単一の視点を超えて:マルチビュー言語表現によるテキスト異常検知
従来のテキスト異常検知は単一の埋め込みモデルに依存しており、特定のデータ分布への偏りや未知の異常に対する適応力の不足が大きな課題となっていましたが、本研究では複数の言語モデルの表現を統合する新しいフレームワークであるMCA²を提案しました。
TL;DR(結論)
従来のテキスト異常検知は単一の埋め込みモデルに依存しており、特定のデータ分布への偏りや未知の異常に対する適応力の不足が大きな課題となっていましたが、本研究では複数の言語モデルの表現を統合する新しいフレームワークであるMCA²を提案しました。 この手法は、各視点での再構成誤差を活用するだけでなく、対照的学習によって異なるモデル間の整合性を強化し、さらにデータの特性に応じて各モデルの寄与度をサンプル単位で動的に調整する適応的割り当てモジュールを導入しています。 広範な実験の結果、10種類のベンチマークデータセットにおいて既存の最先端手法を上回る検知精度を達成し、異なるアーキテクチャのモデルを組み合わせることで単一モデルの限界を克服できることを実証しました。
なぜこの問題か
テキストデータにおける異常検知(TAD)は、現代のデジタル社会において極めて重要な役割を担っています。例えば、SNS上での有害なコンテンツのモデレーション、巧妙化するフィッシング詐欺の検出、あるいはECサイトにおけるスパムレビューの排除など、その応用範囲は多岐にわたります。近年の主流なアプローチは、強力な言語モデルを用いてテキストをベクトル形式の「埋め込み」に変換し、その後に汎用的な異常検知アルゴリズムを適用する二段階の構成をとっています。しかし、この手法には根本的な限界が存在します。 第一に、単一の埋め込みモデルを使用する場合、そのモデルが事前学習に使用したコーパスの性質や言語的特徴に強く依存してしまうという問題があります。特定のドメインや文体には強くても、未知の領域や特殊な異常パターンに対しては、十分な表現力を発揮できないことが少なくありません。第二に、データの分布がモデルごとに異なるため、どの検知アルゴリズムがその埋め込みと最も相性が良いかを事前に判断することが困難です。結果として、最適な組み合わせを見つけるために膨大な試行錯誤が必要となり、実用上の大きな障壁となっています。…
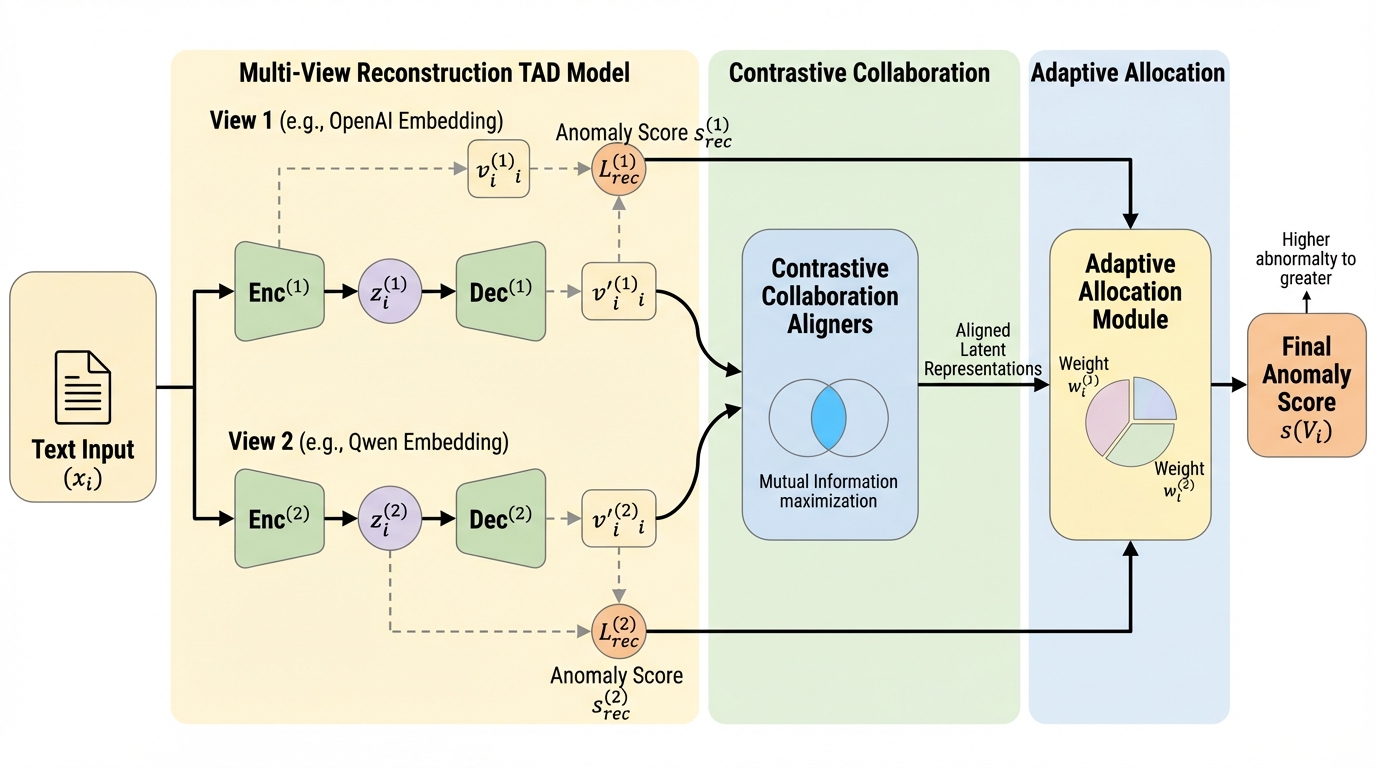
核心:何を提案したのか
本論文では、複数の言語モデルから得られる埋め込み表現を「マルチビュー(多角的な視点)」として扱い、それらを統合して異常を特定する新しいフレームワーク「MCA²」を提案しています。このフレームワークの核心は、単に複数のモデルの出力を平均化するのではなく、各モデルが持つ情報の補完性を能動的に活用し、データセットや個々のサンプルに応じて最適な判断を下す仕組みを構築した点にあります。 MCA²は、主に三つの高度なコンポーネントで構成されています。一つ目は、各視点ごとに独立して配置された「マルチビュー再構成モデル」です。これは、正常なデータのパターンを各埋め込み空間において学習し、そこから外れるものを異常として識別する基盤となります。二つ目は「対照的共同作業モジュール」であり、異なるモデル間での情報の整合性を高める役割を果たします。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related