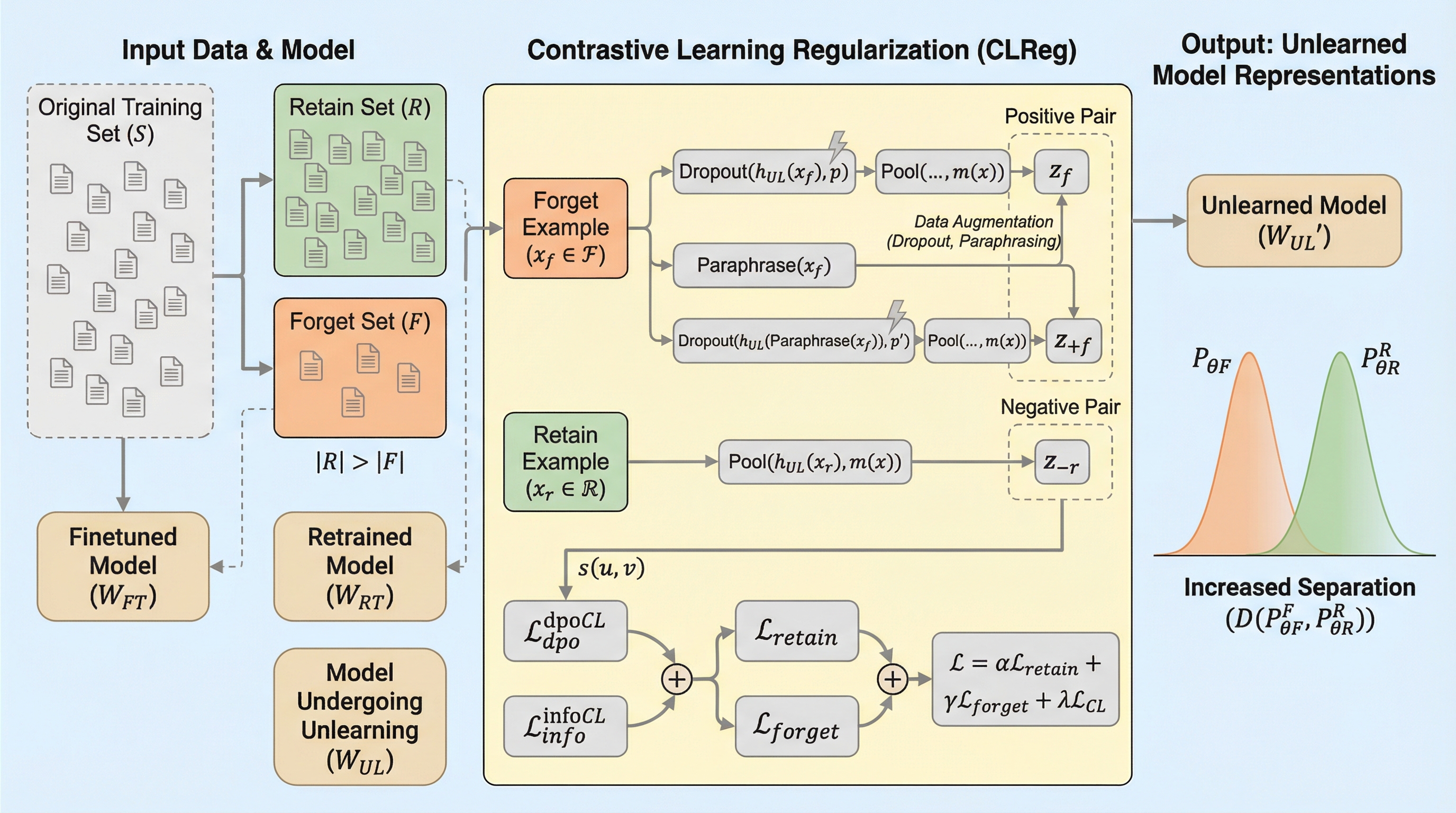
LogitsからLatentsへ:LLMアンラーニングのための対照的表現シェーピング
大規模言語モデル(LLM)のアンラーニングにおいて、従来の出力確率(Logits)を調整する手法は、忘却すべき概念を内部表現(Latents)に残存させ、保持すべき知識と絡み合わせる「抑制」に留まるという課題があった。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)のアンラーニングにおいて、従来の出力確率(Logits)を調整する手法は、忘却すべき概念を内部表現(Latents)に残存させ、保持すべき知識と絡み合わせる「抑制」に留まるという課題があった。
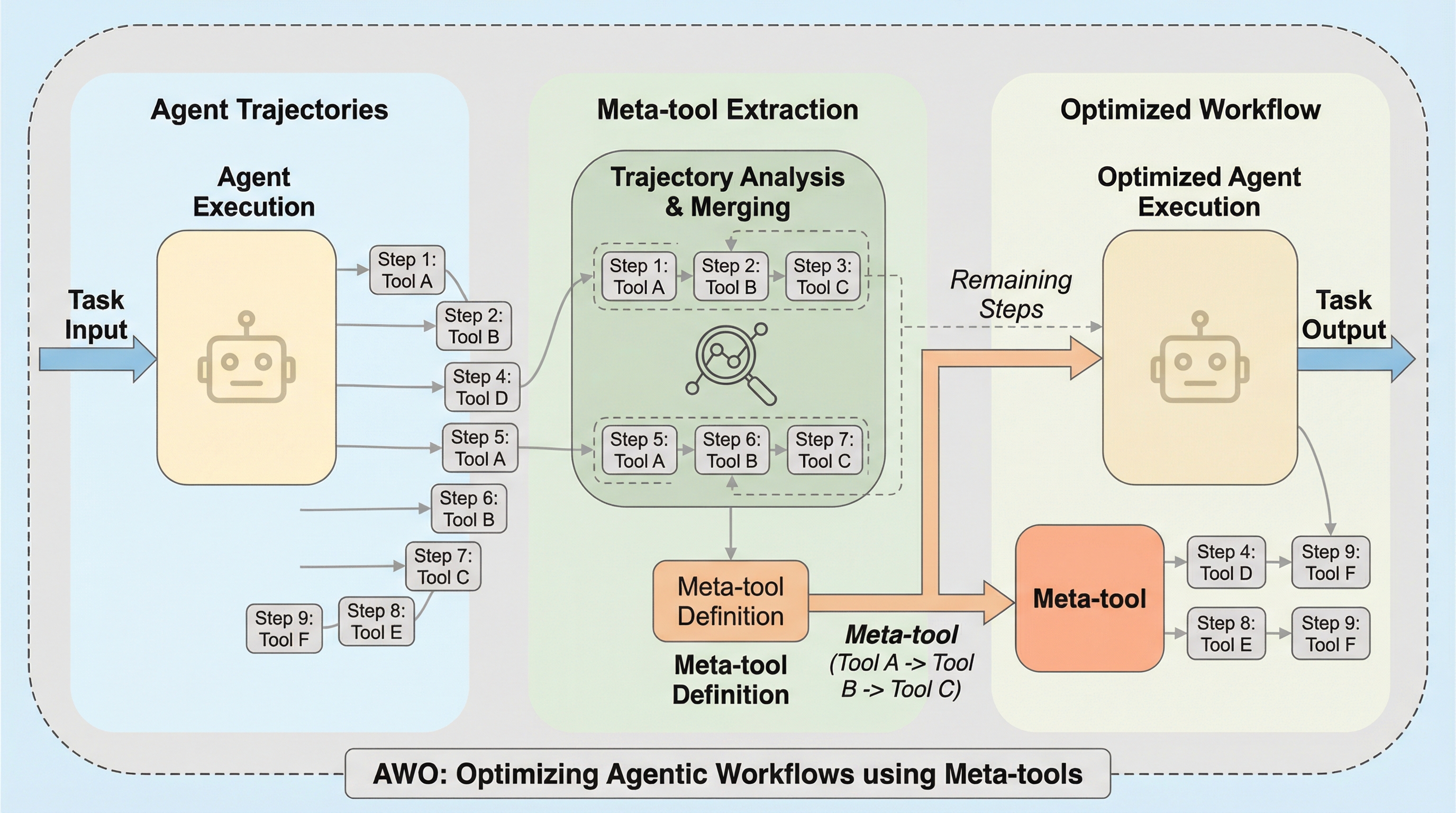
エージェント型AIは大規模言語モデル(LLM)が推論とツール実行を繰り返すことで複雑な課題を解決しますが、反復的な推論ステップが過剰な運用コストや遅延、ハルシネーションによる失敗を招くという課題があります。
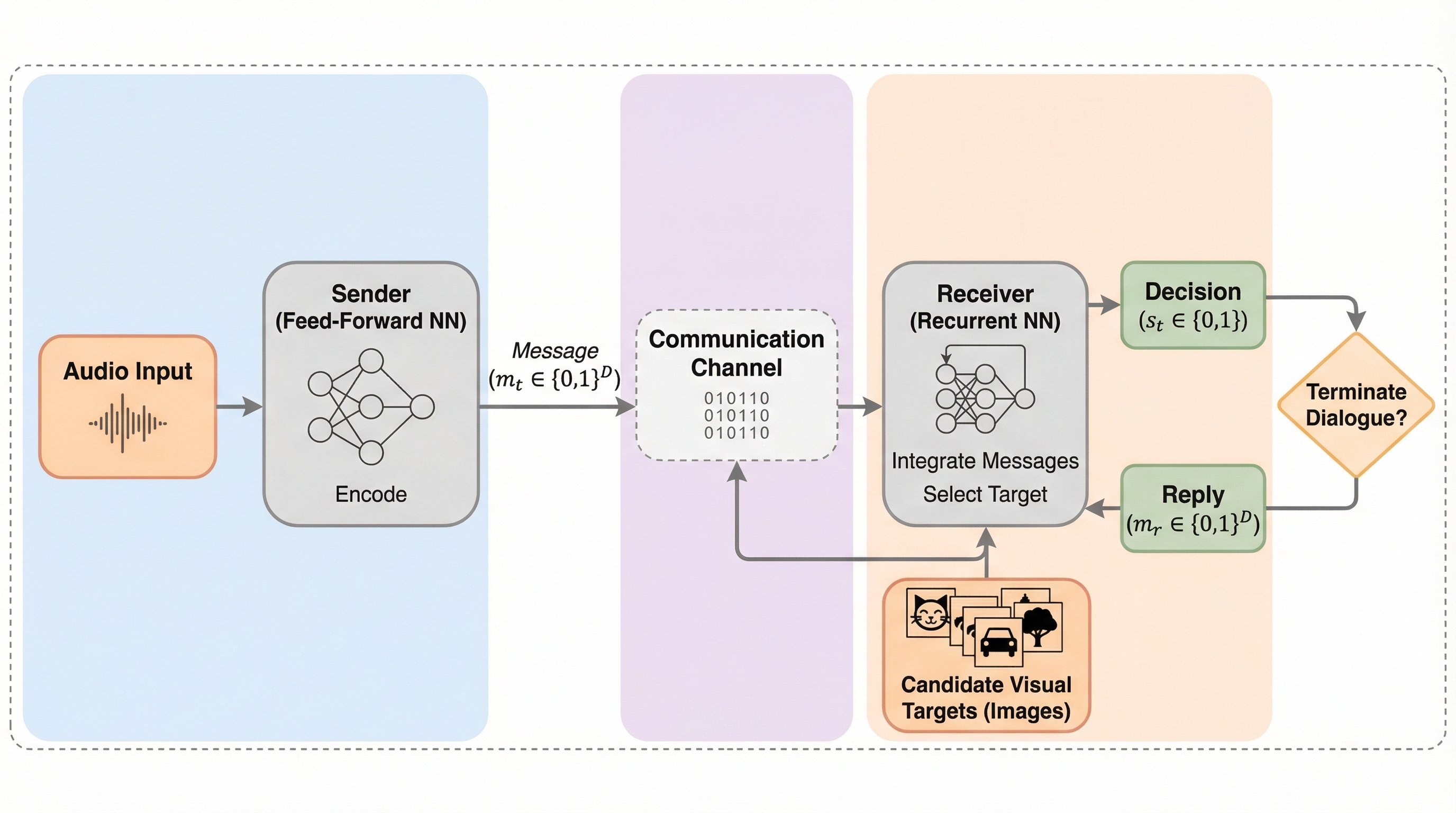
本研究は、送信者が「音声」を聞き、受信者が「画像」を見るという、互いに異なる知覚モダリティ(感覚器)を持つ異種マルチエージェント間において、共通の知覚基盤がない状態からどのようにコミュニケーションが創発するかを調査したものです。
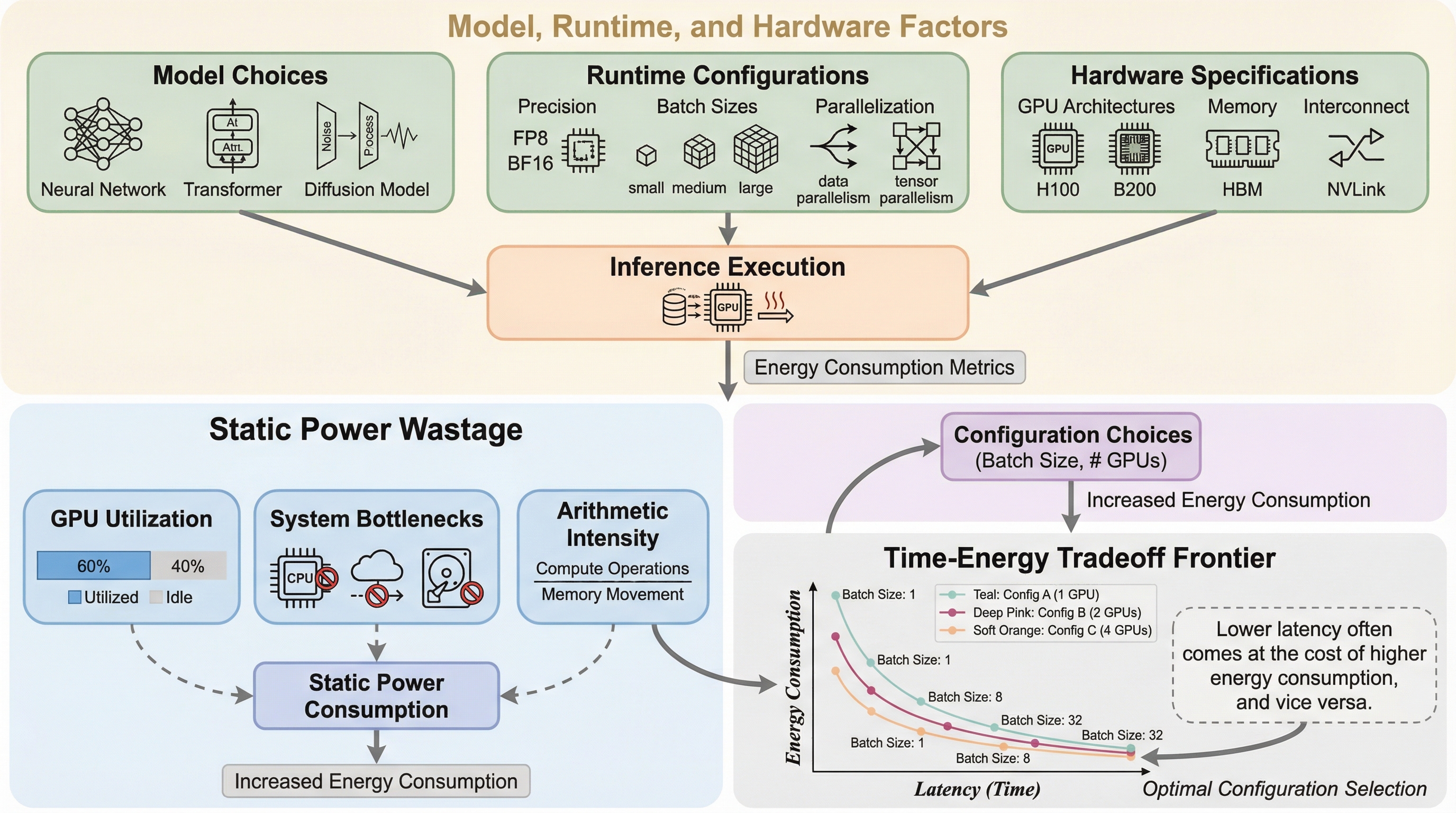
本研究は、46種類のモデルと7つのタスクにわたる1,858通りの構成を用い、NVIDIA H100およびB200 GPU上での生成AI推論におけるエネルギー消費を大規模に調査した。 LLMのタスク種別で25倍、動画生成は画像生成の100倍以上のエネルギー差が生じることや、GPU利用率の違いが3倍から5倍の消費電力差に直結することを明らかにした。 収集したデータに基づき、メモリ容量や利用率といった潜在的指標がエネルギー効率を決定づけるメカニズムを解明し、電力制約下でのデータセンター運用を最適化するための枠組みを提示している。
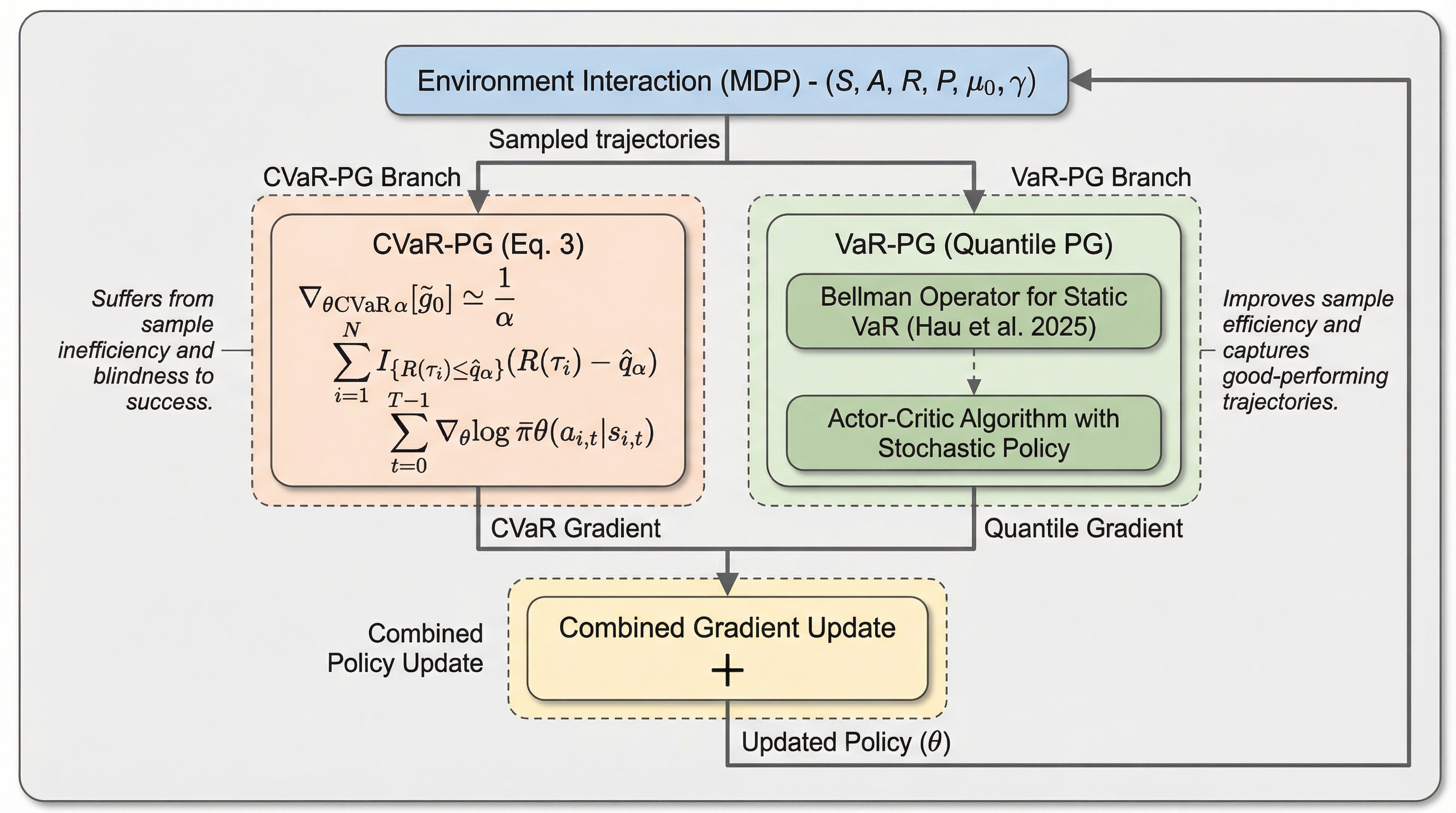
従来のリスク回避型強化学習で用いられるCVaR方策勾配法(CVaR-PG)は、報酬分布の最悪のケースであるテール部分のみに焦点を当てるため、収集したデータの大部分を破棄してしまい、学習のサンプル効率が著しく低いという致命的な課題を抱えていました。
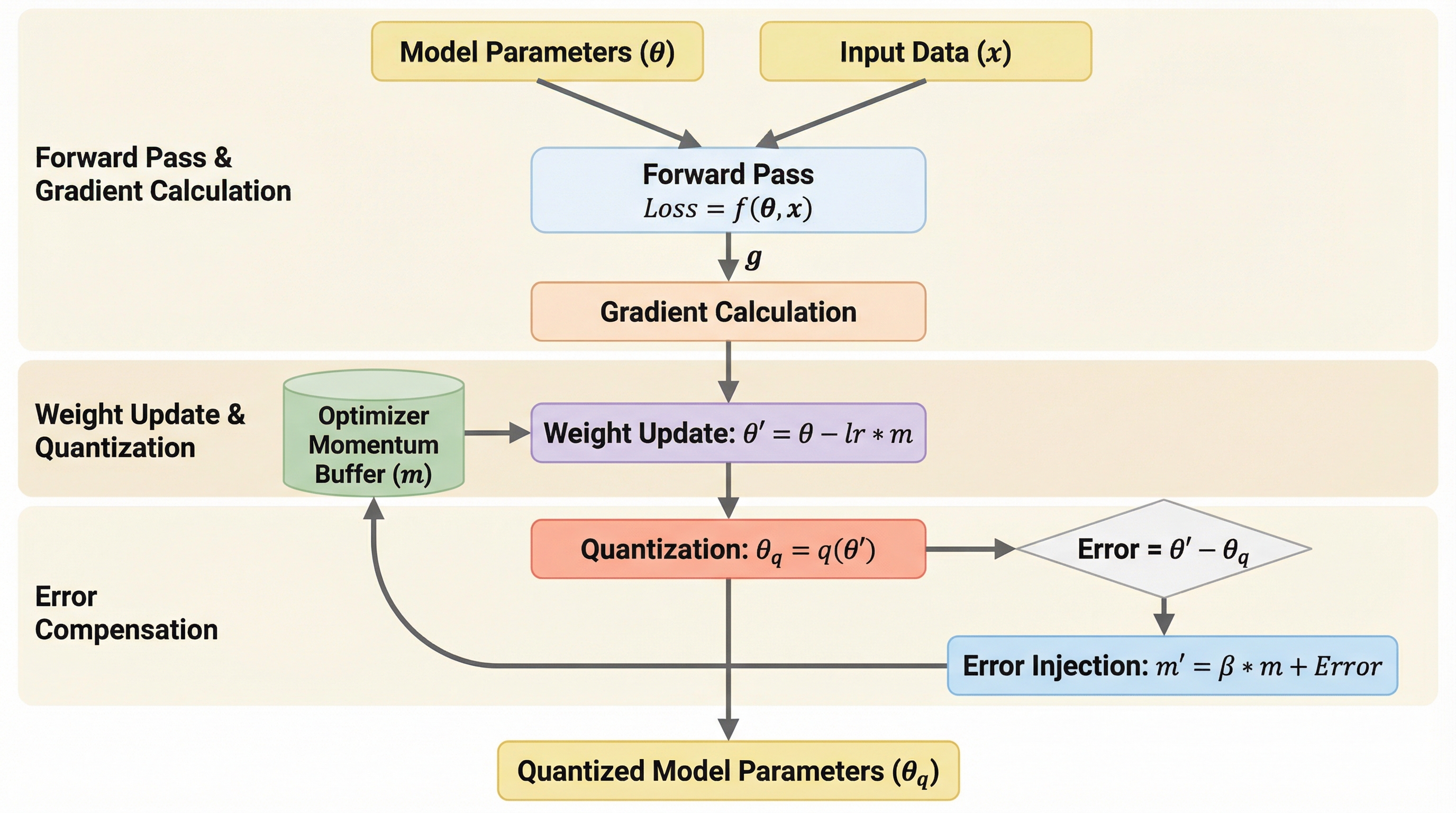
大規模言語モデル(LLM)の学習において、メモリ消費の大きな要因となっていた高精度なマスターウェイトを完全に排除し、量子化されたパラメータのみで学習を可能にする「Error-Compensating Optimizer(ECO)」が提案されました。
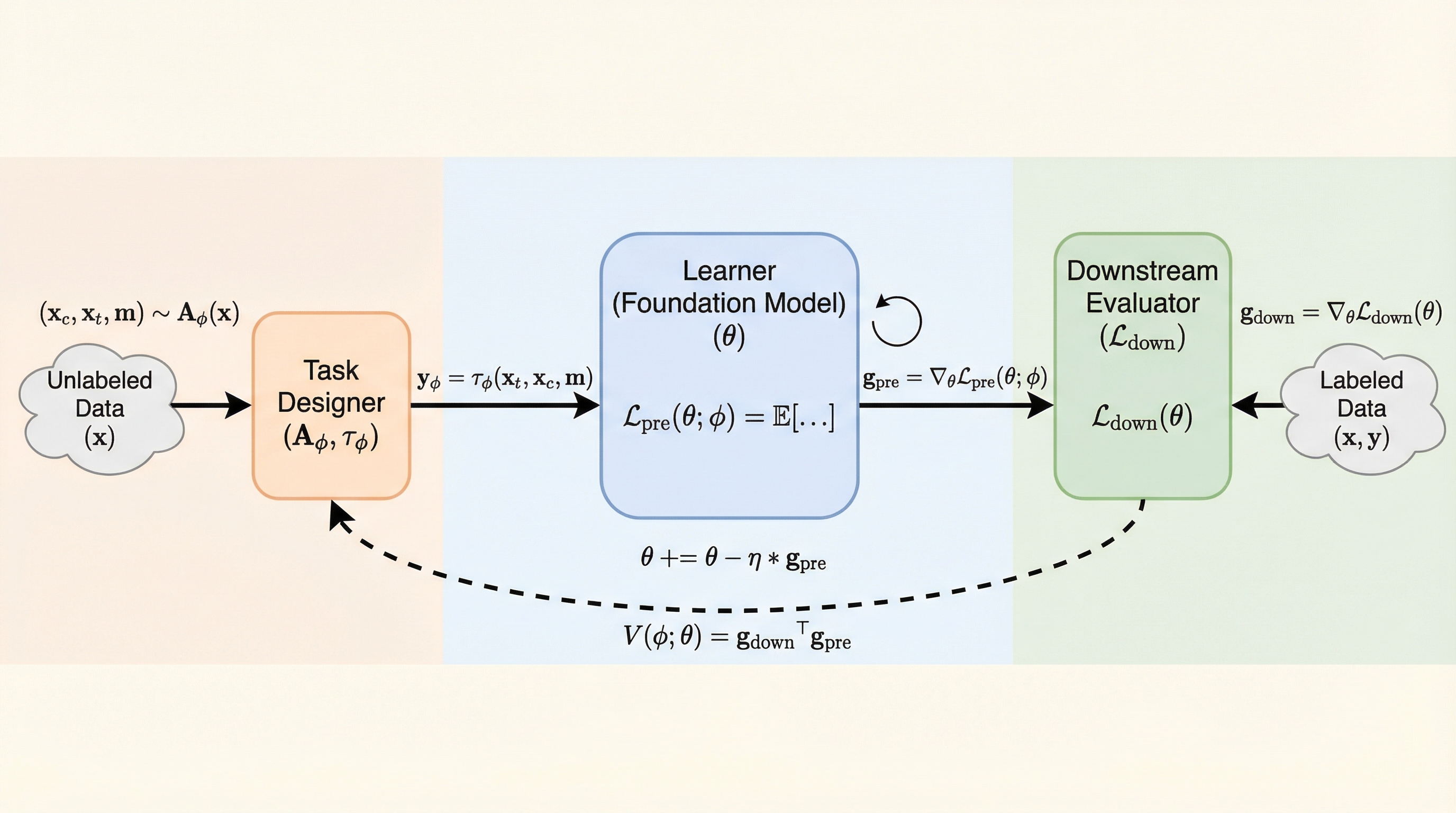
従来の自己教師あり学習は、次トークン予測などの固定された代理目的関数を最適化する「オープンループ」な仕組みであり、膨大な計算資源が必ずしも最終的に必要な下流タスクの能力向上に効率よく割り当てられないという課題を抱えていた。
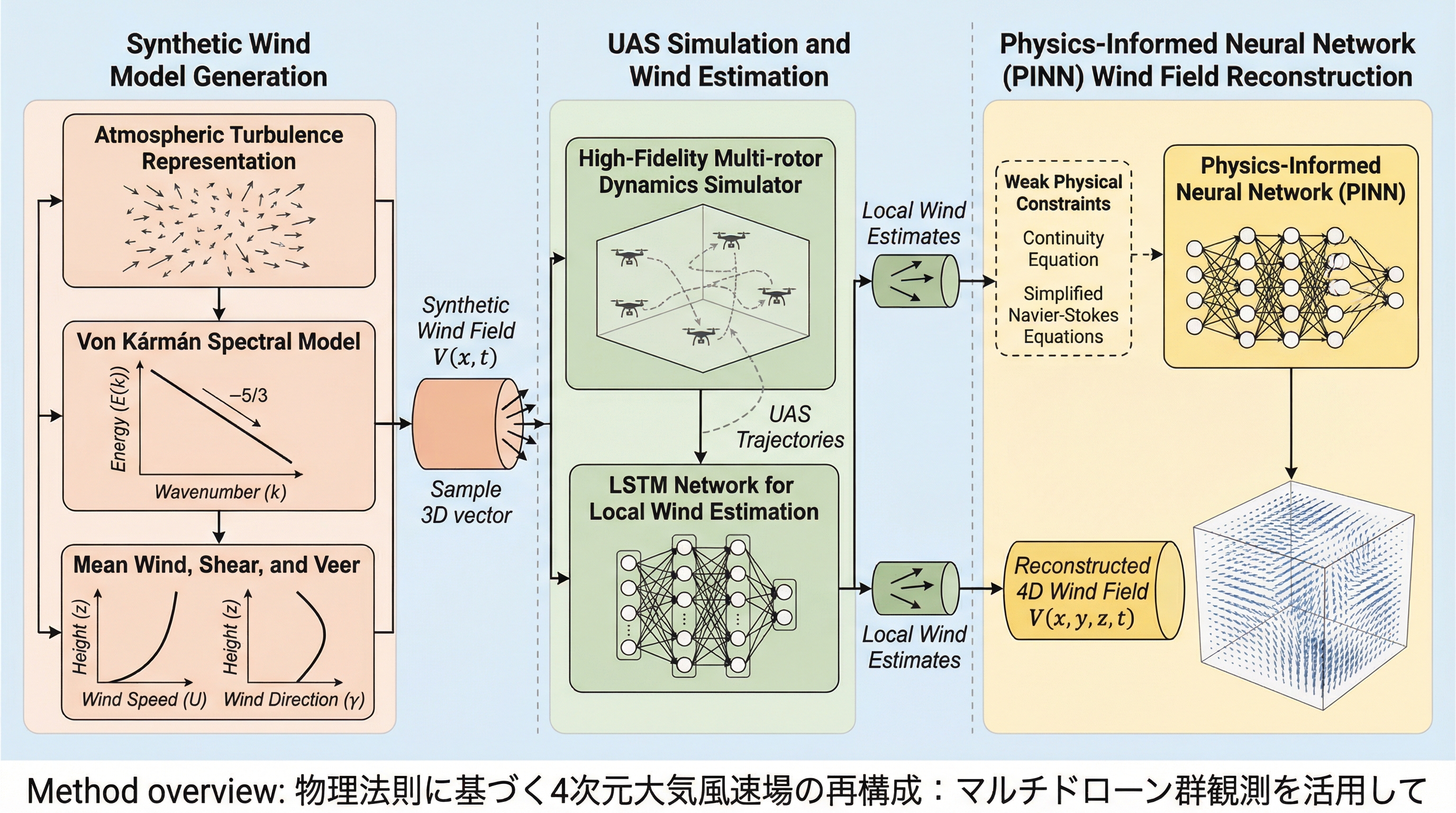
1. 複数の無人航空機システム(UAS)の群れを活用し、専用の風速センサーを搭載することなく機体の動的応答のみから局所的な風速を推定し、時間と空間の4次元で大気風速場を再構成する革新的なフレームワークを提案した。 2.
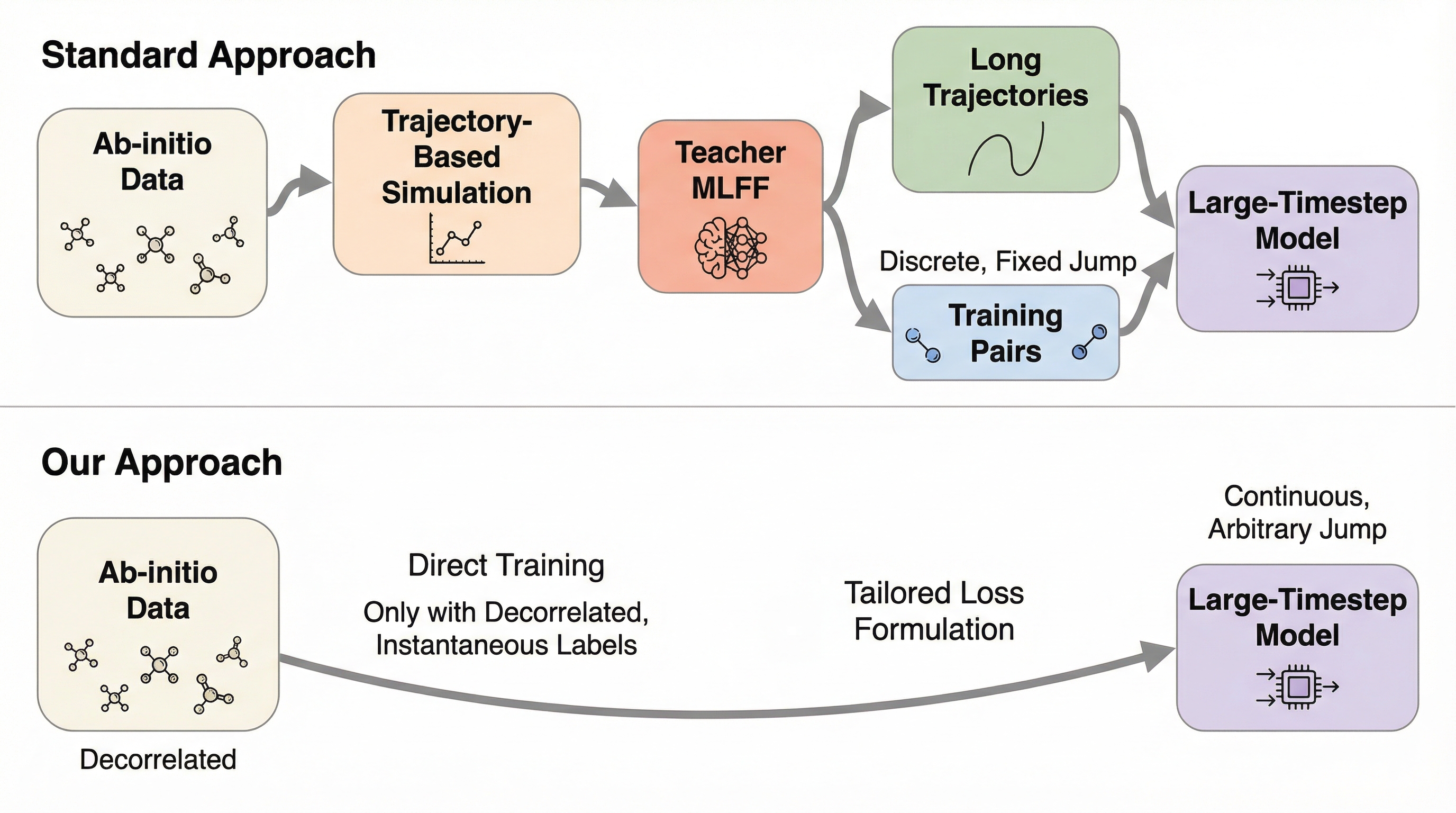
ハミルトニアン系の長時間シミュレーションにおいて、従来の数値積分手法が抱えていた「安定性のために極小のタイムステップを強いる」という計算上の制約を、指定した時間幅の相空間変化を直接予測する「ハミルトニアンフローマップ(HFM)」によって打破しました。
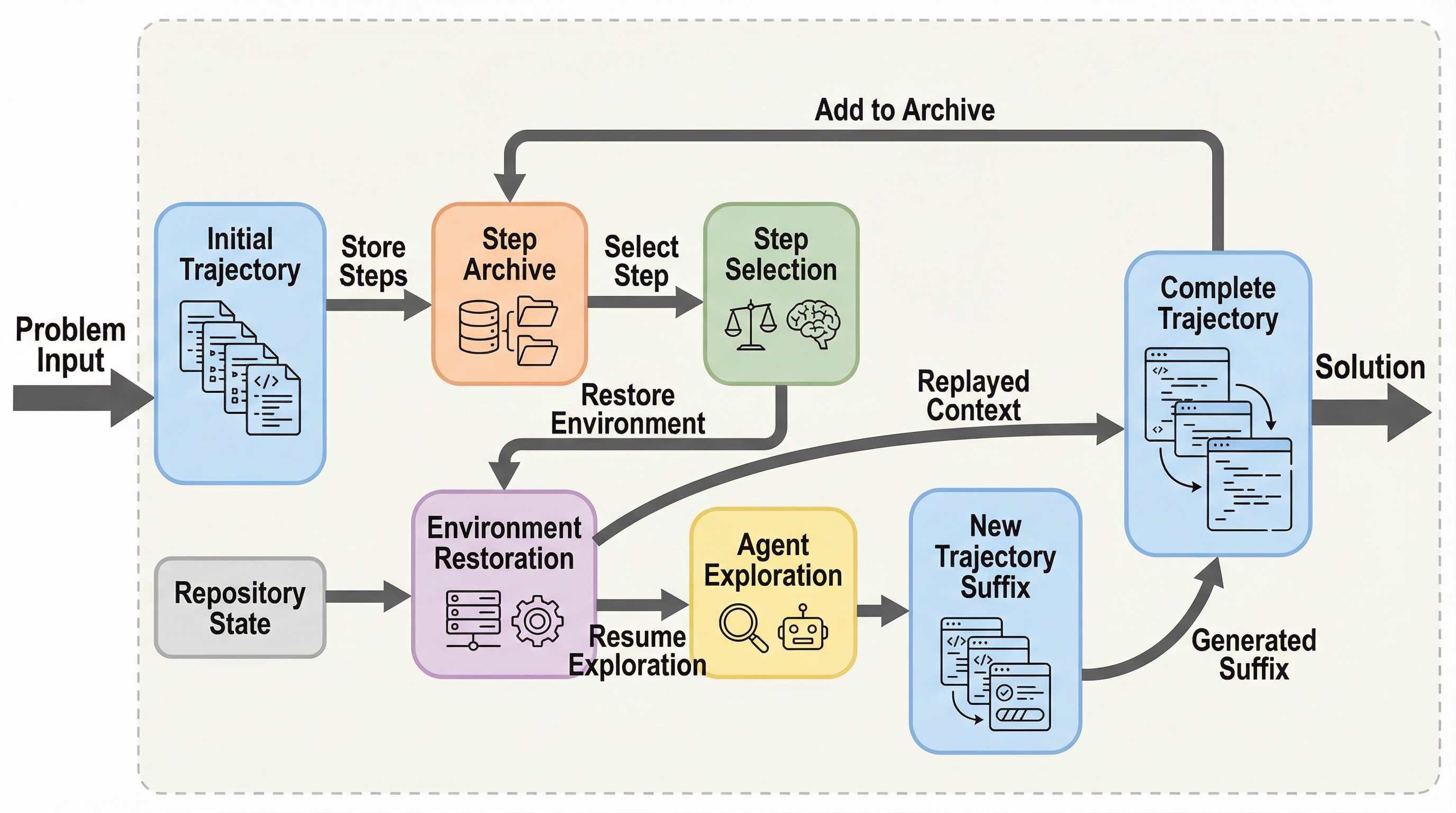
SWE-Replayは、ソフトウェアエンジニアリング(SWE)タスクにおいて、過去の試行(軌跡)から重要な中間ステップを再利用することで、計算コストを抑えつつ性能を向上させる新しいテスト時スケーリング手法である。