LogitsからLatentsへ:LLMアンラーニングのための対照的表現シェーピング
大規模言語モデル(LLM)のアンラーニングにおいて、従来の出力確率(Logits)を調整する手法は、忘却すべき概念を内部表現(Latents)に残存させ、保持すべき知識と絡み合わせる「抑制」に留まるという課題があった。
TL;DR(結論)
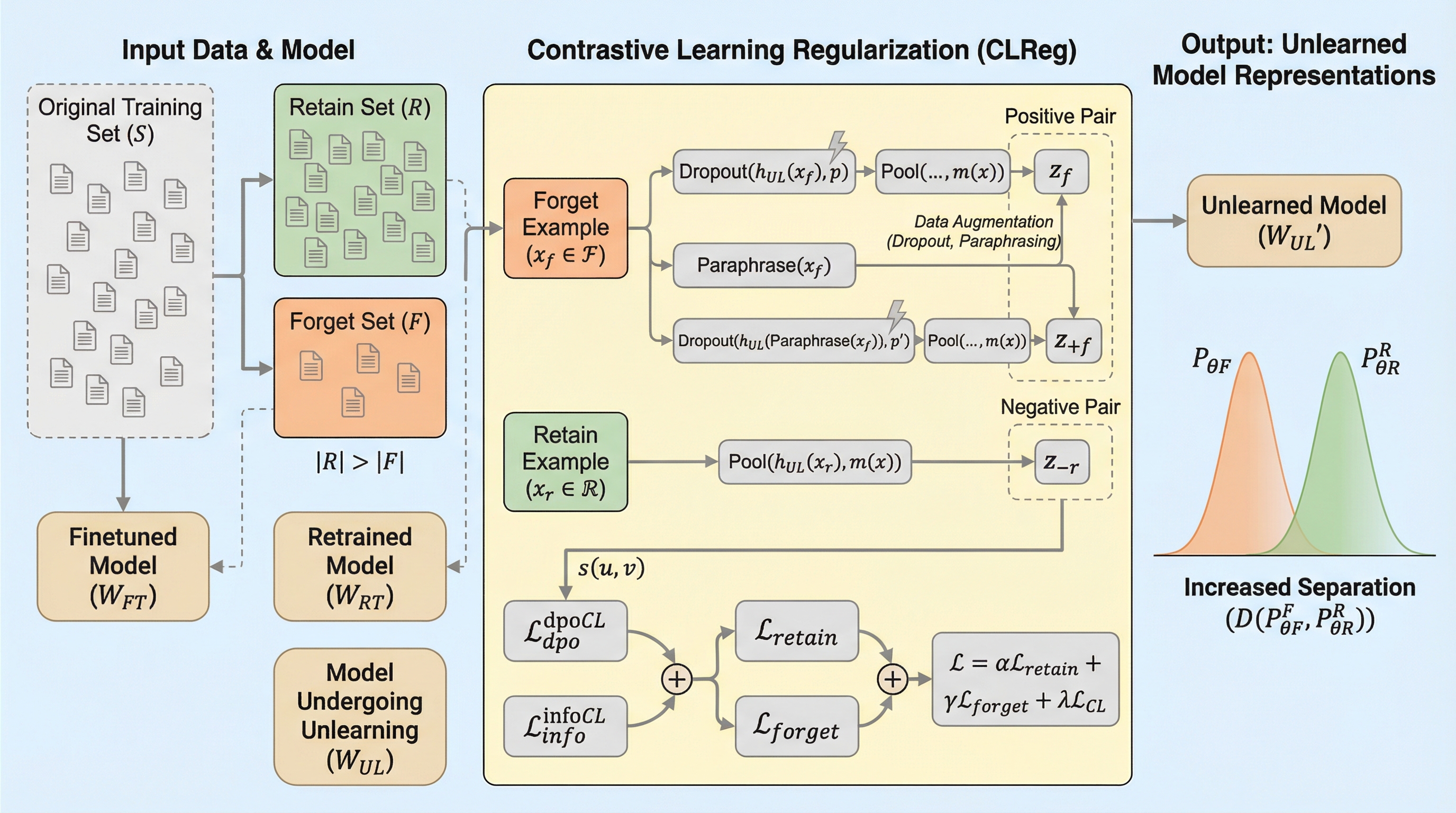
大規模言語モデル(LLM)のアンラーニングにおいて、従来の出力確率(Logits)を調整する手法は、忘却すべき概念を内部表現(Latents)に残存させ、保持すべき知識と絡み合わせる「抑制」に留まるという課題があった。本研究が提案するCLReg(対照的表現正則化)は、忘却対象の表現を特定して保持対象から遠ざける対照的学習を導入し、潜在空間における表現の絡み合いを明示的に解消することで、保持データへの副作用を抑えた外科的な忘却を実現する。理論的解析とTOFUやMUSE等のベンチマーク検証により、CLRegは既存手法の性能を底上げし、プライバシーリスクを伴わずに再学習モデルに近い挙動と表現空間の分離を達成することが確認された。
なぜこの問題か
大規模言語モデル(LLM)が社会の様々な基盤として普及する中で、モデルが学習した特定のデータの影響を事後的に削除する「マシンアンラーニング」の必要性が急速に高まっている。これは、欧州のGDPRに代表される「忘れられる権利」などのプライバシー法規制への準拠や、モデルのメンテナンスにおいて極めて重要な技術である。LLMは学習データに含まれる文章をそのまま記憶し、一言一句違わずに再現してしまう「逐次再現(verbatim sequence generation)」の性質を持っており、機密情報や著作権物、不適切なコンテンツをオンデマンドで削除する手段が求められている。理想的な解決策は、削除対象を除いたデータセットでモデルを一から再学習することだが、現代の巨大なLLMにおいてその計算コストは天文学的であり、現実的ではない。そのため、再学習後のモデルの挙動を効率的に近似する「近似アンラーニング手法」が数多く提案されてきた。 しかし、既存手法の多くは予測空間におけるアライメント、すなわち出力される単語の確率分布を調整することに主眼を置いている。…
核心:何を提案したのか
本論文では、LLMの潜在表現空間において忘却対象の概念を分離し、保持対象の表現から物理的に遠ざける「対照的表現正則化(CLReg: Contrastive Representation Regularizer)」を提案している。この手法の核心は、単に出力される単語の確率(Logits)を操作するのではなく、モデル内部の隠れ状態(Latents)そのものを整形(Shaping)することで、忘却と保持の間の干渉を根本から減少させる点にある。CLRegは、忘却対象の表現を特定のクラスターとしてまとめ上げつつ、それを保持対象の表現が位置する領域から反発させるように機能する。これにより、保持対象の表現に対する変化を最小限に抑えながら、忘却対象の概念だけを外科的に抽出して排除することが可能になる。 CLRegは、既存のあらゆるアンラーニングアルゴリズムに組み込んで使用できる汎用的な正則化項として設計されている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related