BanglaRobustNet:堅牢なベンガル語音声認識のためのハイブリッドなノイズ除去アテンションアーキテクチャ
ベンガル語は2億5千万人以上の話者を抱えながら、音声認識(ASR)においてはデータが不足している低リソース言語であり、環境ノイズや多様な方言、複雑な音韻構造が実用化の大きな壁となっていました。本研究が提案するBanglaRobustNetは、Wav2Vec-BERTを基盤に、拡散モデルを用いたノイズ除去モジュールと話者特性を捉えるクロスアテンション機構を統合することで、音韻の正確性を保ちつつノイズ耐性を劇的に向上させています。評価の結果、従来のWhisperやWav2Vec-BERTを大幅に上回る精度を達成し、クリーンな環境で12%、ノイズ環境で18%、方言において15%の単語誤り率(WER)削減を実現し、リアルタイムでの推論効率も確保されています。
TL;DR(結論)
ベンガル語は2億5千万人以上の話者を抱えながら、音声認識(ASR)においてはデータが不足している低リソース言語であり、環境ノイズや多様な方言、複雑な音韻構造が実用化の大きな壁となっていました。本研究が提案するBanglaRobustNetは、Wav2Vec-BERTを基盤に、拡散モデルを用いたノイズ除去モジュールと話者特性を捉えるクロスアテンション機構を統合することで、音韻の正確性を保ちつつノイズ耐性を劇的に向上させています。評価の結果、従来のWhisperやWav2Vec-BERTを大幅に上回る精度を達成し、クリーンな環境で12%、ノイズ環境で18%、方言において15%の単語誤り率(WER)削減を実現し、リアルタイムでの推論効率も確保されています。
なぜこの問題か
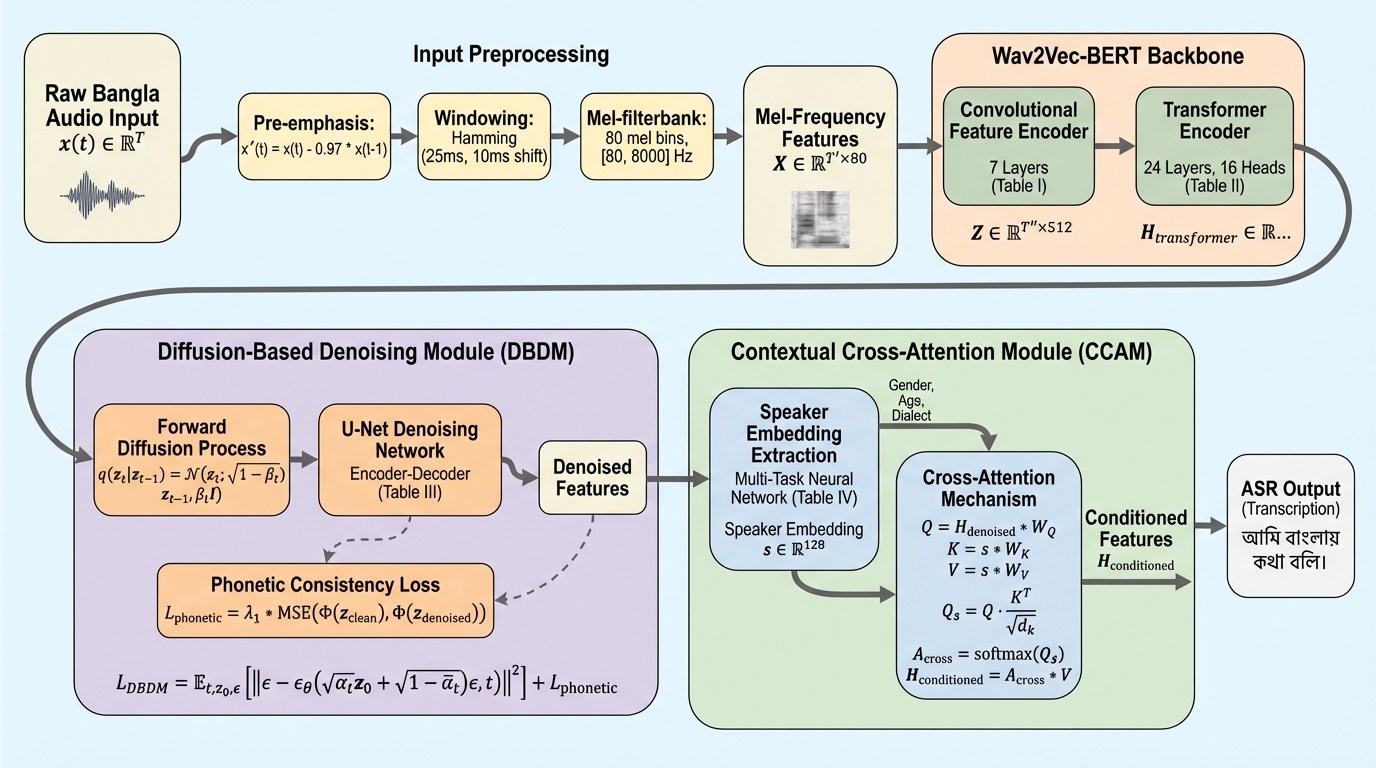
ベンガル語は世界で最も広く話されている言語の一つですが、自動音声認識(ASR)の研究においては依然として過小評価されており、特にノイズの多い環境や話者の多様性に対応する技術が不足しています。英語などの主要言語が10,000時間を超えるラベル付きデータを有しているのに対し、ベンガル語は約500時間程度しかなく、このデータ不均衡が堅牢なシステムの開発を妨げる要因となっています。また、ベンガル語特有の複雑な音韻構造、例えば有気音(/ph/, /th/, /kh/)や摩擦音、鼻母音などの識別は、既存のモデルにとって非常に困難な課題です。 既存の最先端モデルであるWav2Vec 2.0やWhisperは、多言語設定では優れた性能を発揮しますが、現実世界のノイズが多いベンガル語環境では単語誤り率(WER)が30%を超えるなど、実用性に欠ける場面が多く見られます。これは、既存モデルがベンガル語固有の音韻的特徴や、話者の性別、年齢、方言による変動を効果的に捉えきれていないためです。…
核心:何を提案したのか
本論文では、これらの課題を解決するために「BanglaRobustNet」というハイブリッドなノイズ除去アテンションアーキテクチャを提案しています。このモデルは、自己教師あり学習モデルであるWav2Vec-BERTをバックボーンとして採用し、そこに二つの革新的なモジュールを統合しています。一つ目は「拡散ベースのノイズ除去モジュール(DBDM)」であり、二つ目は「コンテキストクロスアテンションモジュール(CCAM)」です。これらにより、音響的な堅牢性と話者への適応性を同時に実現しています。 BanglaRobustNetの設計思想は、三つの主要な原則に基づいています。第一に「音韻の保存」であり、ノイズ除去の過程でベンガル語特有の有気音や鼻母音などの重要な音素が消えないように設計されています。第二に「話者適応性」であり、話者ごとの再学習を必要とせずに、性別、年齢、方言などの多様な特性に動的に適応します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related