Knowledge Vector Weakening: 大規模視覚言語モデルのための効率的な訓練不要のアンラーニング手法
大規模視覚言語モデル(LVLM)において、プライバシー侵害や有害情報の生成を防ぐために特定の学習データの影響を取り除く「アンラーニング」を、勾配計算や再学習を一切行わず、推論時の順伝播のみで実現する新手法「Knowledge Vector Weakening(KVW)」が提案されました。
TL;DR(結論)
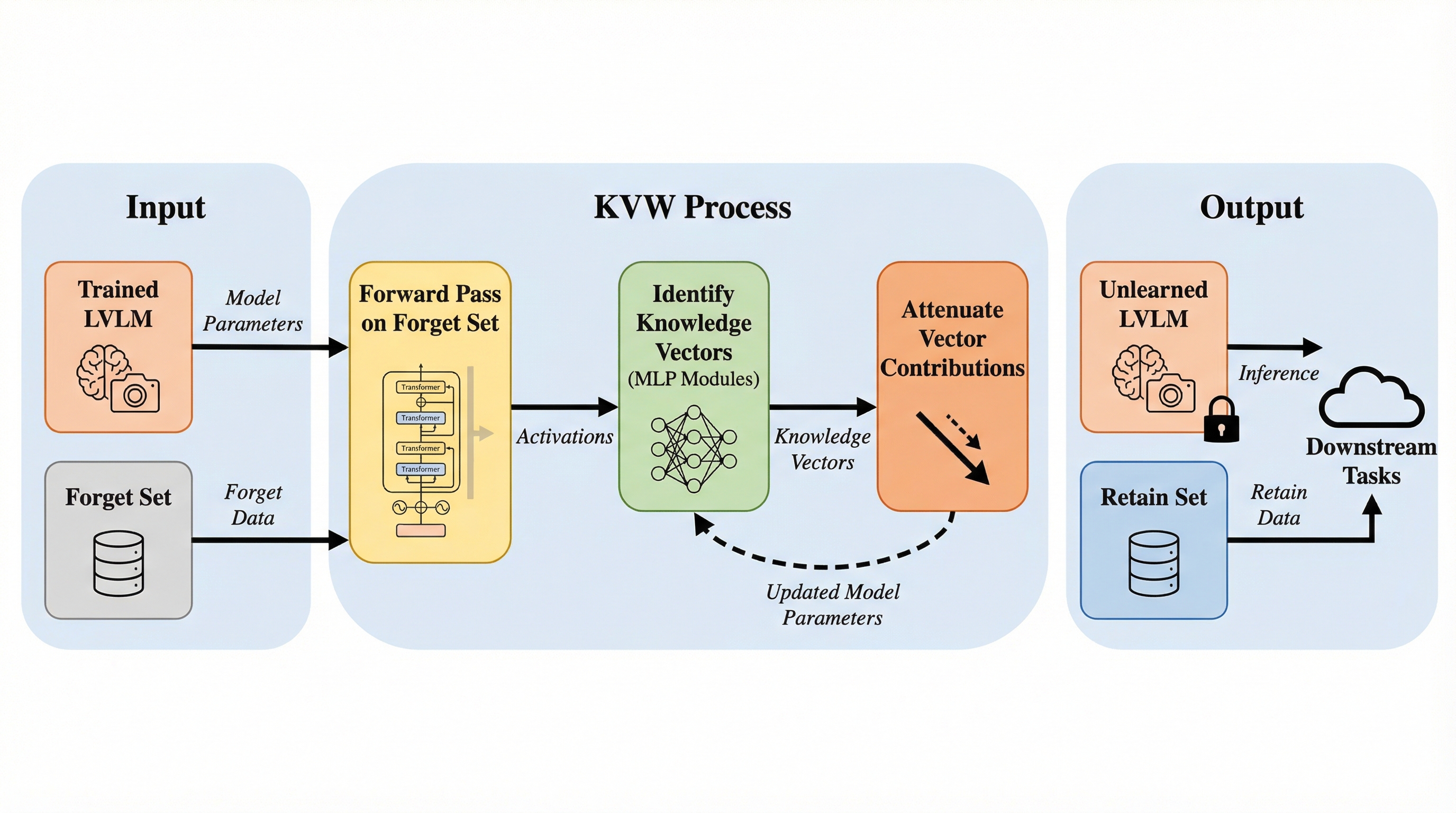
大規模視覚言語モデル(LVLM)において、プライバシー侵害や有害情報の生成を防ぐために特定の学習データの影響を取り除く「アンラーニング」を、勾配計算や再学習を一切行わず、推論時の順伝播のみで実現する新手法「Knowledge Vector Weakening(KVW)」が提案されました。 この手法は、モデル内部のフィードフォワードネットワーク(FFN)を知識を蓄積するメモリと見なし、消去対象のデータに関連する特定の知識ベクトルを特定してその寄与度を段階的に弱めることで、保持すべき一般的な知識の性能を維持しながら、対象の知識のみを効率的かつピンポイントで消去します。 既存の勾配ベースやLoRAベースの手法と比較して、計算時間とメモリ消費を劇的に削減しつつ、ハイパーパラメータへの感度が低い安定したアンラーニング性能を達成しており、大規模なマルチモーダルモデルにおける実用的かつ安全なデータ削除手段としての有効性が示されました。
なぜこの問題か
大規模視覚言語モデル(LVLM)は、画像とテキストを組み合わせた高度な理解能力を持ち、視覚的な質問応答や画像キャプションの生成、ドキュメントの理解など、幅広いタスクで優れた性能を発揮しています。しかし、その強力な能力の裏側で、学習データに含まれる個人のプライバシー情報の漏洩や、著作権で保護されたコンテンツの無断生成、さらには不適切あるいは有害な情報の出力といった深刻なリスクが懸念されています。これらの問題を解決するために、モデルから特定のデータの影響を選択的に排除する「マシンアンラーニング」が重要な技術として注目されています。 最も単純な解決策は、削除したいデータを除いた新しいデータセットでモデルを一から再学習させることですが、大規模なLVLMにおいては計算コストが天文学的になり、現実的ではありません。そのため、すでに学習済みのモデルから特定の知識を近似的に取り除く手法が研究されてきましたが、その多くは誤差逆伝播法を用いた勾配ベースの最適化に依存しています。これらの手法は、モデルのパラメータを更新するために多大な時間とメモリを必要とし、特にモデルが巨大化するほど計算負荷が指数関数的に増大するという課題があります。…
核心:何を提案したのか
本研究では、従来の勾配ベースの手法が抱える膨大な計算コストと、LoRAベースの手法が抱えるハイパーパラメータへの高い依存性という二つの大きな課題を同時に解決するために、訓練不要のアンラーニング手法である「Knowledge Vector Weakening(KVW)」を提案しています。KVWの核心的なアイデアは、モデルの重みを更新するための学習プロセスを一切行わず、推論時と同じ順伝播のプロセスのみを利用して、モデル内部の知識表現に直接介入するという点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related