タスク表現を用いた効果的なLoRAアダプタールーティング
大規模言語モデルの効率的な専門化を実現するLoRAアダプターの膨大なプールから、入力クエリに最適なものを選択・統合する新しいルーティング枠組み「LORAUTER」が提案されました。 従来手法とは異なり、アダプターそのものの特性ではなく「タスク表現」を介してルーティングを行うことで、アダプターの学習データにアクセスできないブラックボックス設定でも動作し、タスク数に応じた高い拡張性を実現しています。 検証では、既存のタスクに最適化されたアダプターと同等以上の性能(101.2%)を達成したほか、未知のタスクに対しても従来手法を5.2ポイント上回る精度を示し、1500個以上のアダプターを含む大規模でノイズの多い環境でも堅牢に機能することが確認されました。
TL;DR(結論)
大規模言語モデルの効率的な専門化を実現するLoRAアダプターの膨大なプールから、入力クエリに最適なものを選択・統合する新しいルーティング枠組み「LORAUTER」が提案されました。 従来手法とは異なり、アダプターそのものの特性ではなく「タスク表現」を介してルーティングを行うことで、アダプターの学習データにアクセスできないブラックボックス設定でも動作し、タスク数に応じた高い拡張性を実現しています。 検証では、既存のタスクに最適化されたアダプターと同等以上の性能(101.2%)を達成したほか、未知のタスクに対しても従来手法を5.2ポイント上回る精度を示し、1500個以上のアダプターを含む大規模でノイズの多い環境でも堅牢に機能することが確認されました。
なぜこの問題か
現代の大規模言語モデル(LLM)は、自然言語処理の広範な分野で目覚ましい進歩を遂げていますが、特定のタスク(翻訳や要約など)に合わせて巨大なモデル全体を微調整することは、計算コストとメモリ消費の観点から非常に困難です。 この課題を解決するために、モデルの重みを凍結したまま少数のパラメータのみを更新するLoRA(Low-Rank Adaptation)のような手法が登場し、特定のタスクに特化した「アダプター」が数多く作成されるようになりました。 現在、HuggingFaceなどの公開プラットフォームには、特定のベースモデルに対して数千ものLoRAアダプターが存在しており、これらを効果的に活用するためには、ユーザーのクエリに応じて適切なアダプターを選択・統合する「ルーティング」が不可欠な技術となっています。 しかし、既存のルーティング手法にはいくつかの重大な欠陥があり、例えば多くのアプローチではアダプターの学習データへのアクセスが必要ですが、公開されているアダプターの多くは学習データが非公開であるため、実用上の大きな障壁となっています。…
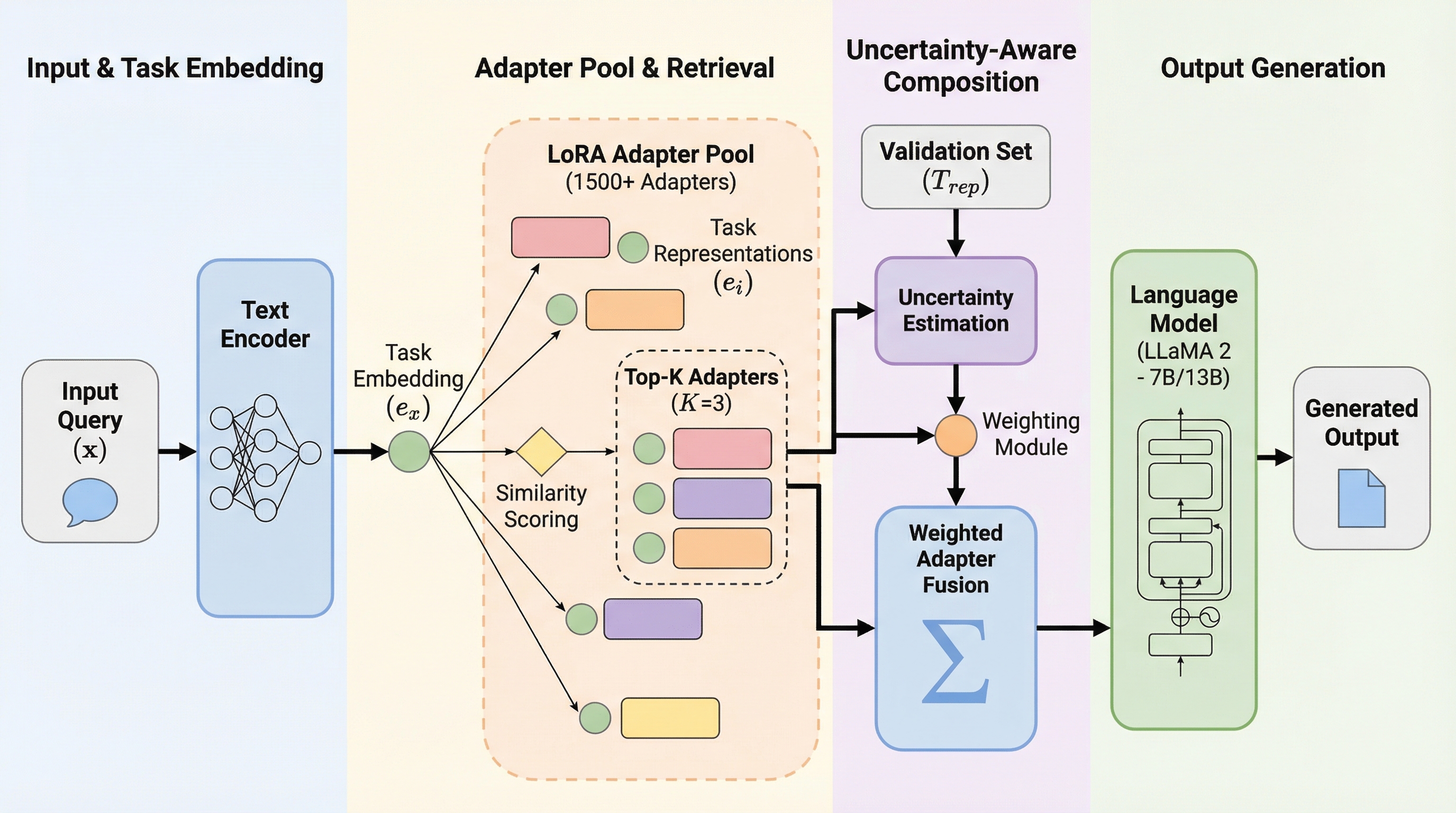
核心:何を提案したのか
本研究では、LoRAアダプターのルーティングを「タスクレベル」で行う新しいトレーニングフリーのフレームワーク「LORAUTER」を提案しています。 LORAUTERの最大の特徴は、クエリを直接アダプターに結びつけるのではなく、まずクエリを意味的な「タスククラスター」にマッピングし、そのタスクに最適なアダプターを呼び出すという、タスク表現を介した仲介プロセスを導入した点にあります。 この設計により、アダプターの学習データが一切不要な「ブラックボックス」設定での運用が可能となり、プライバシーや機密性の観点からデータが提供されない公開アダプタープールでも柔軟に利用できるようになりました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related