分位点勾配を用いたCVaR方策最適化の強化
従来のリスク回避型強化学習で用いられるCVaR方策勾配法(CVaR-PG)は、報酬分布の最悪のケースであるテール部分のみに焦点を当てるため、収集したデータの大部分を破棄してしまい、学習のサンプル効率が著しく低いという致命的な課題を抱えていました。
TL;DR(結論)
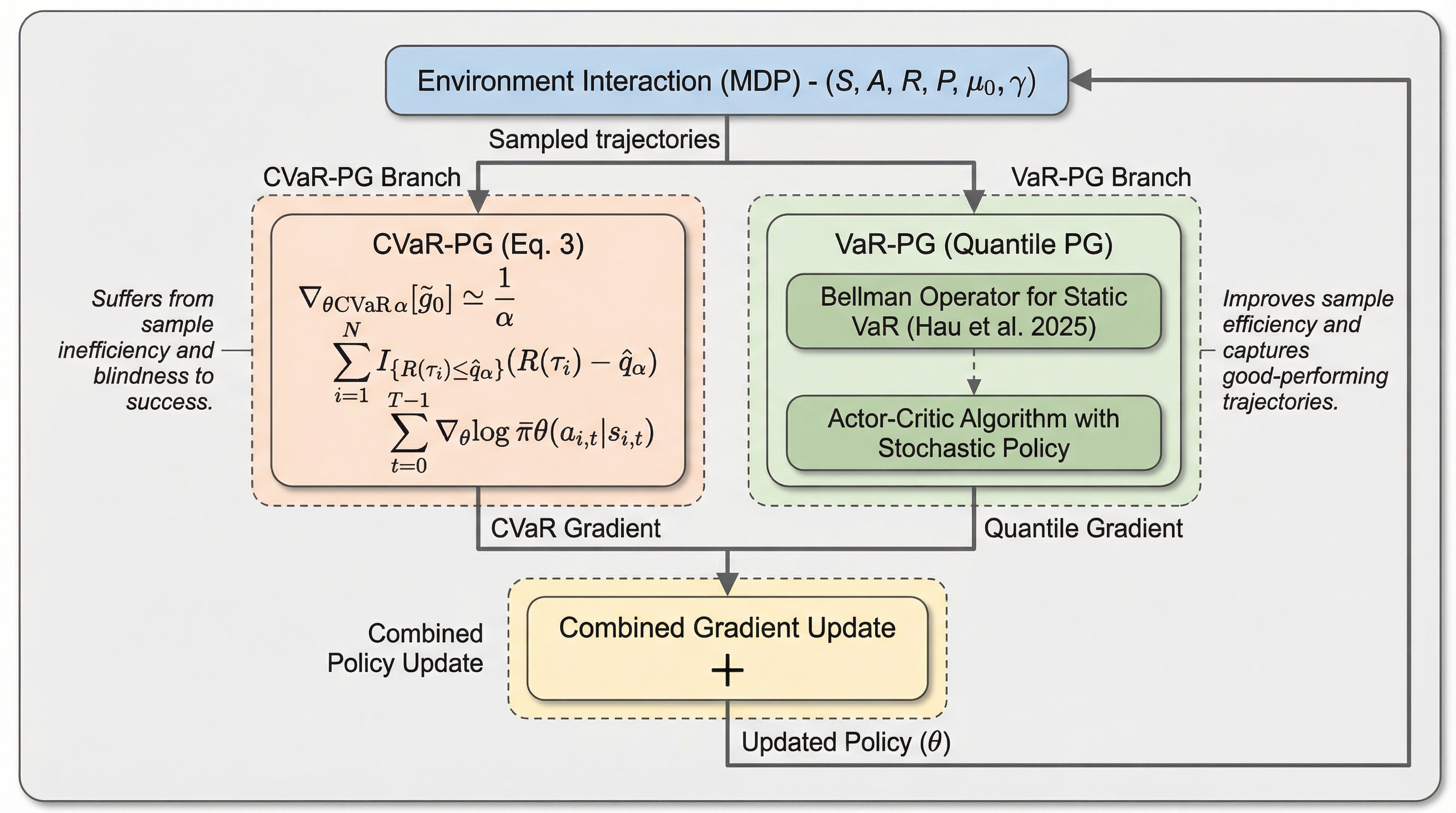
従来のリスク回避型強化学習で用いられるCVaR方策勾配法(CVaR-PG)は、報酬分布の最悪のケースであるテール部分のみに焦点を当てるため、収集したデータの大部分を破棄してしまい、学習のサンプル効率が著しく低いという致命的な課題を抱えていました。 本研究では、CVaRがテールのクォンタイル(分位点)の期待値であるという数学的性質に着目し、全データを用いた動的計画法が適用可能なクォンタイル最適化(VaR-PG)をCVaRの学習プロセスに組み込む新しいアルゴリズムを提案しました。 検証の結果、提案手法はマルコフ的な方策の範囲内でCVaR-PGを大幅に改善し、成功した軌跡も学習に活用することで、既存の他のリスク回避型強化学習手法を一貫して上回る性能と学習速度を達成し、リスクと報酬の高度な両立を実現しています。
なぜこの問題か
強化学習における意思決定において、リスク回避は極めて重要かつ実用的な考慮事項であり、これがリスク回避型強化学習(RARL)の研究を強く動機付けています。従来のリスク中立的な強化学習は、累積報酬の期待値を最大化することに焦点を当てていますが、自動運転や金融取引などの現実のシナリオでは、稀に発生する壊滅的な結果を防ぐことが最優先されます。そのため、分散やジニ偏差、バリュー・アット・リスク(VaR)、条件付きバリュー・アット・リスク(CVaR)など、様々なリスク指標を最適化する手法が提案されてきました。本研究では、特に静的なCVaRの最適化に焦点を当てています。CVaRは、指定されたリスクレベルにおける方策の戻り値の最悪のケースの期待値を強調する指標であり、これを最適化することで、方策が壊滅的な結果を招くことを統計的に防ぐことが可能になります。 しかし、強化学習において静的なCVaRを最適化することは容易ではありません。なぜなら、CVaRは各ステップのCVaR最適化に分解することができず、リスク中立的な強化学習で用いられる標準的な動的計画法を直接適用することができないからです。…
核心:何を提案したのか
本研究の核心的な提案は、CVaRの最適化をテールの戻り値に関するクォンタイル方策勾配(VaR-PG)で補強することです。このアプローチは、CVaRがテールのクォンタイルの期待値として解釈できるという直感的な理論に基づいています。CVaRを最適化する目的関数に、期待されるクォンタイル項を加えることで、学習の効率を劇的に向上させることが可能になります。この補強には、主に二つの利点があります。第一に、静的なCVaRとは異なり、静的なクォンタイル(VaR)の最適化は入れ子状の形式をとることができ、動的計画法による定式化が可能です。これにより、サンプリングされたすべてのデータを方策学習に活用できるようになり、CVaR-PGで問題となっていたデータの廃棄を避けることができます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related