LLMデータ監査官:合成データ評価における品質と信頼性に関する指標指向のサーベイ
大規模言語モデル(LLM)による合成データ生成は、現実世界のデータ不足を解消し、モデルの学習や評価を効率化する強力な手段ですが、低品質なデータは「モデル崩壊」やプライバシー漏洩といった深刻なリスクを招く可能性があります。
TL;DR(結論)
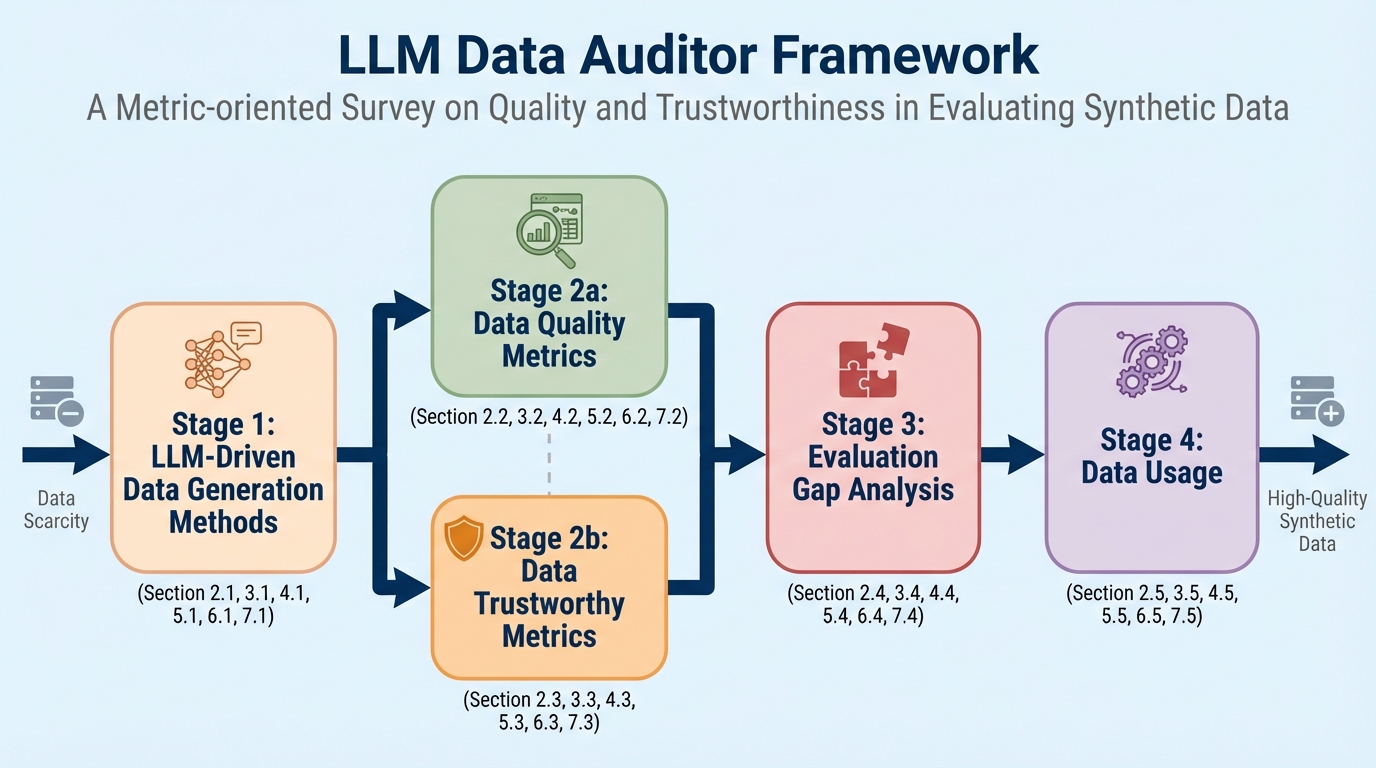
大規模言語モデル(LLM)による合成データ生成は、現実世界のデータ不足を解消し、モデルの学習や評価を効率化する強力な手段ですが、低品質なデータは「モデル崩壊」やプライバシー漏洩といった深刻なリスクを招く可能性があります。本研究では、テキスト、論理推論、表形式、半構造化、視覚、エージェントの6つの主要なモダリティを横断的に評価するための包括的な「LLM Data Auditor」フレームワークを提案し、データの真の価値を多角的に監査する体系を確立しました。 従来の評価が「学習後のモデル性能」という外在的な指標に依存していたのに対し、本フレームワークはデータそのものが持つ「品質(妥当性・忠実度・有用性)」と「信頼性(安全性・誠実性・公平性等)」を直接測定する内在的評価への転換を強く提唱しています。これにより、データがモデルに投入される前の段階で、その健全性を厳格にキュレーションするための具体的な指針が示されました。 膨大な文献調査を通じて、現在の研究がタスク性能の向上に偏り、安全性やプライバシーの評価が著しく不足しているという「評価のギャップ」を特定しました。本サーベイは、単なる手法の羅列に留まらず、マルチモーダルな合成データの生成から評価、実用的な活用に至るまでの全プロセスをカバーする戦略的なガイドラインを提供し、信頼性の高い人工知能開発のための新たなロードマップを提示しています。
なぜこの問題か
高品質なデータは現代の人工知能開発における生命線ですが、インターネット上の公開データなどの現実世界のソースは急速に枯渇しつつあり、これがモデルのさらなる進化を妨げる大きな障壁となっています。この課題を解決するために、大規模言語モデルを活用して人工的にデータを生成する「合成データ」の活用が新たなパラダイムとして注目されていますが、生成されたデータの質をどのように保証し、評価するかという点が極めて重要な課題として浮上しています。もし、低品質なデータや誤った情報、あるいはバイアスを含むデータを学習に使用し続けると、モデルが本来持っていた能力を失い、世代を重ねるごとに知能が劣化していく「モデル崩壊(model collapse)」という現象が起こることが理論的および実験的に示されています。 また、合成データの生成プロセスにおいて、元の学習データに含まれていた個人を特定できる情報や機密情報が意図せず再現され、漏洩してしまうプライバシー上のリスクも無視できません。…
核心:何を提案したのか
本研究は、評価の主眼をモデルの性能からデータそのものの特性へと根本的に転換させる「LLM Data Auditor」という包括的なフレームワークを提案しました。このフレームワークは、現代のAI研究における主要な6つのモダリティ、すなわちテキスト、数学的・論理的推論、表形式データ、グラフやログなどの半構造化データ、画像とテキストの融合で…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related