連続制御におけるANNからSNNへの変換を阻む「誤差増幅」の壁
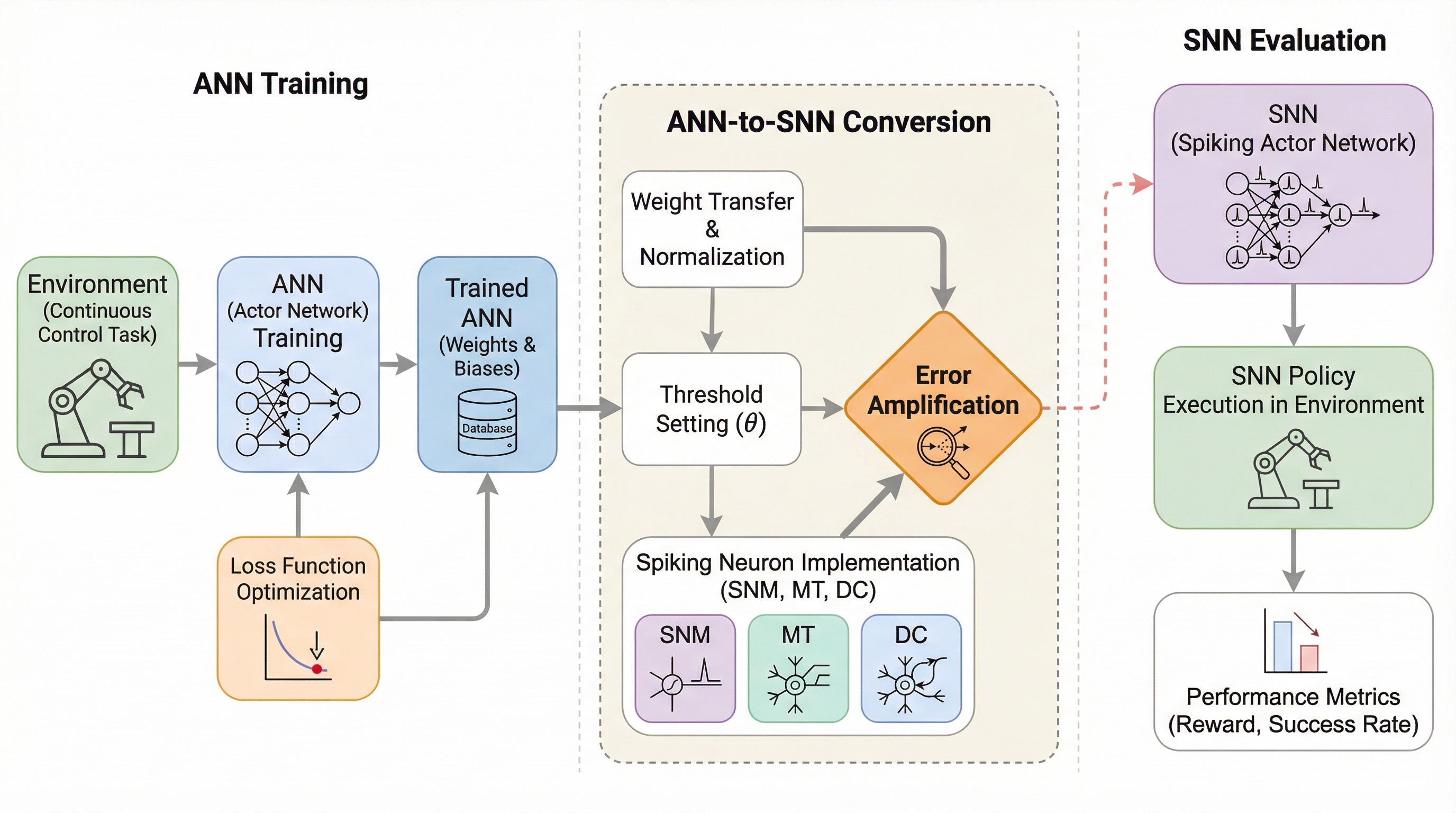
学習済みANNをSNNへ変換する手法は、連続制御タスクにおいて性能が著しく低下するが、その主因が微小な行動誤差の累積による「状態分布の乖離」と、誤差が時間的に正の相関を持つ「誤差増幅」にあることを突き止めた。
TL;DR(結論)
学習済みANNをSNNへ変換する手法は、連続制御タスクにおいて性能が著しく低下するが、その主因が微小な行動誤差の累積による「状態分布の乖離」と、誤差が時間的に正の相関を持つ「誤差増幅」にあることを突き止めた。 この課題を解決するため、追加学習を一切必要とせず、意思決定ステップ間でニューロンの膜電位の残差を引き継ぐことで時間的な誤差相関を抑制する軽量なメカニズム「Cross-Step Residual Potential Initialization(CRPI)」を提案した。 MuJoCoやDeepMind Control Suiteを用いた実験により、CRPIは既存の変換パイプラインに統合するだけで失われた性能を大幅に回復し、視覚ベースの複雑なタスクにおいては直接学習したSNNを上回るパフォーマンスを達成することを実証した。
なぜこの問題か
スパイクニューラルネットワーク(SNN)は、連続的な活性化値ではなく離散的なスパイクを用いて情報を伝達するため、イベント駆動型の計算が可能であり、ニューロモーフィックハードウェア上での消費電力を劇的に削減できるという優れた特性を持っている。この高いエネルギー効率は、ドローンやウェアラブルデバイス、あるいはIoTセンサといった、計算リソースや電力供給が厳しく制限されたエッジデバイス上での強化学習(RL)の実行において、極めて重要な利点となる。しかし、強化学習エージェントをゼロからSNNで学習させるプロセスは、環境との膨大な相互作用を必要とし、計算コストが高く、時間がかかるだけでなく、実世界のロボットなどでは物理的な危険を伴う可能性もある。 そこで、すでに十分に学習された人工ニューラルネットワーク(ANN)の重みを転送し、非線形活性化関数をスパイクニューロンに置き換える「ANNからSNNへの変換」という手法が、追加学習なしでANNの高性能を継承できる魅力的なパラダイムとして注目されてきた。これまでの研究では、画像分類やAtariゲームのような離散的なアクション空間を持つタスクにおいて、この変換手法が有効であることが示されてきた。…
核心:何を提案したのか
本研究の核心は、連続制御におけるSNNの性能低下が、単なる瞬間的な行動の誤りではなく、それによって引き起こされる「状態分布の乖離」が時間とともに増幅される現象、すなわち「誤差増幅」に起因することを解明した点にある。研究チームは、変換されたSNNポリシーが生成する状態軌道を詳細に分析し、意思決定ステップごとに生じる微小な近似誤差が、時間ステップを超えて正の相関を持つことを発見した。この正の相関により、誤差が打ち消されることなく一方方向に累積し、エージェントが本来あるべき状態から徐々に遠ざかっていくことで、最終的に壊滅的なパフォーマンス低下を招くのである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related