S^3-Attention:メモリ制約下における長文脈推論のためのアテンション整列型内因性検索
大規模言語モデルの長文脈推論において、GPUメモリの線形増加と外部検索(RAG)による意味的ミスマッチという二大課題を解決するため、モデル内部の信号を直接利用する「内因性検索」フレームワークであるS^3-Attentionを提案しました。
TL;DR(結論)
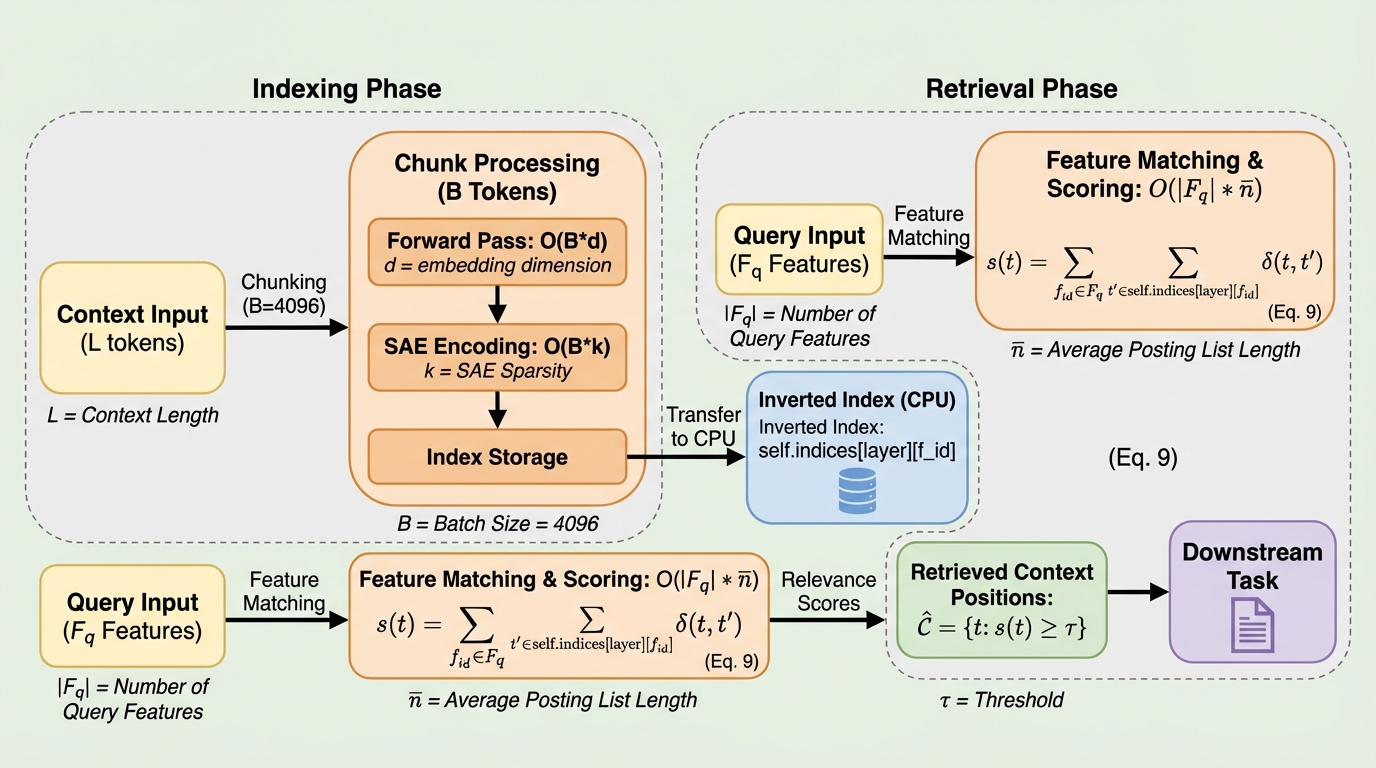
大規模言語モデルの長文脈推論において、GPUメモリの線形増加と外部検索(RAG)による意味的ミスマッチという二大課題を解決するため、モデル内部の信号を直接利用する「内因性検索」フレームワークであるS^3-Attentionを提案しました。 軽量なスパースオートエンコーダ(SAE)を用いてアテンション状態を離散的な特徴量にデコードし、CPU上に転置インデックスを構築することで、GPUメモリ消費をコンテキスト長に関わらずチャンクサイズに依存した一定(O(1))の状態に抑えることに成功しました。 検証の結果、Llama-3-8B等のモデルで全文脈推論の99%以上の精度を維持しつつ、情報密度が高いタスクでは不要なノイズを除去するデノイジング効果によって全文脈推論を上回る性能を示すなど、効率性と精度の両立を証明しました。
なぜこの問題か
大規模言語モデル(LLM)が複雑な認知タスクの標準的なインターフェースへと進化する中で、処理対象は単一の文書から膨大なレポート群、大規模なコードベース、そして長い会話履歴へと急速に拡大しています。数百万トークン規模の文脈を処理する能力は、次世代のAIシステムにおける基本的な要件となっていますが、理論的な処理能力と実際のデプロイ効率の間には依然として深刻な隔たりが存在します。既存の対策として、継続学習やアーキテクチャの変更による文脈窓の拡張が行われてきましたが、単に窓を広げるだけでは信頼性の高い推論は保証されません。全文脈を対象とした推論は、自己アテンションの計算コストが二次関数的に増大し、キー・バリュー(KV)キャッシュが入力長に応じて線形に増加するため、GPUメモリを急速に飽和させてしまうという物理的な限界があります。 また、現実世界の長い入力データは情報の密度が極めて低く、特定の予測に対して因果的な影響を与えるのはごく一部のトークンに過ぎないという特性があります。すべてのトークンに対して一律に注意を向ける素朴なアプローチは、重要な証拠を希釈させ、無関係な情報による混乱を増幅させる傾向があります。…
核心:何を提案したのか
本研究は、GPUメモリが主要なボトルネックとなり、かつ因果的な証拠が疎に存在する設定に特化した新しいフレームワーク「S^3-Attention(Sparse & Semantic Streaming Attention)」を提案しました。この手法の核心は、長文脈推論をストリーミング形式のアテンション整列型検索プロセスへと変換することにあります。最大の特徴は、モデル内部で既に計算されている一時的なキー(Key)およびクエリ(Query)の投影状態を、軽量な「Top-k スパースオートエンコーダ(SAE)」を用いて、解釈可能かつ検索可能な離散的スパース特徴量へとデコードする点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related