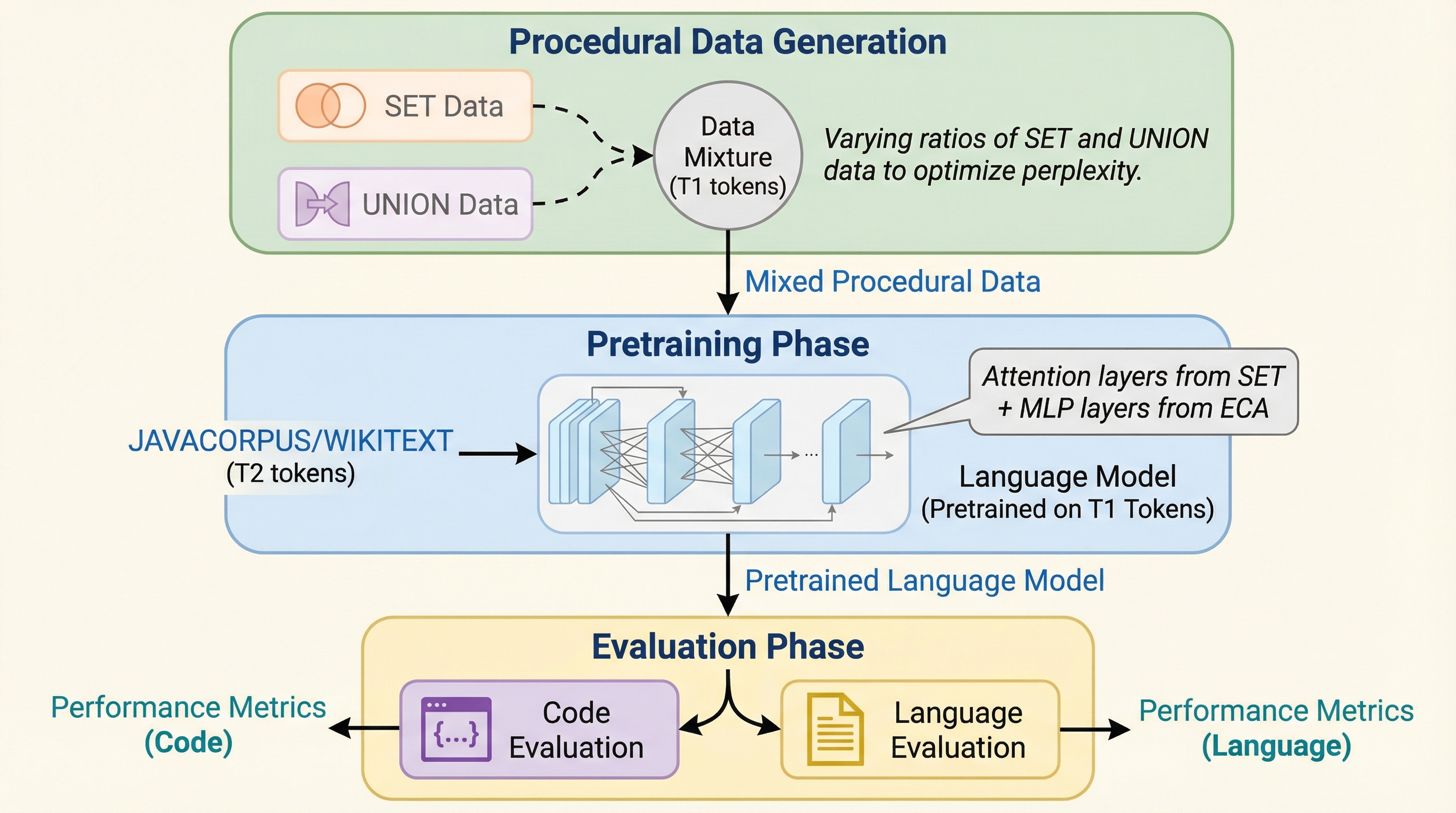
Procedural Pretraining: 抽象データによる言語モデルのウォーミングアップ
大規模言語モデルの事前学習において、自然言語やコードなどの意味を持つデータに触れる前に、アルゴリズムによって生成された抽象的な構造データ(手続き型データ)を学習させる「手続き型事前学習」という手法を提案した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルの事前学習において、自然言語やコードなどの意味を持つデータに触れる前に、アルゴリズムによって生成された抽象的な構造データ(手続き型データ)を学習させる「手続き型事前学習」という手法を提案した。
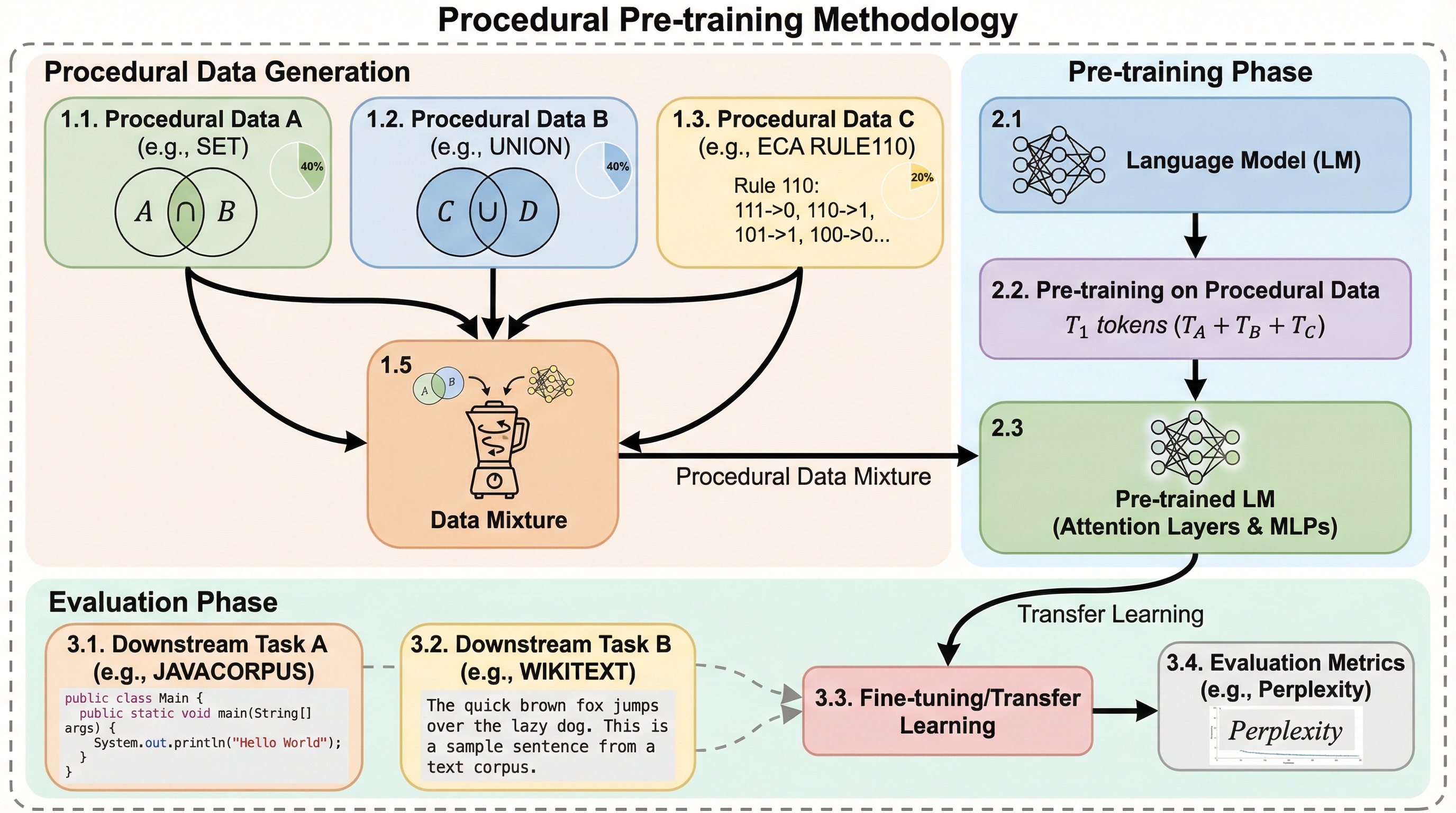
大規模言語モデルの学習において、自然言語の前に抽象的な構造を持つ「手続き型データ」を学習させる「手続き型事前学習」という手法が提案されました。この手法は、特定のアルゴリズムタスク(コンテキスト想起など)の精度を10%から98%へ劇的に向上させ、標準的な自然言語やコードの学習を大幅に加速させる効果があります。
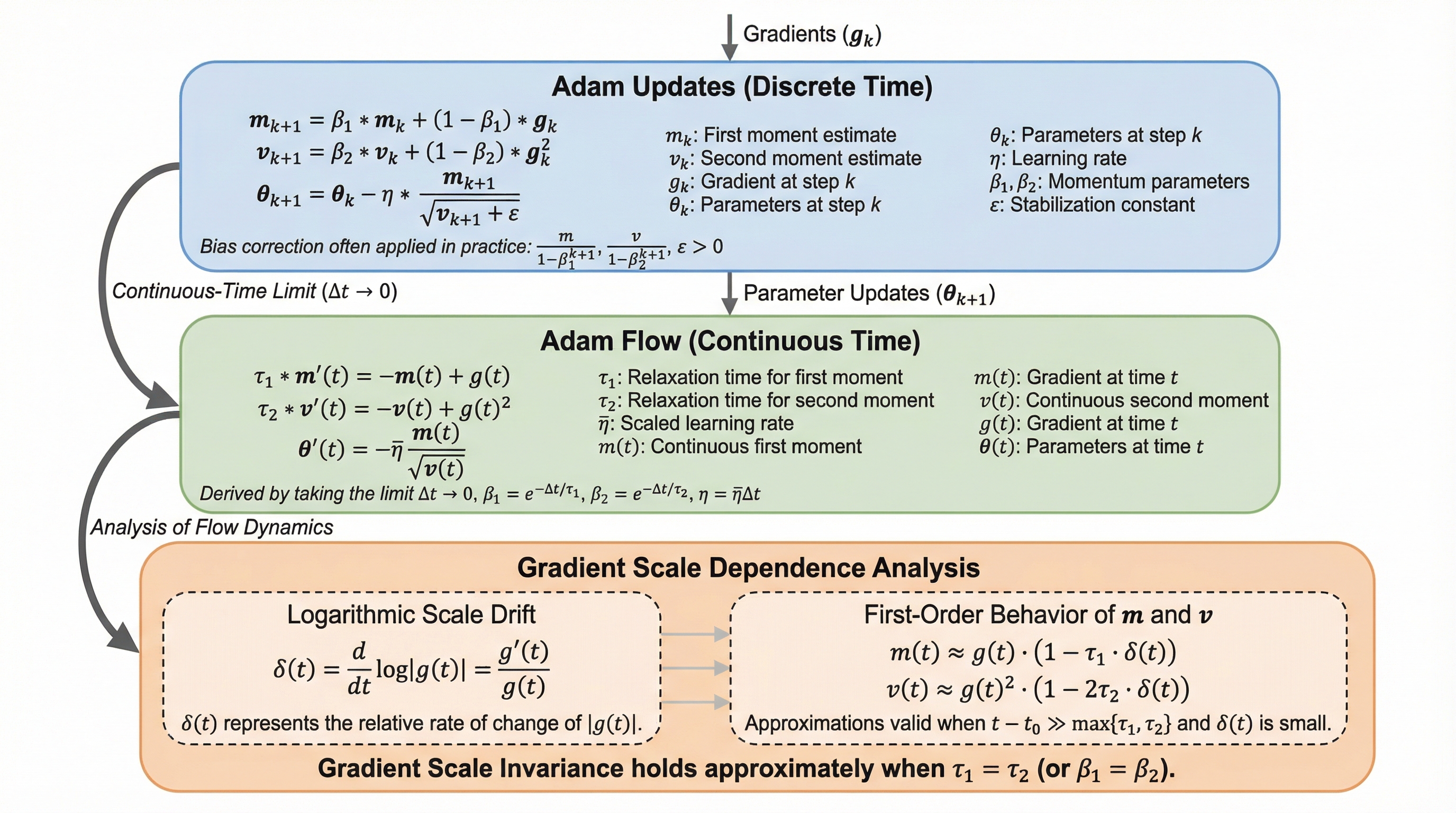
Adamのハイパーパラメータである$\beta1$と$\beta2$を等しく設定することで、訓練の安定性と精度が向上するという経験的事実に対し、「勾配スケール不変性」という新たな理論的枠組みを導入して数学的な解明を行った。
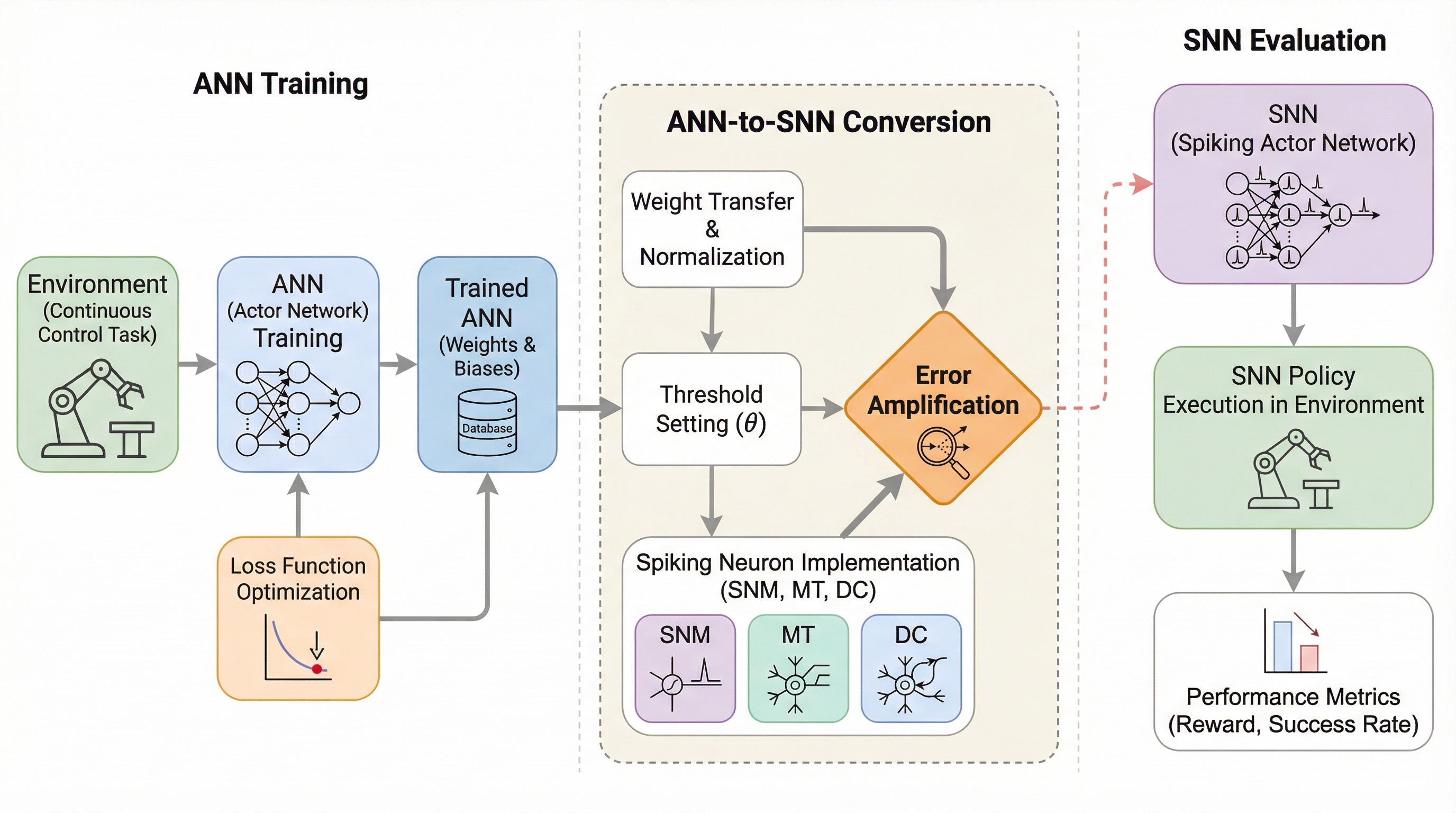
学習済みANNをSNNへ変換する手法は、連続制御タスクにおいて性能が著しく低下するが、その主因が微小な行動誤差の累積による「状態分布の乖離」と、誤差が時間的に正の相関を持つ「誤差増幅」にあることを突き止めた。
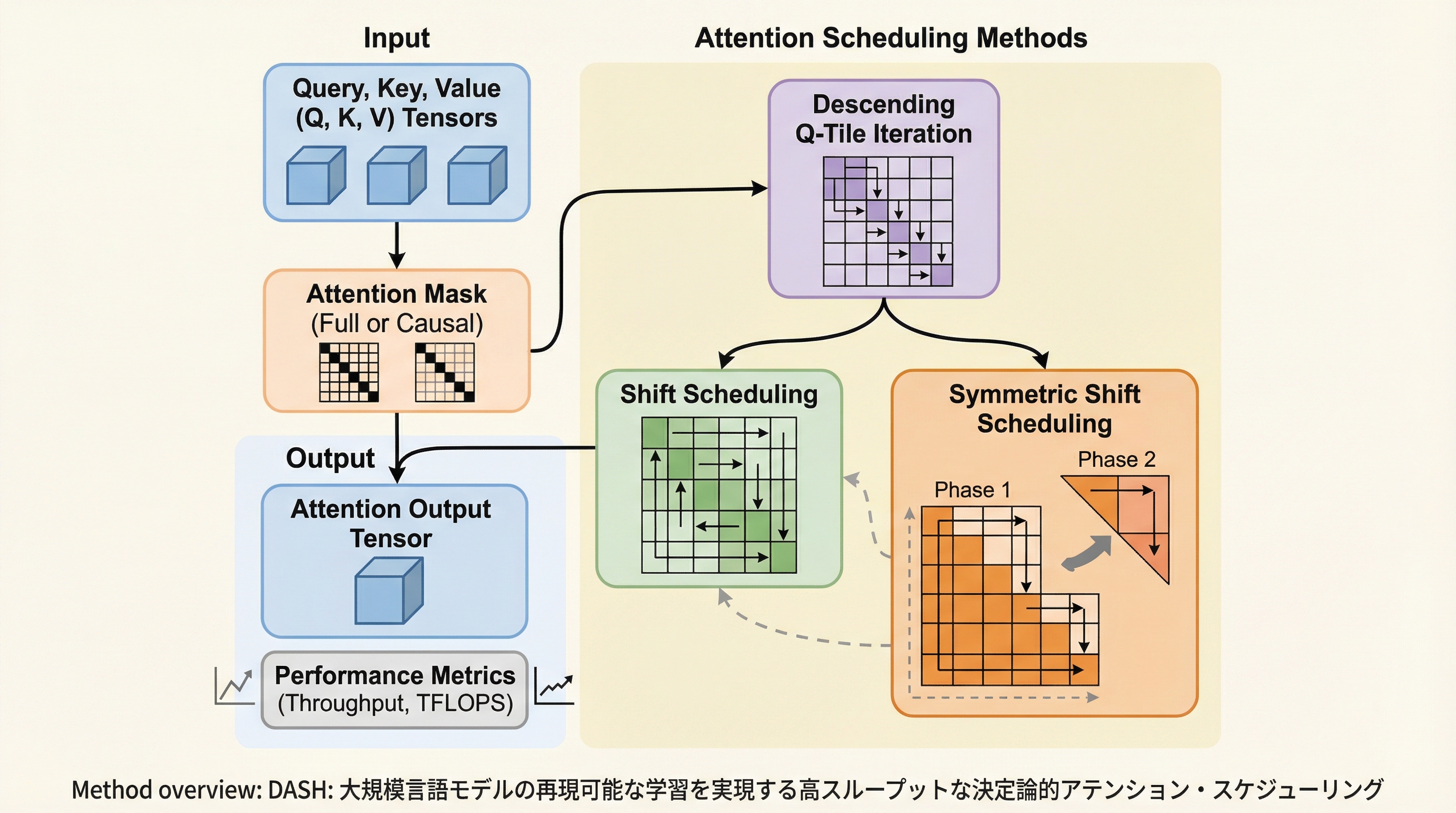
大規模言語モデル(LLM)の学習において、計算結果の再現性を保証する決定論的アテンションは不可欠だが、従来のFlashAttention-3等では勾配蓄積の直列化によりスループットが最大37.9%低下する課題があった。
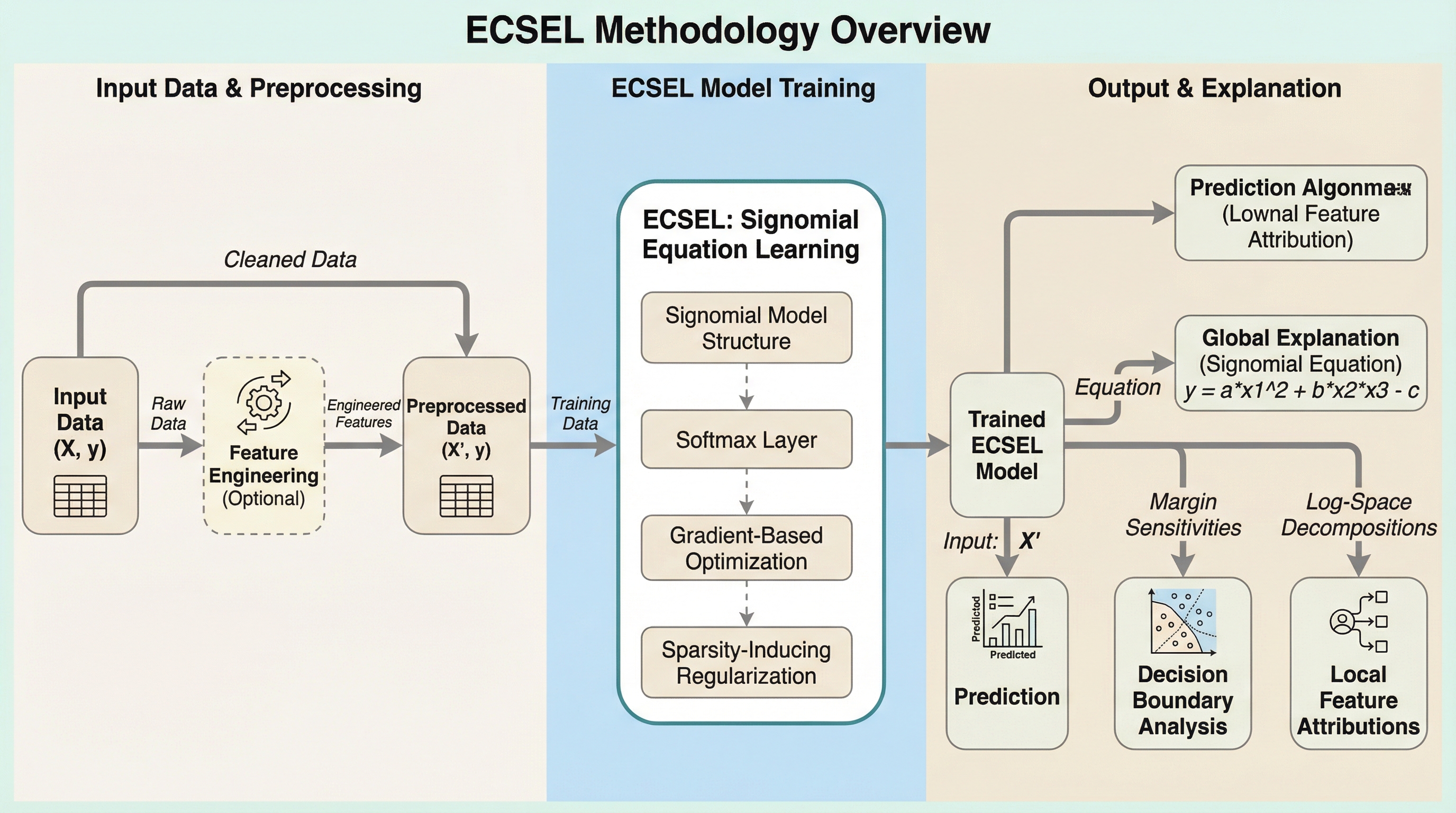
ECSELは、物理法則に多く見られる「シグノミアル方程式」という数式形式を学習モデルに採用することで、高い予測精度と人間が直接読み解ける透明性を両立した新しい分類手法である。 従来の記号回帰手法が抱えていた膨大な計算コストという課題を、勾配ベースの最適化とL1正則化を組み合わせることで解決し、既存の最先端手法を上回る数式復元率と劇的な計算時間の短縮を達成した。 学習された数式からは、特徴量の変化が予測に与える影響を弾力性や反実仮想推論といった数学的指標で直接算出でき、不正検知や電子商取引などの実務において根拠に基づいた意思決定を強力に支援する。
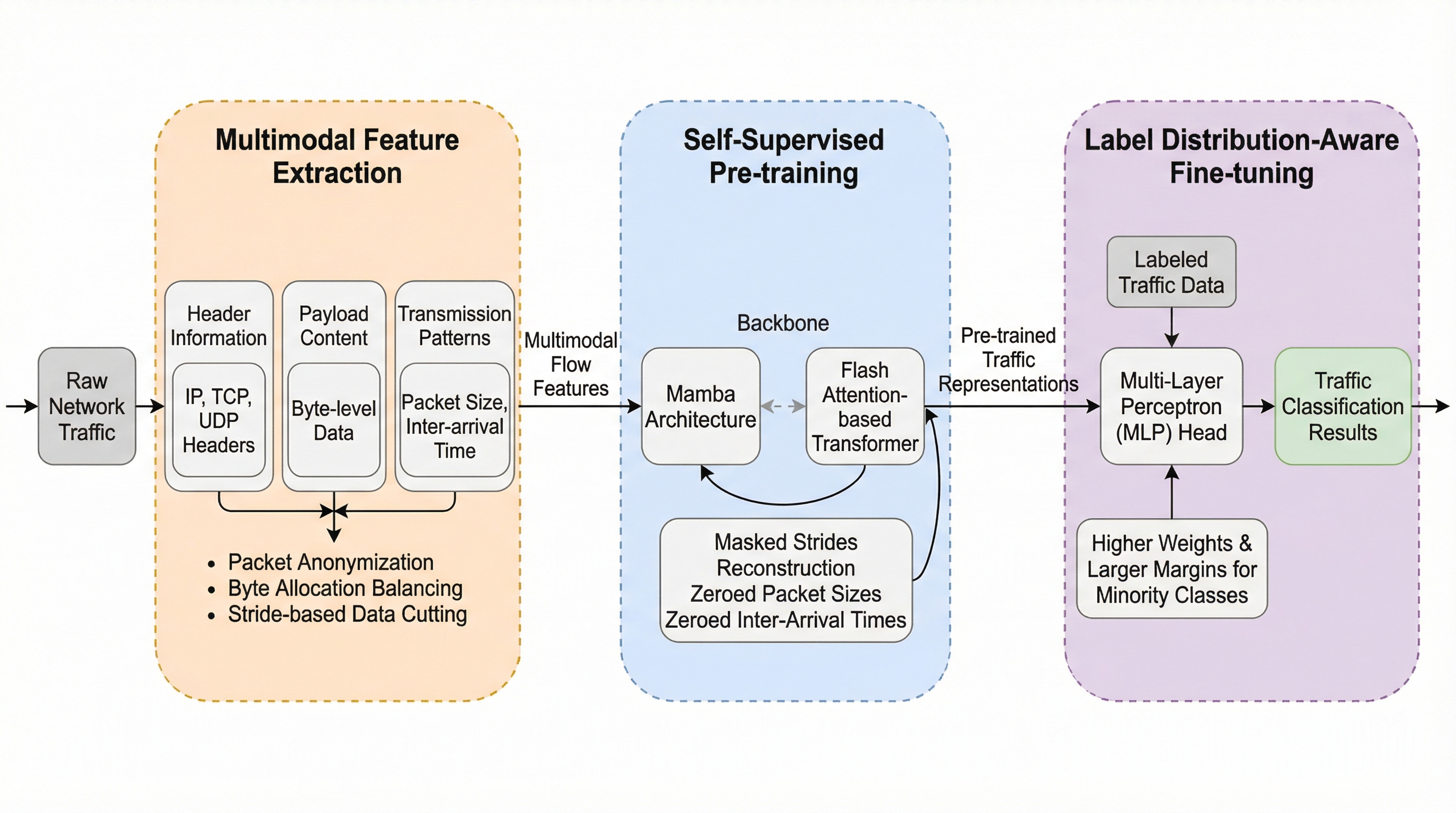
暗号化トラフィックの急増に伴い、従来のTransformerモデルでは計算コストの増大やデータの不均衡、表現力の不足が課題となっていたが、本研究では線形時間計算量を持つMambaアーキテクチャとFlash Attentionを統合した「NetMamba+」を提案し、効率性と精度の両立を実現した。
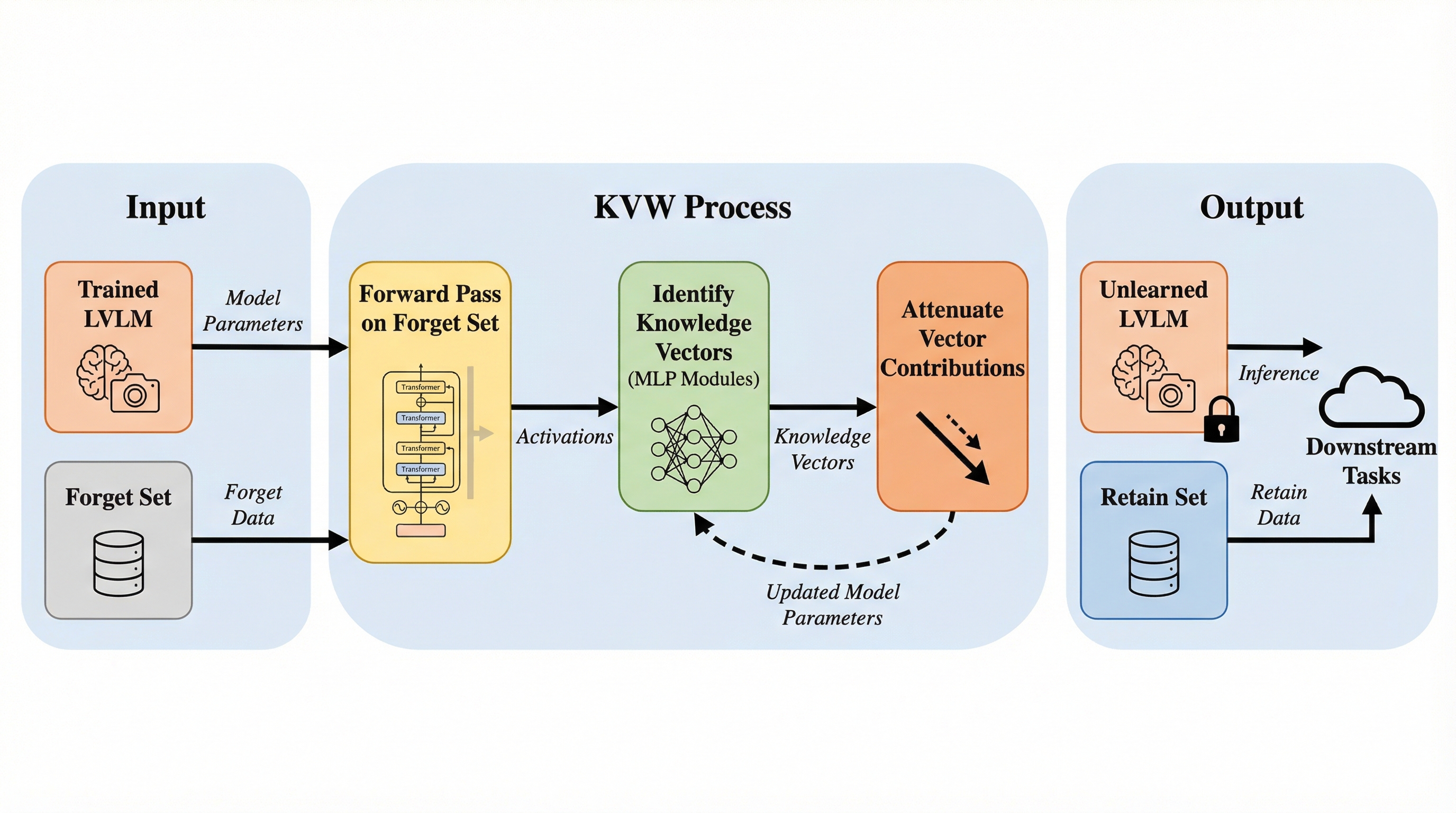
大規模視覚言語モデル(LVLM)において、プライバシー侵害や有害情報の生成を防ぐために特定の学習データの影響を取り除く「アンラーニング」を、勾配計算や再学習を一切行わず、推論時の順伝播のみで実現する新手法「Knowledge Vector Weakening(KVW)」が提案されました。
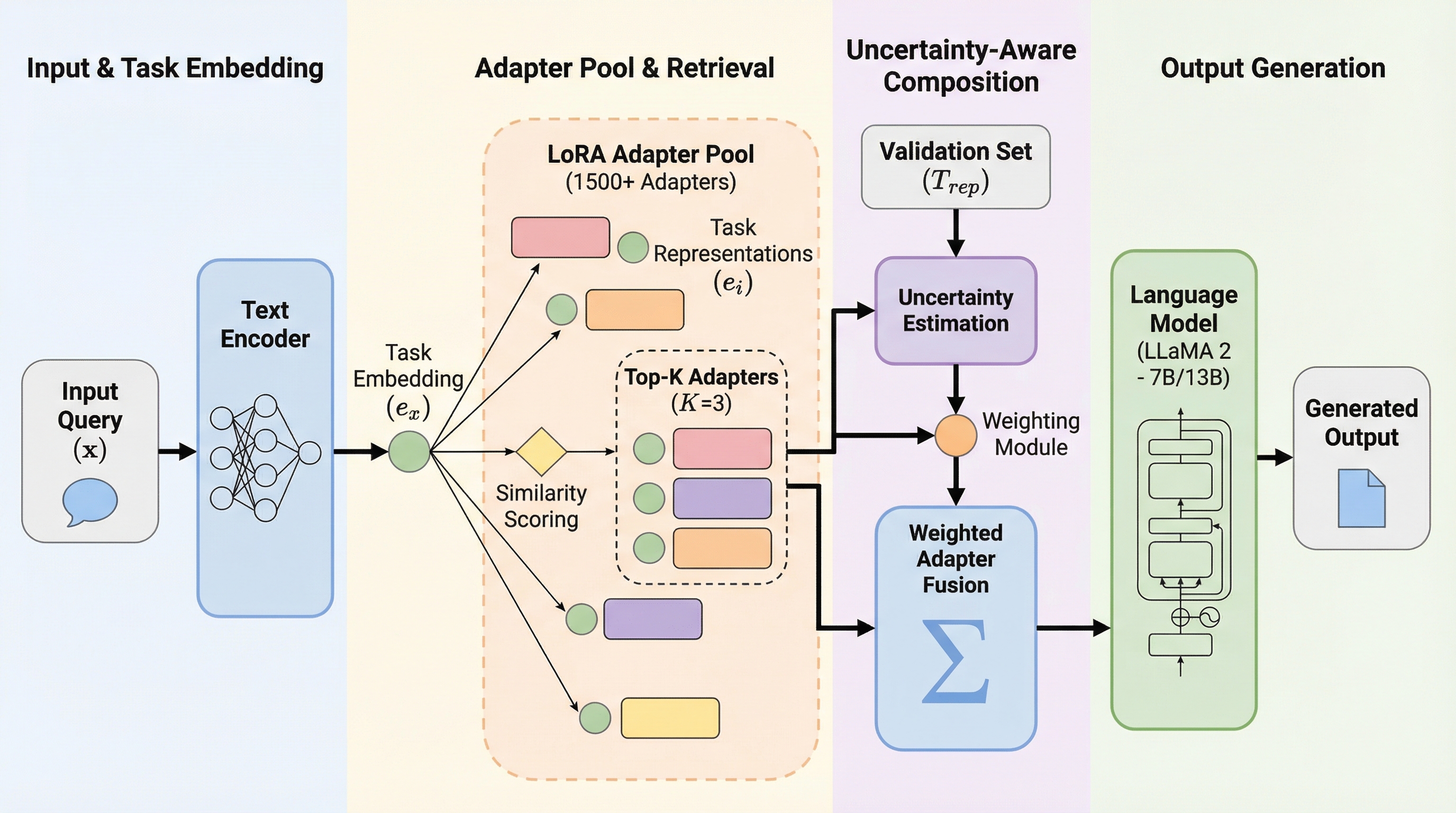
大規模言語モデルの効率的な専門化を実現するLoRAアダプターの膨大なプールから、入力クエリに最適なものを選択・統合する新しいルーティング枠組み「LORAUTER」が提案されました。 従来手法とは異なり、アダプターそのものの特性ではなく「タスク表現」を介してルーティングを行うことで、アダプターの学習データにアクセスできないブラックボックス設定でも動作し、タスク数に応じた高い拡張性を実現しています。 検証では、既存のタスクに最適化されたアダプターと同等以上の性能(101.2%)を達成したほか、未知のタスクに対しても従来手法を5.2ポイント上回る精度を示し、1500個以上のアダプターを含む大規模でノイズの多い環境でも堅牢に機能することが確認されました。
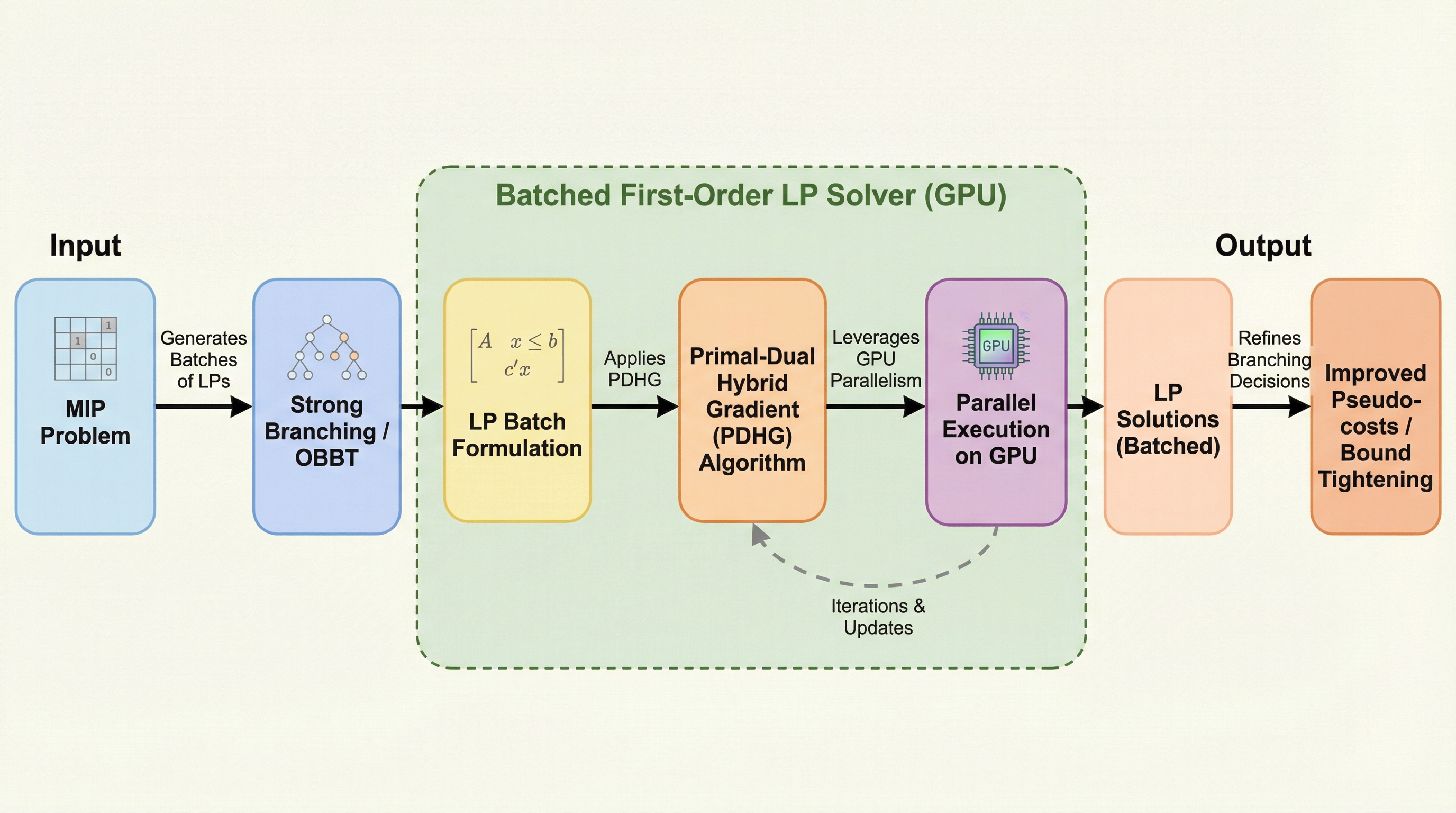
混合整数計画法(MIP)の計算効率を劇的に向上させるため、GPUの並列演算能力を最大限に活用して複数の線形計画問題(LP)を一括で解く「バッチ処理型一次形式解法(BatchLP)」が開発されました。