セグメント長は重要である:音声指紋照合の性能におけるセグメント長の研究
本研究は、音声指紋照合システムにおいて音声を切り出す際の「セグメント長」が照合精度に与える影響を、既存モデルを拡張したNAFP+を用いて詳細に調査したものです。 実験の結果、0.5秒という短いセグメント長が、特に3秒未満の短いクエリにおいて最も高い照合精度を達成し、クエリ長が4秒を超えると精度の向上が飽和する傾向が明らかになりました。 また、最適なセグメント長を提案する能力を大規模言語モデルで比較したところ、GPT-5-miniが実際の実験結果と最も合致する1秒前後の設定を一貫して推奨し、システム設計における高い信頼性を示しました。
TL;DR(結論)
本研究は、音声指紋照合システムにおいて音声を切り出す際の「セグメント長」が照合精度に与える影響を、既存モデルを拡張したNAFP+を用いて詳細に調査したものです。 実験の結果、0.5秒という短いセグメント長が、特に3秒未満の短いクエリにおいて最も高い照合精度を達成し、クエリ長が4秒を超えると精度の向上が飽和する傾向が明らかになりました。 また、最適なセグメント長を提案する能力を大規模言語モデルで比較したところ、GPT-5-miniが実際の実験結果と最も合致する1秒前後の設定を一貫して推奨し、システム設計における高い信頼性を示しました。
なぜこの問題か
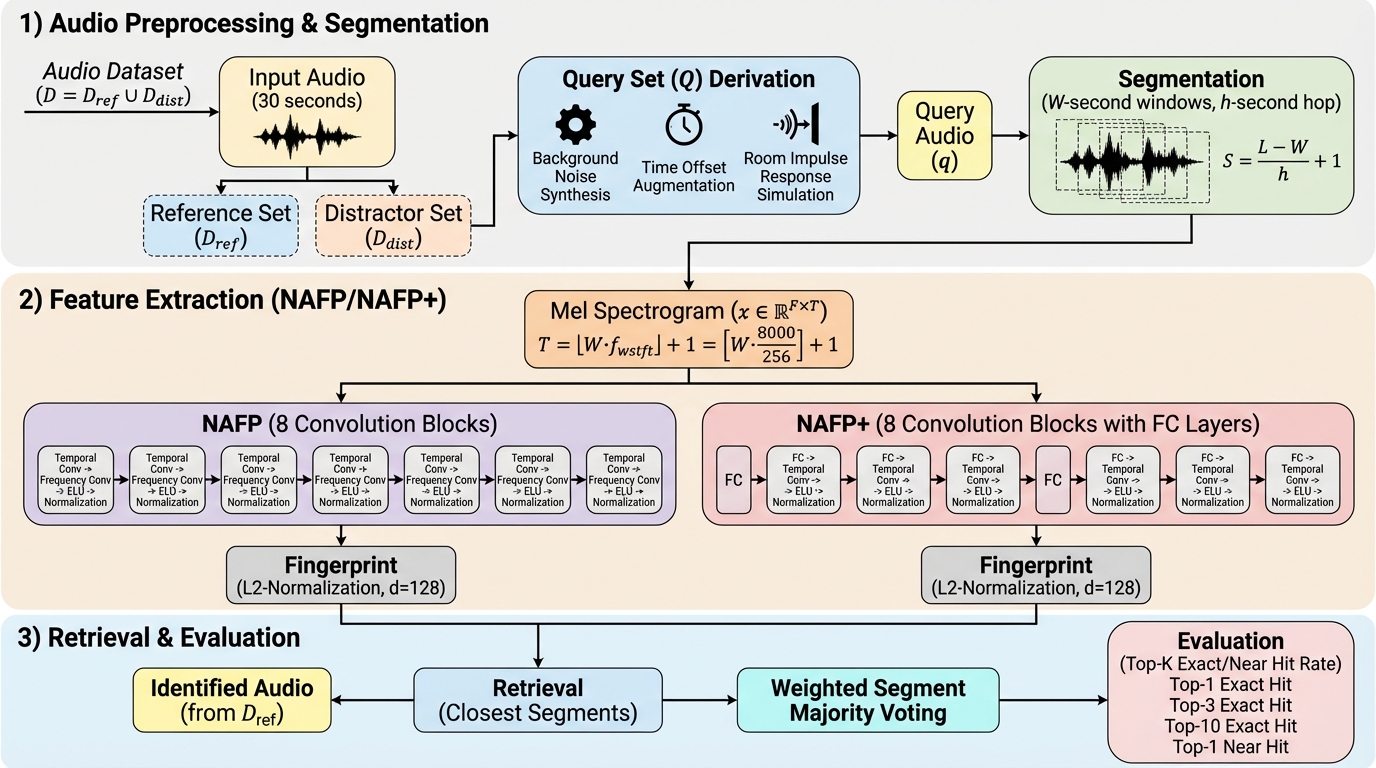
音声セグメンテーションは、音声指紋照合、話者ダイアライゼーション、キーワード検出、音声翻訳など、多岐にわたる音声処理タスクにおいて広く採用されている基盤技術です。それぞれのタスクには慣習的に用いられるセグメント長の範囲が存在しており、例えば話者識別では3秒、キーワード検出では0.5秒から1.0秒、話者ダイアライゼーションでは1.5秒から3秒が一般的とされています。自動音声認識(ASR)においては、コンテキストウィンドウとして5秒から30秒、場合によっては数時間に及ぶセグメンテーションが行われることもあります。このように、セグメント長の設定がタスクの性能を左右する決定的な要因であることは暗黙的に理解されていますが、音声指紋照合の分野においては、その影響がこれまで十分に調査されてきませんでした。 現代のニューラルネットワークを用いた音声指紋照合手法の多くは、短く固定された時間の音声セグメントを処理しますが、その長さの選択は経験則に基づいていることが多く、深い検討がなされていないのが現状です。…
核心:何を提案したのか
本研究では、既存のニューラル音声指紋照合モデルであるNAFP(Neural Audio FingerPrinter)をベースに、異なるセグメント長に適応可能なモデルのバリアントとして「NAFP+」を提案しました。従来のNAFPは、学習段階とクエリ段階の両方で1秒のセグメンテーションを適用することを前提として設計されています。これに対し、提案されたNAFP+は、0.5秒、1秒、2秒といった多様なセグメント長(W)を柔軟に扱えるように設計変更が加えられています。具体的には、NAFPの畳み込みブロックの構成を大きく変えることなく、各ブロックの前にELU活性化関数を備えた全結合層を追加するという修正を行っています。 この全結合層の追加により、入力される音声フレーム数(T)がセグメント長によって異なる場合でも、それを固定された数(T0=32)に正規化して後続の処理に渡すことが可能になりました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related