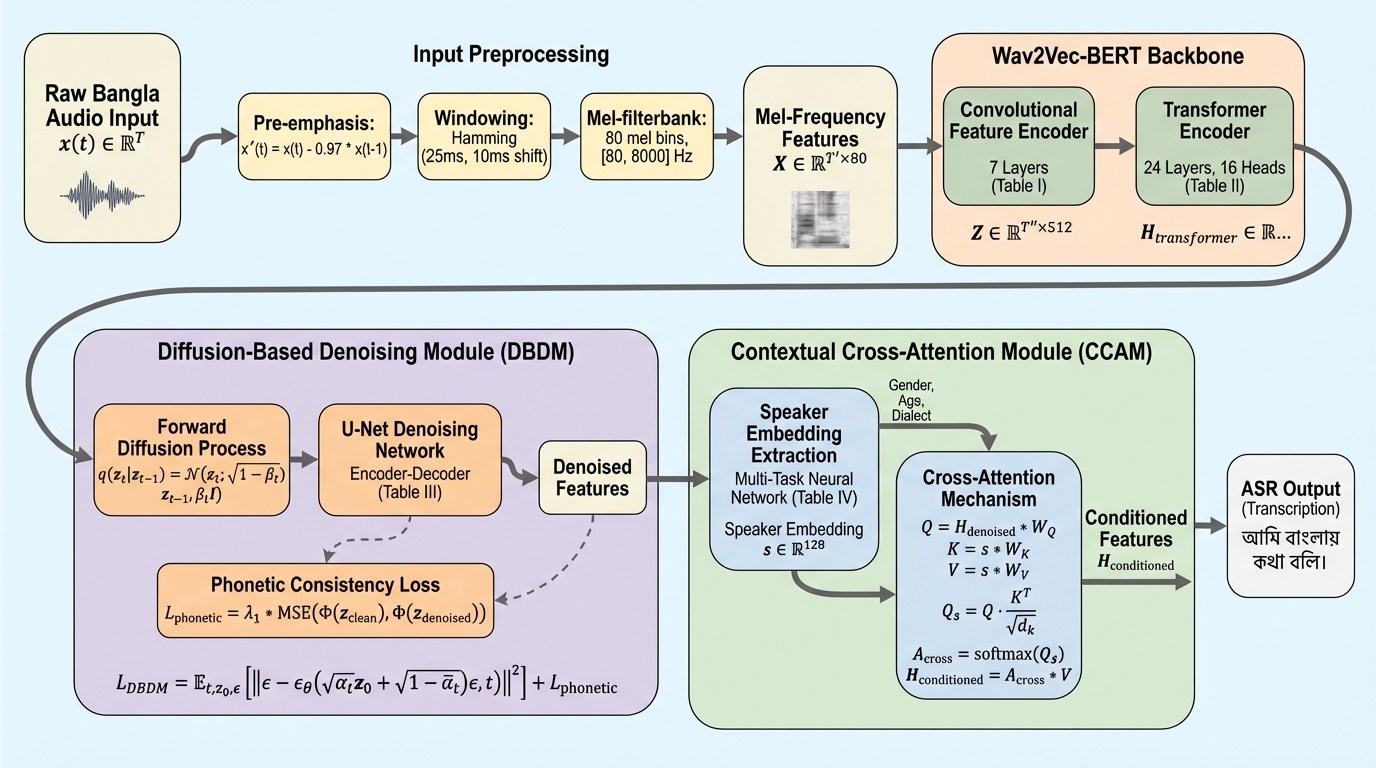
ベンガル語は2億5千万人以上の話者を抱えながら、音声認識(ASR)においてはデータが不足している低リソース言語であり、環境ノイズや多様な方言、複雑な音韻構造が実用化の大きな壁となっていました。本研究が提案するBanglaRobustNetは、Wav2Vec-BERTを基盤に、拡散モデルを用いたノイズ除去モジュールと話者特性を捉えるクロスアテンション機構を統合することで、音韻の正確性を保ちつつノイズ耐性を劇的に向上させています。評価の結果、従来のWhisperやWav2Vec-BERTを大幅に上回る精度を達成し、クリーンな環境で12%、ノイズ環境で18%、方言において15%の単語誤り率(WER)削減を実現し、リアルタイムでの推論効率も確保されています。
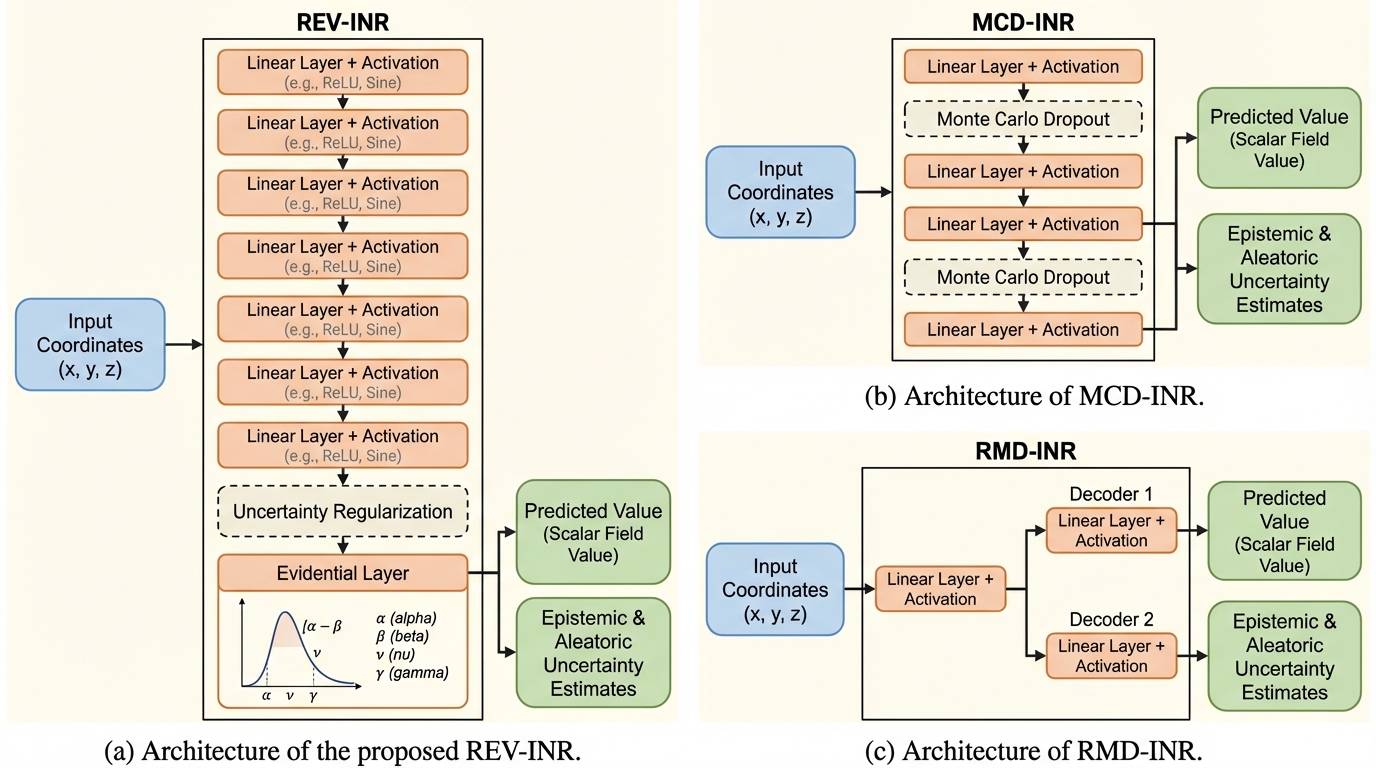
REV-INRは、大規模なボリュームデータをニューラルネットワークの重みとして効率的に圧縮・表現しつつ、一回の推論プロセスだけで予測値と「モデルの不確実性(エピステミック)」および「データの不確実性(アレアトリック)」という二種類の指標を同時に算出する画期的な手法である。
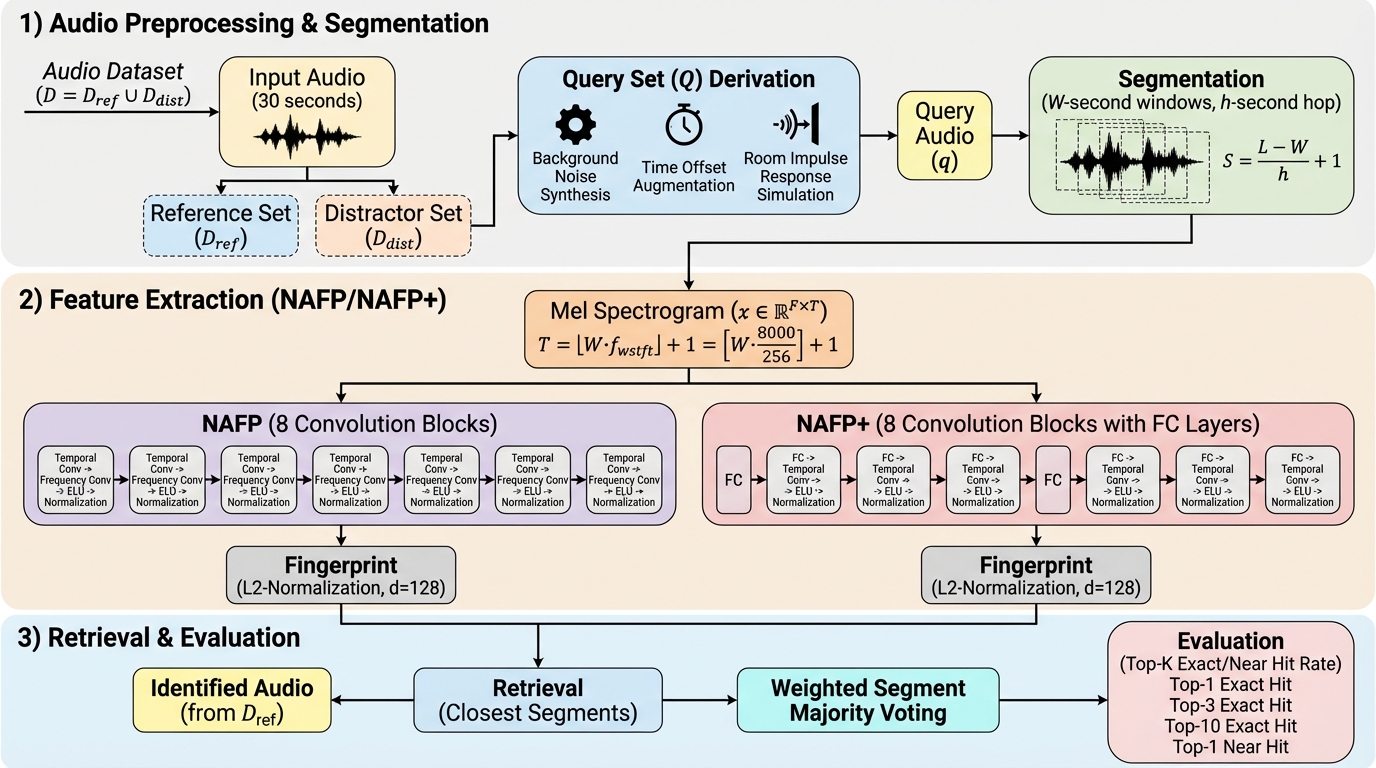
本研究は、音声指紋照合システムにおいて音声を切り出す際の「セグメント長」が照合精度に与える影響を、既存モデルを拡張したNAFP+を用いて詳細に調査したものです。 実験の結果、0.5秒という短いセグメント長が、特に3秒未満の短いクエリにおいて最も高い照合精度を達成し、クエリ長が4秒を超えると精度の向上が飽和する傾向が明らかになりました。 また、最適なセグメント長を提案する能力を大規模言語モデルで比較したところ、GPT-5-miniが実際の実験結果と最も合致する1秒前後の設定を一貫して推奨し、システム設計における高い信頼性を示しました。
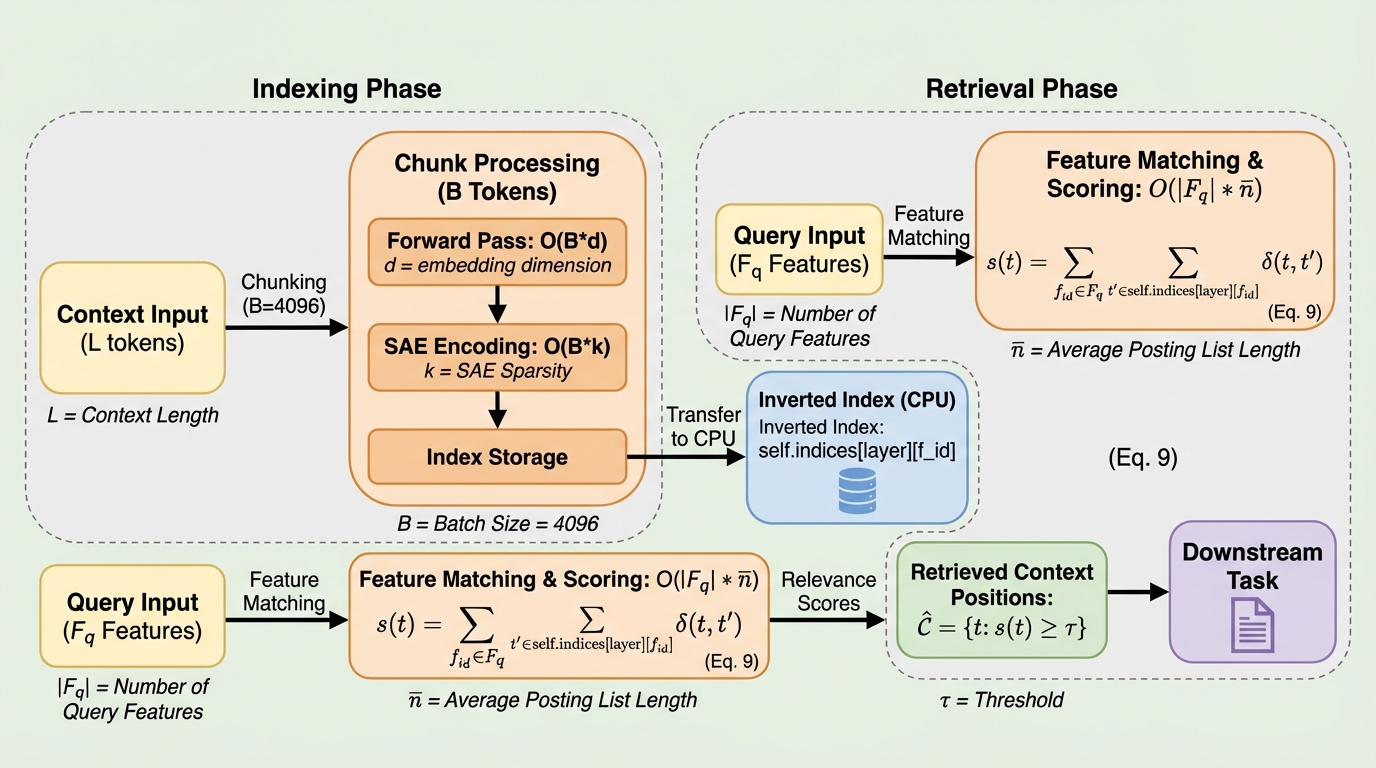
大規模言語モデルの長文脈推論において、GPUメモリの線形増加と外部検索(RAG)による意味的ミスマッチという二大課題を解決するため、モデル内部の信号を直接利用する「内因性検索」フレームワークであるS^3-Attentionを提案しました。
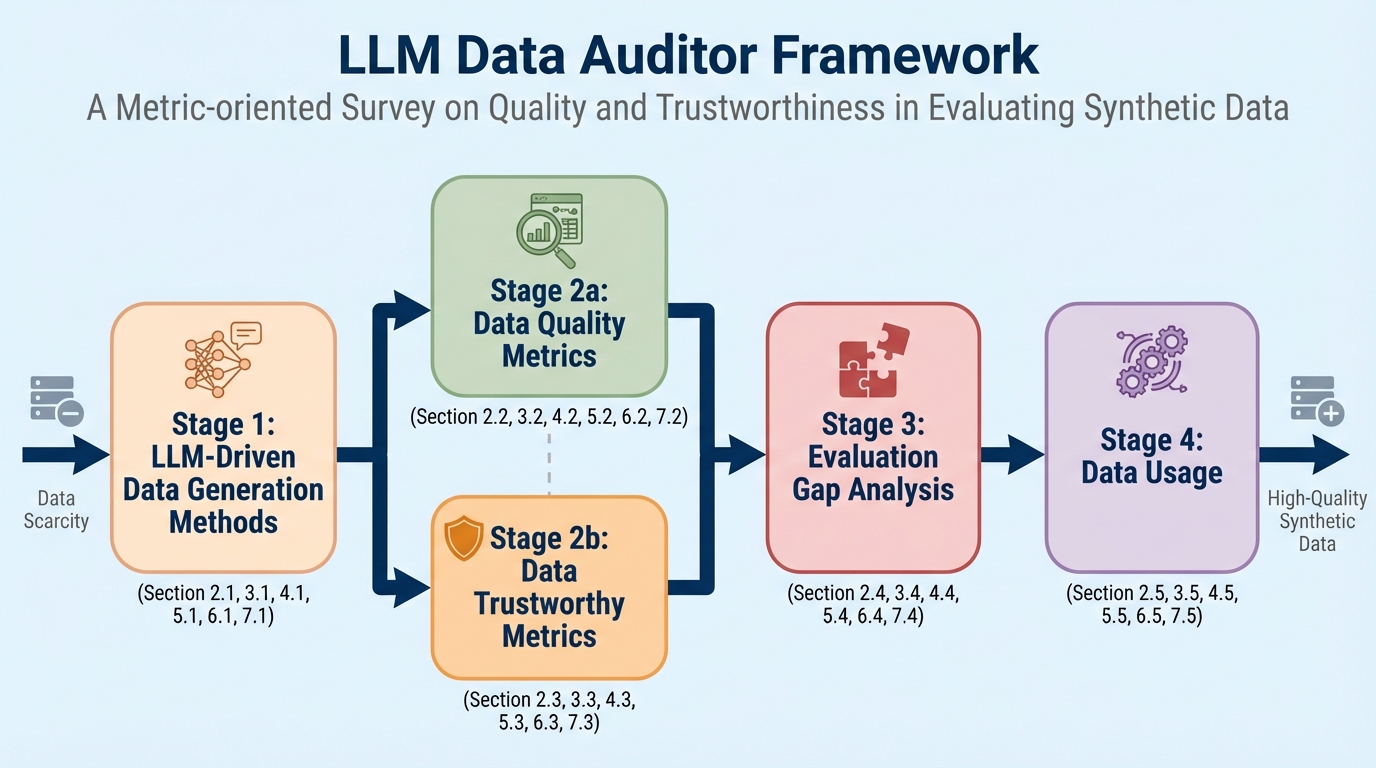
大規模言語モデル(LLM)による合成データ生成は、現実世界のデータ不足を解消し、モデルの学習や評価を効率化する強力な手段ですが、低品質なデータは「モデル崩壊」やプライバシー漏洩といった深刻なリスクを招く可能性があります。
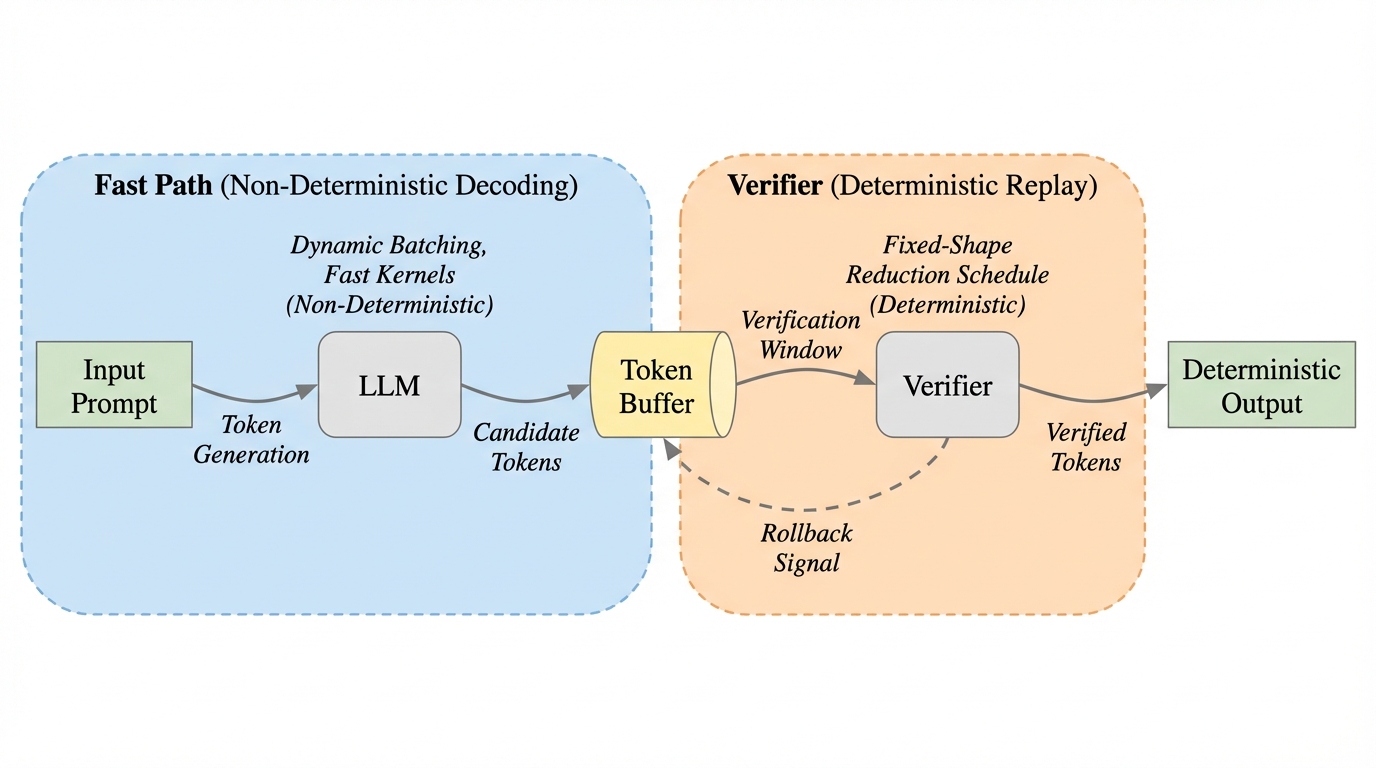
LLM推論における非決定性は、浮動小数点演算の非結合性と動的バッチ処理による計算順序の変化に起因しており、これを解決する既存のバッチ不変カーネル手法はスループットを最大56%低下させるなどの大きな性能上の代償を伴っていた。
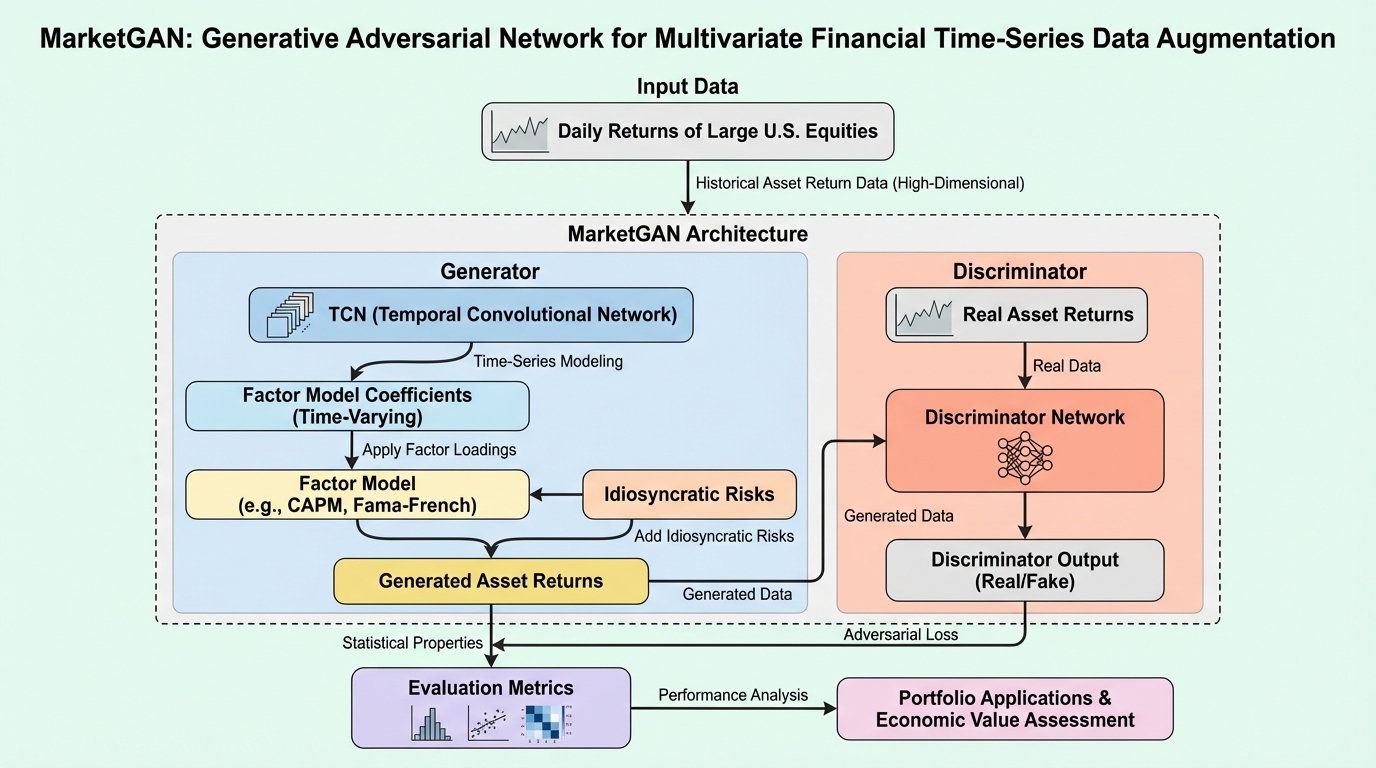
金融市場における高次元な資産収益率の生成は、利用可能なデータが限られているため、推定が極めて困難であるという課題に直面しています。 本研究で提案されたMarketGANは、資産価格モデルの要素構造を経済的なバイアスとして組み込み、時間的畳み込みネットワーク(TCN)を用いて動的な要因負荷量やボラティリティをモデル化する生成フレームワークです。 米国株式のデータを用いた検証では、従来のブートストラップ手法よりも高い精度で相関構造やテールの共動性を再現し、ポートフォリオ最適化においても優れた経済的価値を示すことが確認されました。
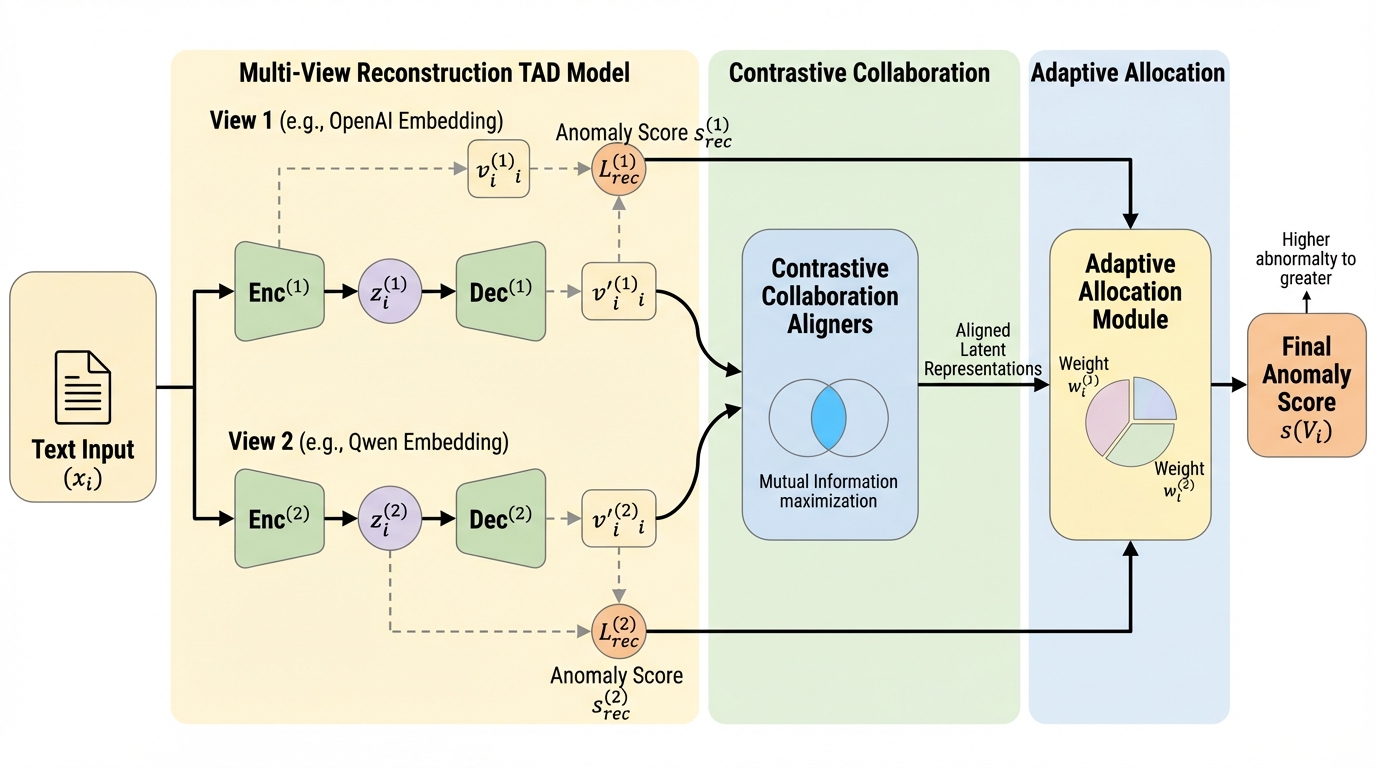
従来のテキスト異常検知は単一の埋め込みモデルに依存しており、特定のデータ分布への偏りや未知の異常に対する適応力の不足が大きな課題となっていましたが、本研究では複数の言語モデルの表現を統合する新しいフレームワークであるMCA²を提案しました。
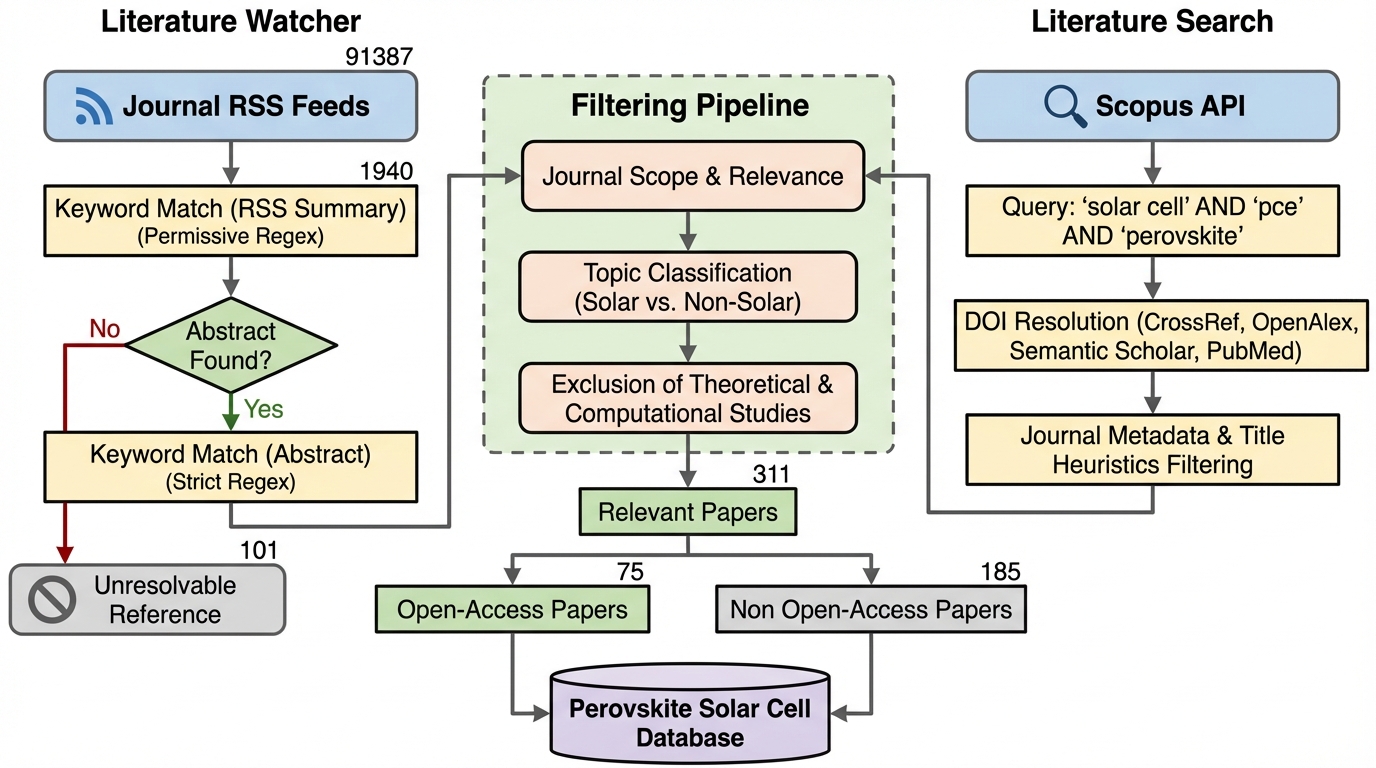
科学論文の指数関数的な増加により、手動でのデータ収集が限界に達し、主要なデータベースが2021年以降更新されないという深刻な知識の空白が生じていたが、本研究では大規模言語モデル(LLM)と物理的検証を統合した自律更新型データベース「PERLA」を開発した。