LLM-42:検証済み投機によるLLM推論における決定性の実現
LLM推論における非決定性は、浮動小数点演算の非結合性と動的バッチ処理による計算順序の変化に起因しており、これを解決する既存のバッチ不変カーネル手法はスループットを最大56%低下させるなどの大きな性能上の代償を伴っていた。
TL;DR(結論)
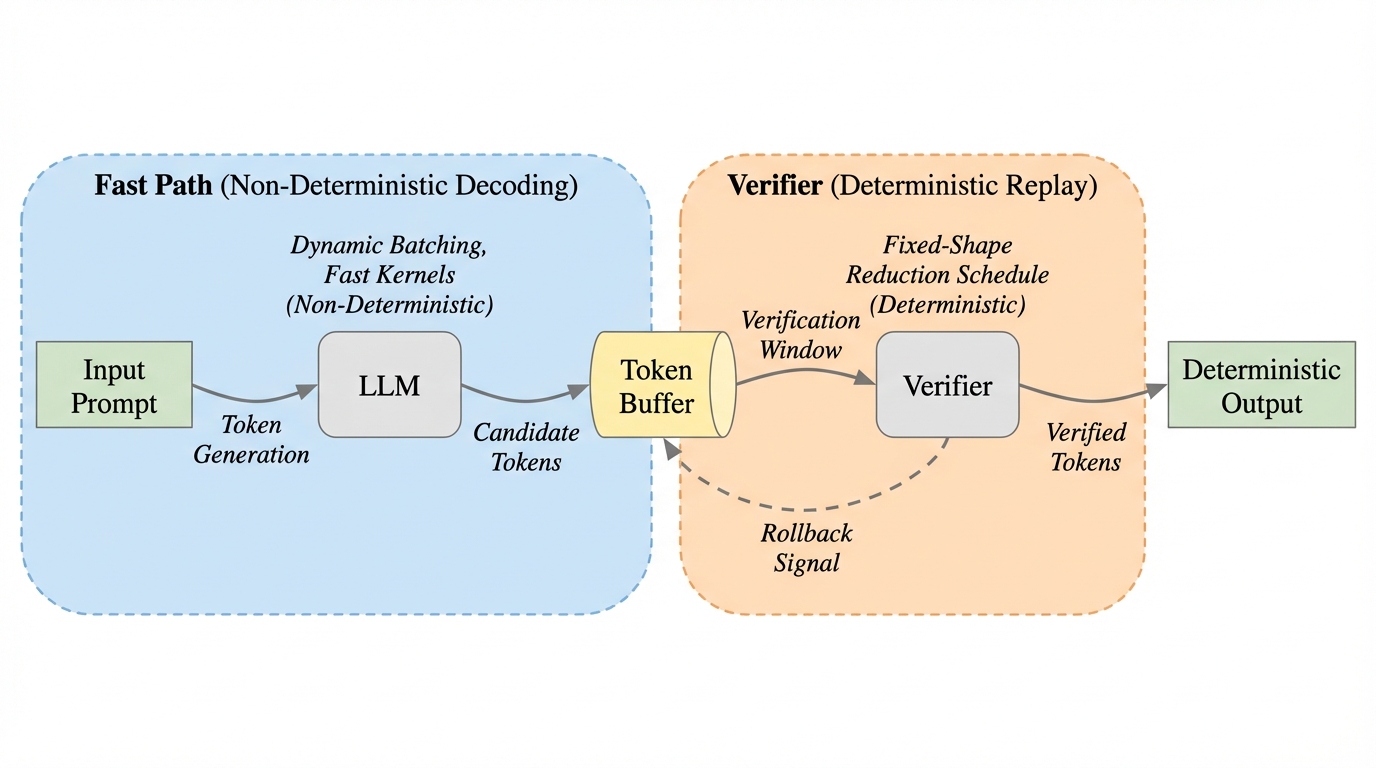
LLM推論における非決定性は、浮動小数点演算の非結合性と動的バッチ処理による計算順序の変化に起因しており、これを解決する既存のバッチ不変カーネル手法はスループットを最大56%低下させるなどの大きな性能上の代償を伴っていた。 本研究が提案する「LLM-42」は、投機的デコーディングの概念を応用し、高速な非決定論的パスでトークンを生成しながら、固定された計算スケジュールを持つ検証器で定期的にチェックとロールバックを行う新しいスケジューリング手法である。 このアプローチにより、既存の最適化されたGPUカーネルをそのまま再利用することが可能となり、決定性を必要とする特定のトラフィックに対してのみ、その割合に応じた最小限のオーバーヘッドで実行時の一貫性を保証することに成功した。
なぜこの問題か
大規模言語モデル(LLM)の推論において、同じプロンプトとサンプリング・パラメータを使用しても、実行ごとに異なる出力が得られる非決定性の問題が深刻化している。この現象の根本的な原因は、システムレベルにおける浮動小数点演算の非結合性と、推論効率を高めるための動的バッチ処理の組み合わせにある。具体的には、行列演算やアテンション、正規化などの主要なオペレータにおいて、GPUカーネルはバッチサイズに応じて計算の並列化戦略やリダクション(簡約)の順序を動的に変更する。浮動小数点の加算順序が変わると、微小な丸め誤差が生じ、それが自己回帰的なデコーディング過程で増幅され、最終的なトークン選択を変化させてしまうのである。 既存の対策として「バッチ不変計算」が提案されているが、これはすべてのトークンに対して一律の計算戦略を強制するため、GPU本来の並列性能を十分に引き出すことができない。例えば、小規模なバッチで有効な最適化手法であるスプリットK(split-K)戦略などが制限され、結果として推論スループットが大幅に低下するという課題があった。また、決定性を確保するために専用のカーネルを開発・維持するコストも、実用上の大きな障壁となっている。…
核心:何を提案したのか
本研究では、投機的デコーディングの概念を決定性の確保に応用した新しいスケジューリング手法「LLM-42」を提案する。LLM-42の核心は、トークンの生成プロセスと決定性の検証プロセスを分離し、デコード・検証・ロールバックというプロトコルを導入した点にある。具体的には、まず「高速パス」において、標準的な非決定論的カーネルを用いてトークンを迅速に生成する。この段階では動的バッチ処理による高いスループットを維持しつつ、生成されたトークンは暫定的な候補として扱われる。 次に、一定のウィンドウサイズごとに「検証器」がこれらの候補トークンを再実行し、実行時の一貫性が保たれているかを確認する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related