MIPにおける並列LP求解のためのバッチ化された一次手法
混合整数計画法(MIP)の計算効率を劇的に向上させるため、GPUの並列演算能力を最大限に活用して複数の線形計画問題(LP)を一括で解く「バッチ処理型一次形式解法(BatchLP)」が開発されました。
TL;DR(結論)
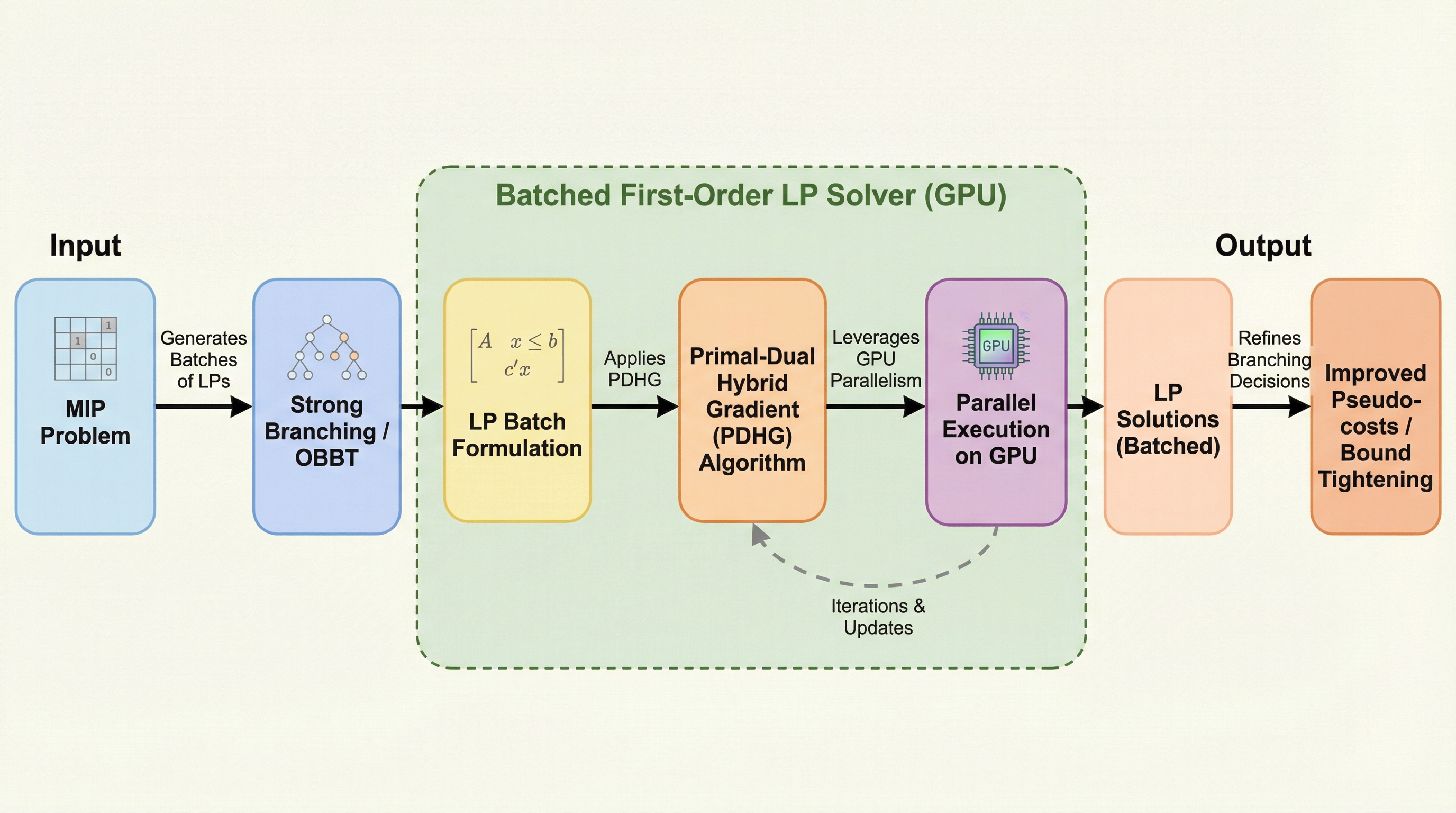
混合整数計画法(MIP)の計算効率を劇的に向上させるため、GPUの並列演算能力を最大限に活用して複数の線形計画問題(LP)を一括で解く「バッチ処理型一次形式解法(BatchLP)」が開発されました。この手法は、従来のシンプレックス法が抱えていた並列化の困難さとCPU・GPU間のデータ転送ボトルネックを解消し、行列対ベクトル演算を効率的な行列対行列演算へと転換することで、計算リソースの飽和を実現しています。 具体的には、主双対ハイブリッド勾配法(PDHG)に反射型ハルパーン反復や適応的なリスタート戦略を組み合わせることで、収束性能と安定性を高め、強力な分枝(Strong Branching)や最適化ベースの境界引き締め(OBBT)といった高負荷なタスクを高速化します。 実験では、従来のCPUベースのソルバーと比較して12倍から最大489倍という圧倒的な速度向上を記録しており、これまで計算コストの制約から近似的なヒューリスティックに頼らざるを得なかったMIPの主要な処理を、GPU上で厳密かつフルに実行することを可能にする画期的な成果を収めています。
なぜこの問題か
混合整数計画法(MIP)の解法において、線形計画(LP)リラクゼーションを解くプロセスは計算の根幹を成すものですが、長年にわたりCPU上でのシンプレックス法に依存してきました。シンプレックス法は、変数の境界変更や制約の追加といった微小な修正に対してウォームスタートが容易であるという優れた特性を持つ一方で、アルゴリズムの性質上、並列化が極めて困難であるという致命的な欠点を抱えています。現代の計算環境においてGPUの演算能力が飛躍的に向上しているにもかかわらず、MIPソルバーがその恩恵を十分に享受できていないのは、このシンプレックス法への依存が大きな要因となっています。また、CPUとGPUの間で大量のデータを頻繁に往復させることは、通信遅延や帯域幅の制限により、システム全体のパフォーマンスを著しく低下させるボトルネックとなります。 特に、分枝限定法における「強力な分枝(Strong Branching)」や、前処理段階での「最適化ベースの境界引き締め(OBBT)」は、非常に優れた収束性能や境界の強化をもたらすことが知られていますが、これらは膨大な数のLPを解く必要があるため、計算コストが膨大になります。…
核心:何を提案したのか
本論文では、GPU上で複数の関連するLPを同時に、かつ完全に並列で解くための「バッチ処理型一次形式解法(BatchLP)」を提案しています。この手法の核心は、主双対ハイブリッド勾配(PDHG)アルゴリズムを拡張し、複数の問題を一つの巨大な行列演算として一括処理できるようにした点にあります。具体的には、制約行列が共通で、目的関数の係数や変数の境界条件のみが異なる多数のLPを、行列対行列演算として定式化し直しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related