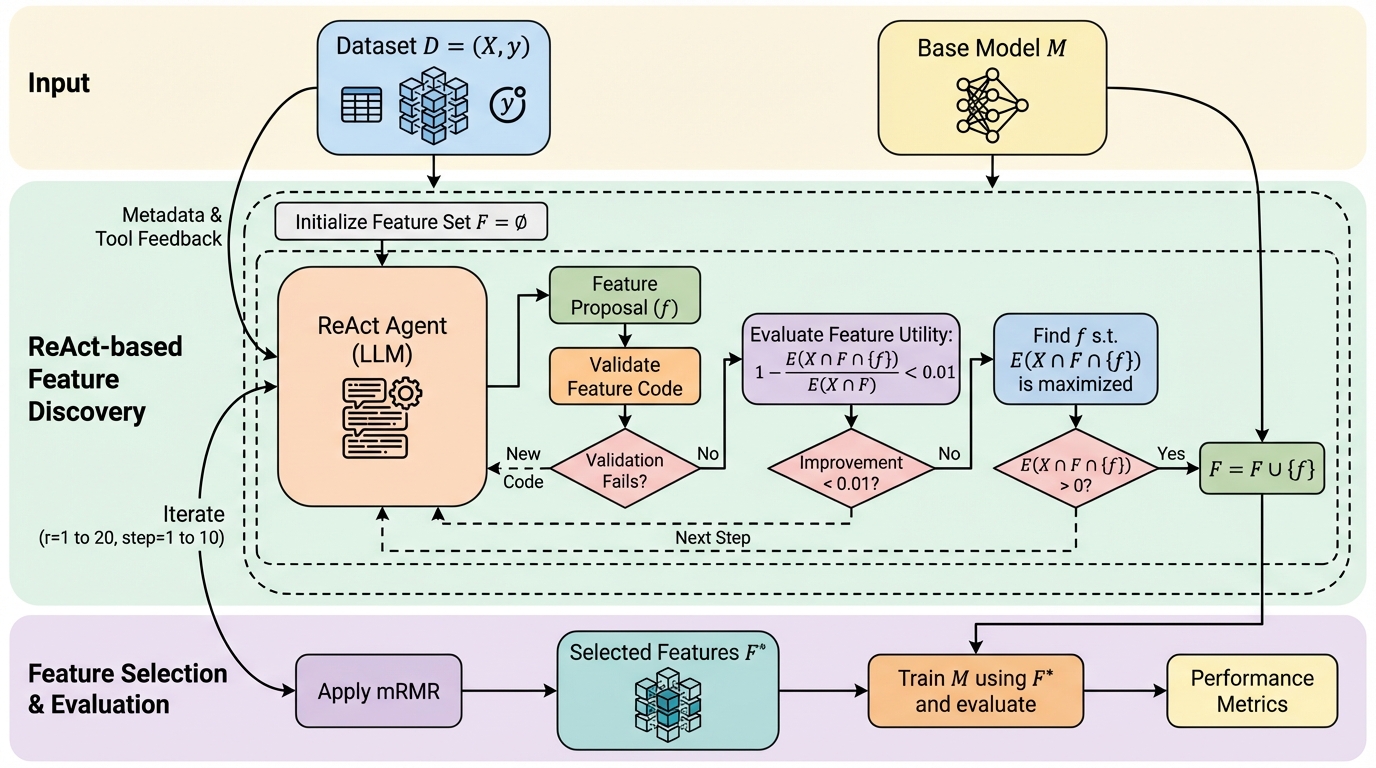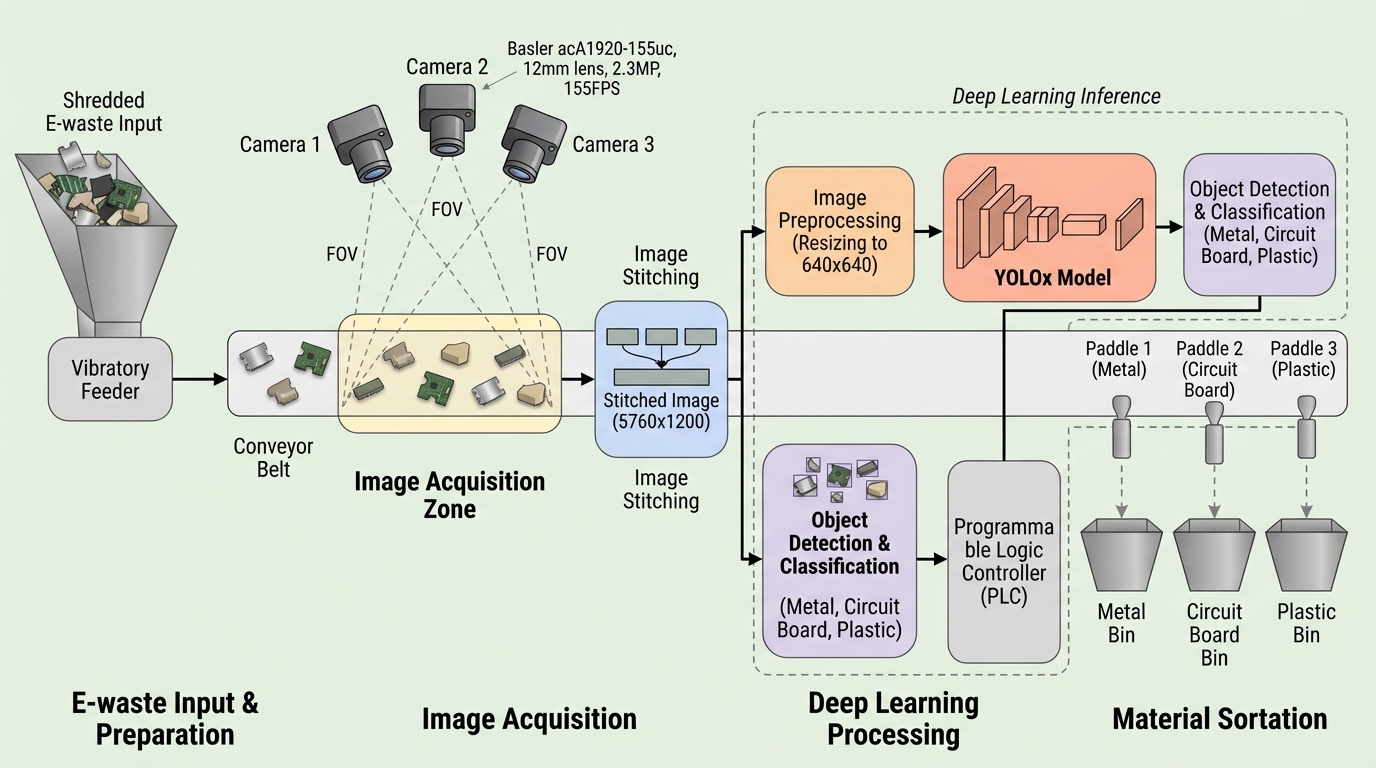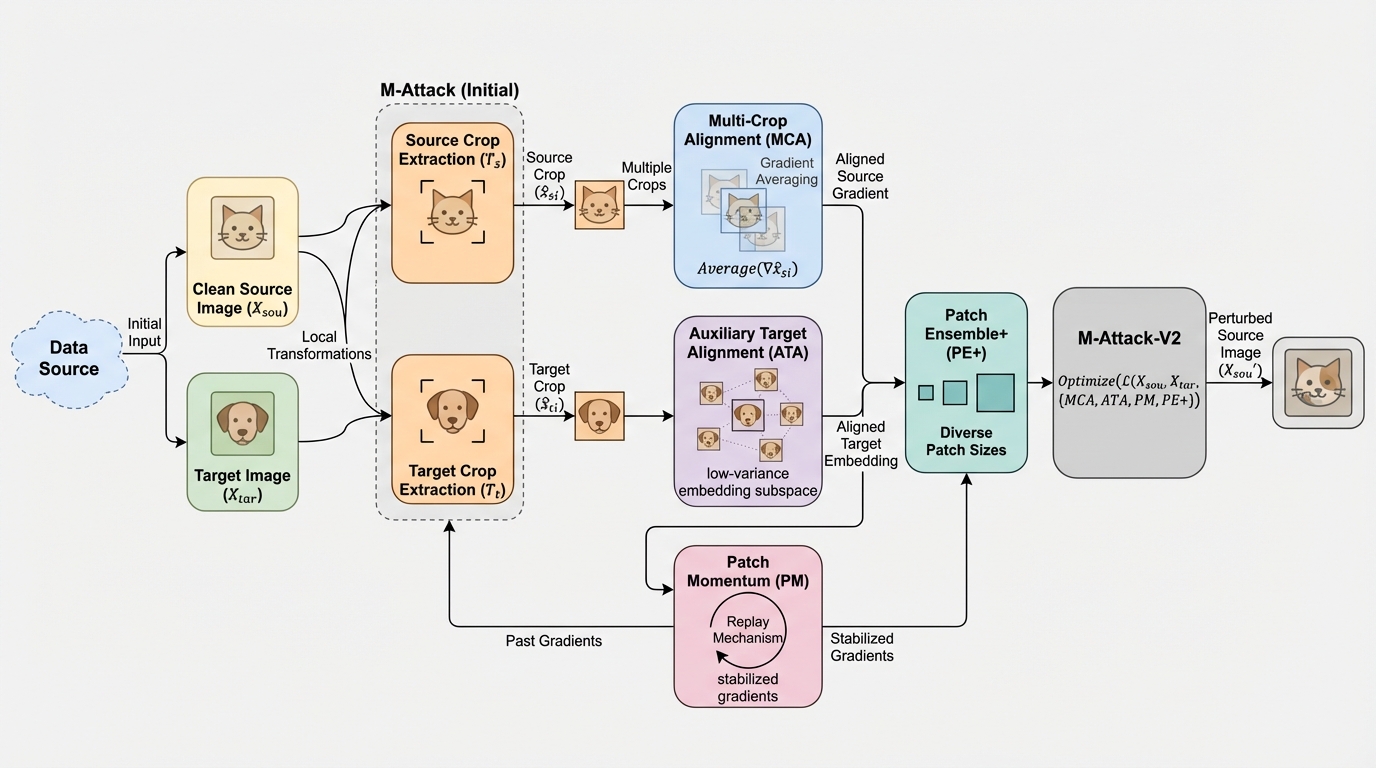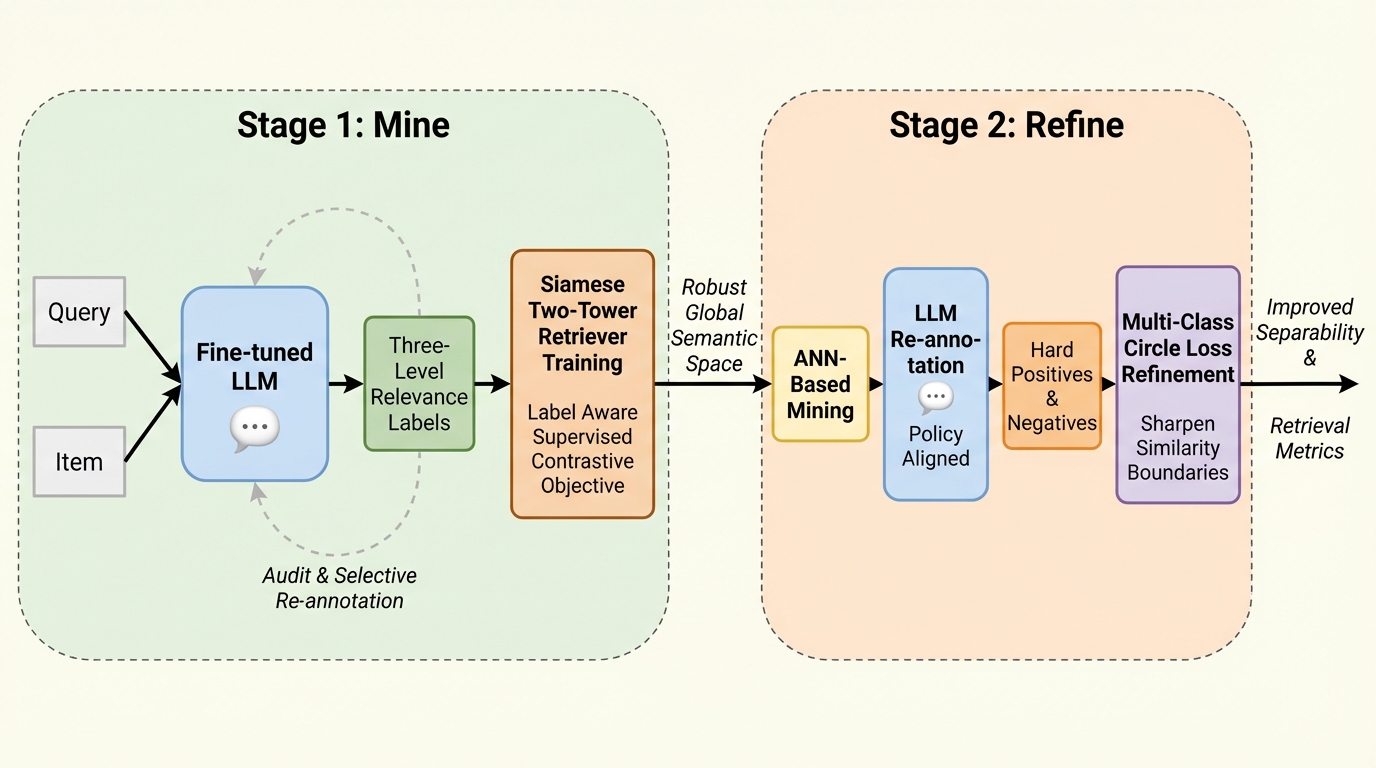
ノイズの幾何学:なぜ拡散モデルはノイズ条件付けを必要としないのか
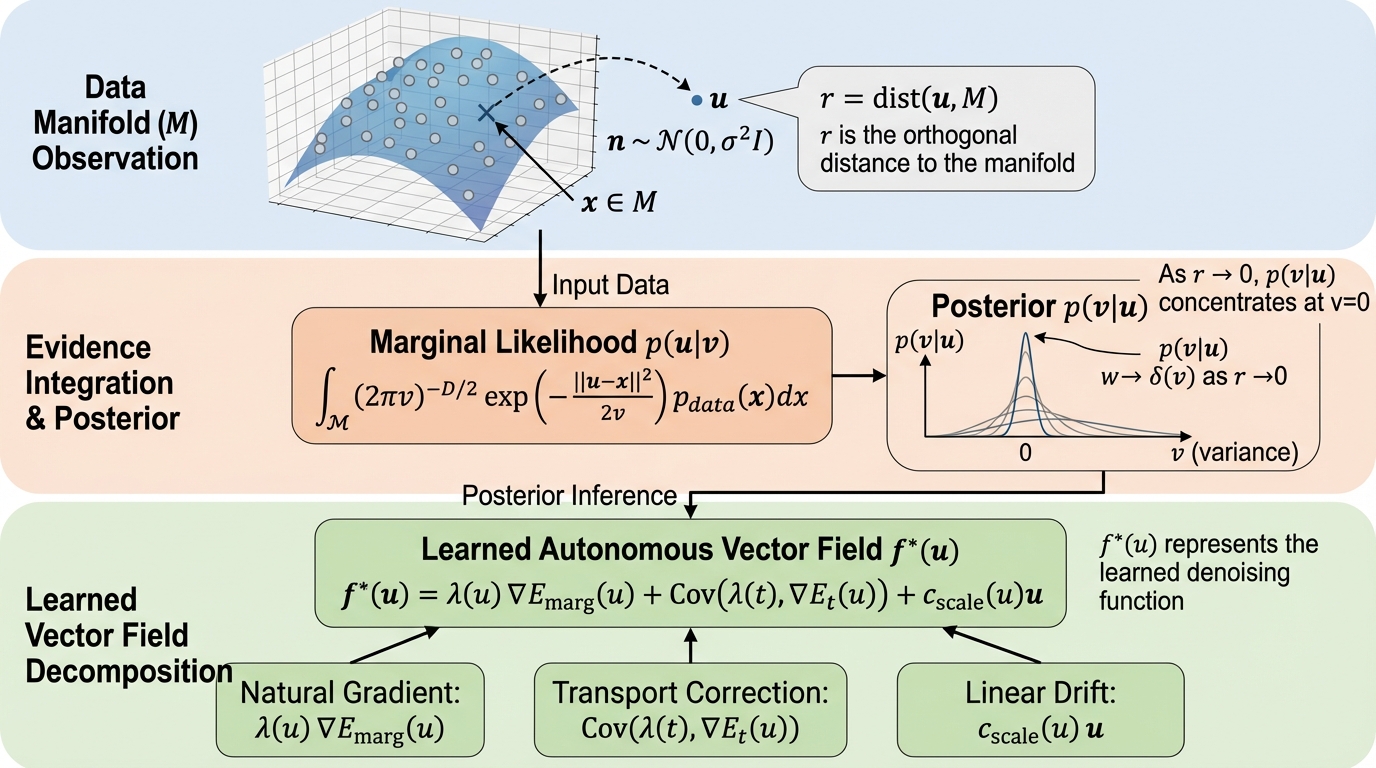
ノイズレベルを入力しない自律(ノイズ非依存)生成モデルでも、学習された単一の時間不変ベクトル場は「闇雲なデノイズ」ではなく、未知ノイズを周辺化した周辺密度 \(p(\mathbf{u})=\int p(\mathbf{u}\mid t)p(t)\,dt\) に対応する周辺エネルギー \(E_{\text{marg}}(\mathbf{u})=-\log p(\mathbf{u})\) の幾何と結び付いています。 / ただし周辺エネルギーの生の勾配はデータ多様体の法線方向に \(1/t^p\) 型の特異性を持ち、通常の勾配降下では不安定になり得ますが、論文は相対エネルギー分解により、学習場が局所的な共形計量(実効ゲイン)を暗黙に含むリーマン勾配流として振る舞い、特異性を前処理して打ち消す構図を示します。 / さらに自律サンプリングの構造安定性条件を与え、ノイズ予測パラメータ化には推定誤差を増幅し得る「Jensen Gap」がある一方、速度ベースのパラメータ化は有界ゲイン条件により後部分布の不確実性を滑らかな幾何学的ドリフトへ吸収できる、という含意を導きます。