Fast KVzip:ゲート付きKV排除による効率的かつ高精度なLLM推論
大規模言語モデル(LLM)の推論において、文脈長に比例して増大するKVキャッシュのメモリ消費を劇的に抑えるため、軽量なゲート機構を用いて不要な情報を動的に排除する新手法「Fast KVzip」が提案されました。
TL;DR(結論)
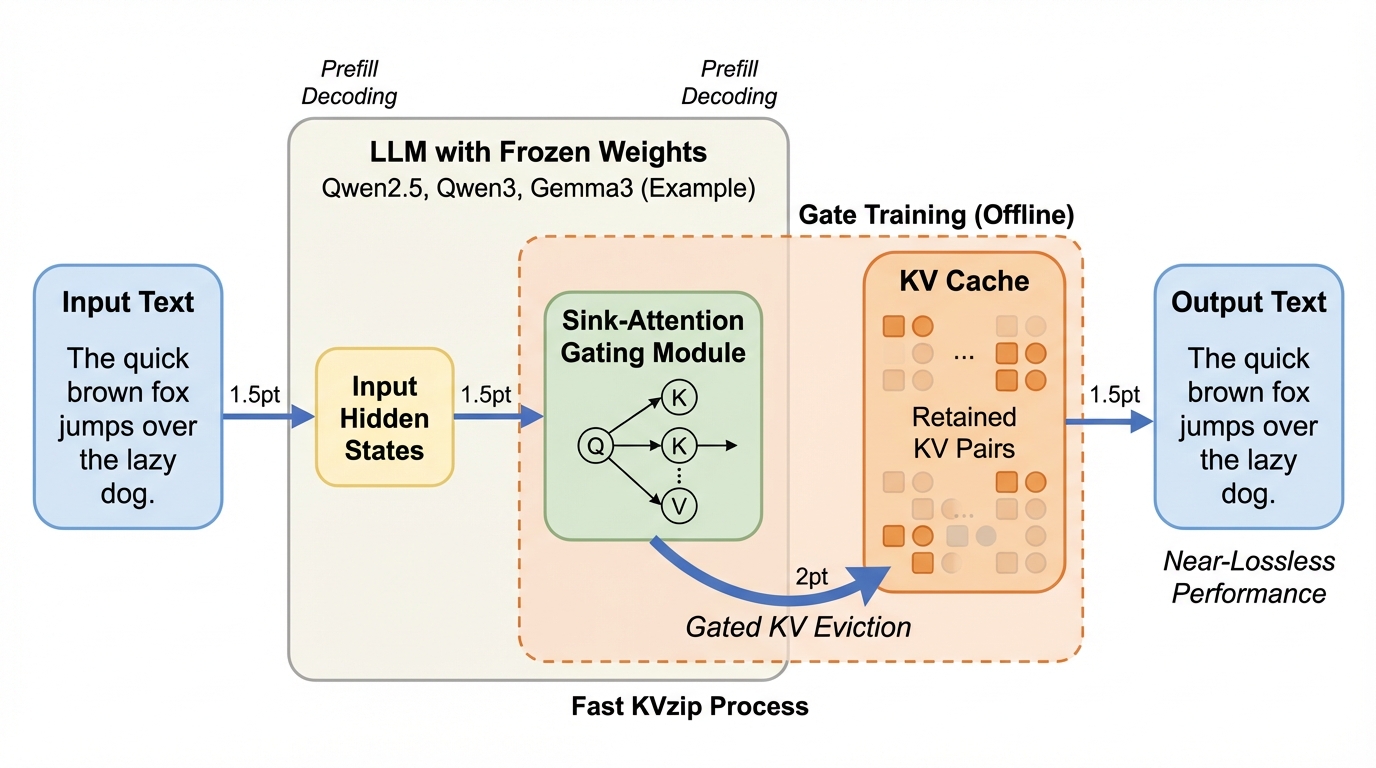
大規模言語モデル(LLM)の推論において、文脈長に比例して増大するKVキャッシュのメモリ消費を劇的に抑えるため、軽量なゲート機構を用いて不要な情報を動的に排除する新手法「Fast KVzip」が提案されました。この手法は、モデルの重みを固定したまま、入力の隠れ状態から各KVペアの将来的な重要度を予測する「シンクアテンション型ゲート」を学習することで、最大70%のキャッシュを削減しながらも、ほぼ損失のない精度を維持することに成功しています。Qwen2.5やQwen3、Gemma3といった最新のモデル群を用いた検証により、17万トークンに及ぶ長文脈理解や数学的推論、コード解析などの多様なタスクにおいて、計算コストを最小限に抑えつつ、推論時のピークメモリとプレフィル時間を大幅に削減できることが実証されました。
なぜこの問題か
Transformerベースの大規模言語モデルは、長い文脈の処理や高度な推論において革新的な成果を収めていますが、その根幹を支えるアテンション機構にはメモリ使用量に関する深刻な課題が存在します。推論を効率化するために過去の計算結果を保存するKVキャッシュは、入力されるシーケンスの長さに応じてメモリ使用量が線形に増加するため、長い文脈を扱う際の最大のボトルネックとなっています。既存のKVキャッシュ圧縮技術には、計算コストを抑えようとするとモデルの性能が著しく低下し、逆に精度を維持しようとすると圧縮のための計算オーバーヘッドが膨大になるという、解決の難しいトレードオフがありました。 例えば、先行研究であるKVzipは精度の面では非常に優れていますが、文脈の再構成プロセスに多大な計算資源を必要とし、プレフィル段階での計算量が実質的に倍増するという課題を抱えていました。このような計算負荷は、低遅延が求められる実際のデプロイ環境において大きな障害となります。また、推論時にアテンションの疎性を利用する手法は、現在の入力に対して過学習しやすく、将来のクエリに対して汎用性を欠く傾向があります。…
核心:何を提案したのか
本論文では、従来の再構成ベースの手法が抱えていた非効率性を解消する、高速かつ高精度なKVキャッシュ排除手法「Fast KVzip」を提案しています。この手法の核心となる洞察は、特定のKVペアが将来的にどれだけ利用されるかという重要度は、入力された隠れ状態から直接デコードできる「固有の属性」であるという点にあります。この知見に基づき、モデルの各アテンション層に軽量なゲートモジュールを統合し、順伝播の過程でKVペアの重要度を直接評価する仕組みを導入しました。これにより、従来のような複雑な再計算を必要とせず、効率的なキャッシュ管理が可能になります。 Fast KVzipの大きな特徴は、元のLLMの重みを一切変更せずに凍結したまま、ゲートパラメータのみを学習させる点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related