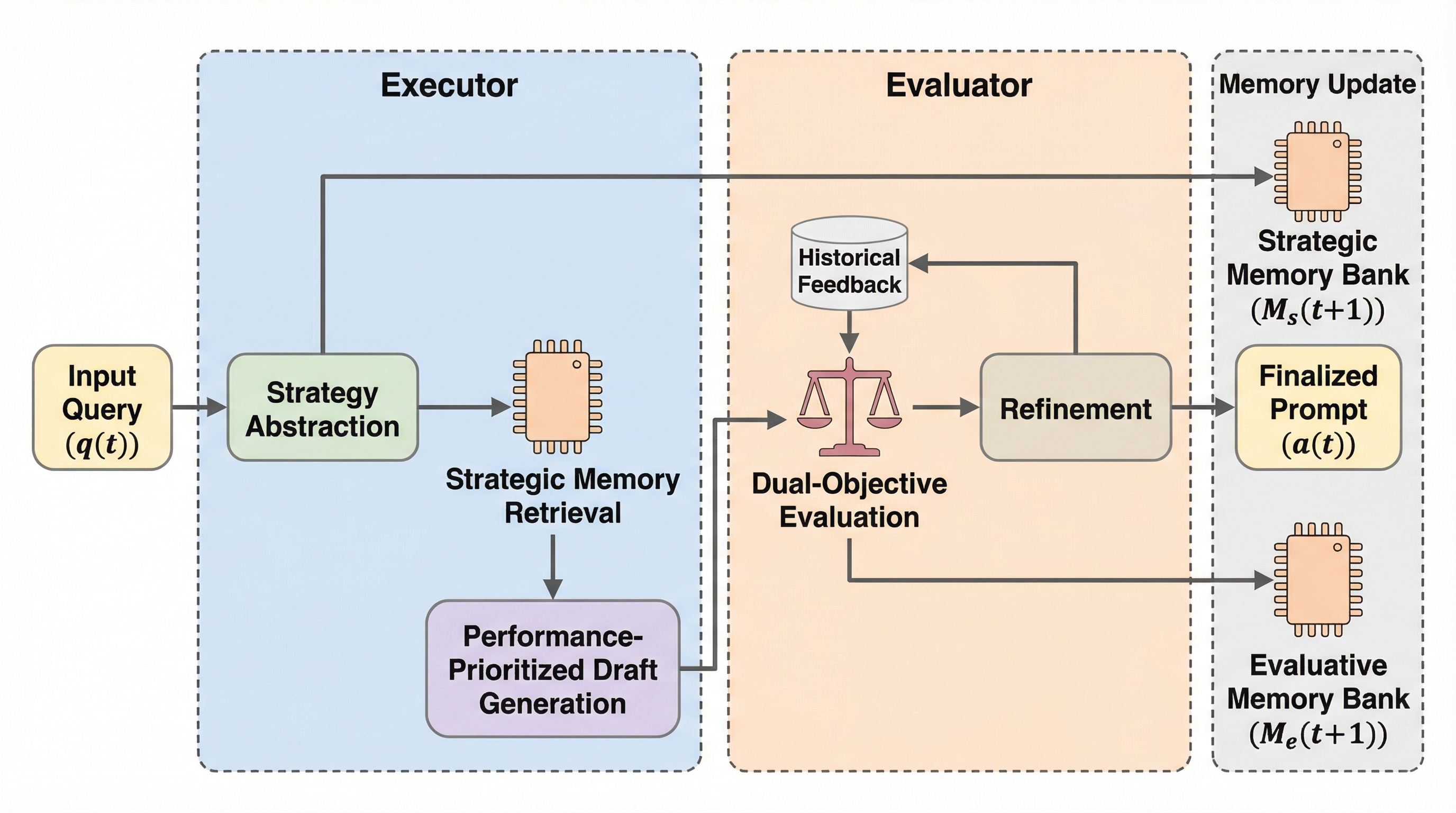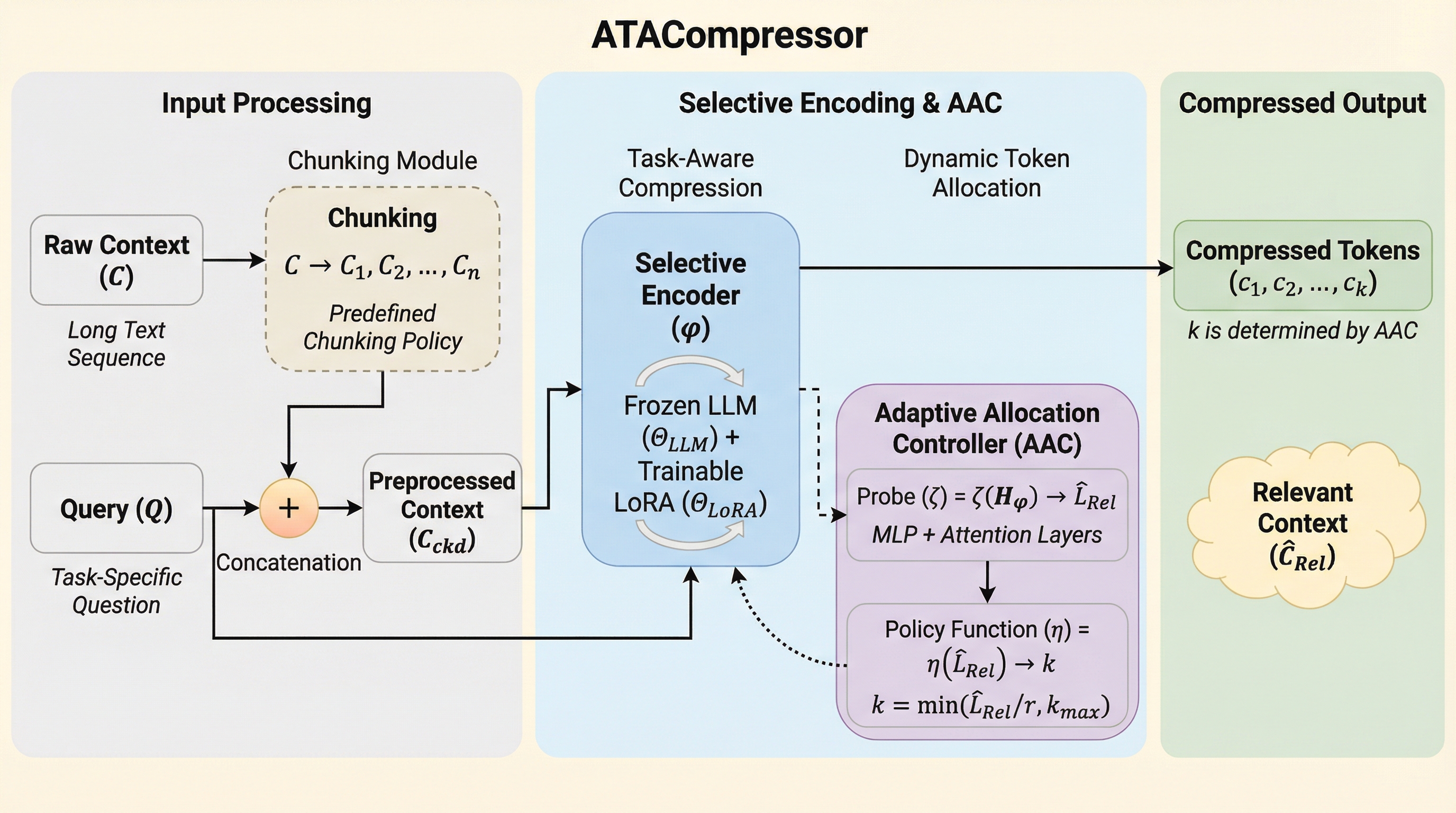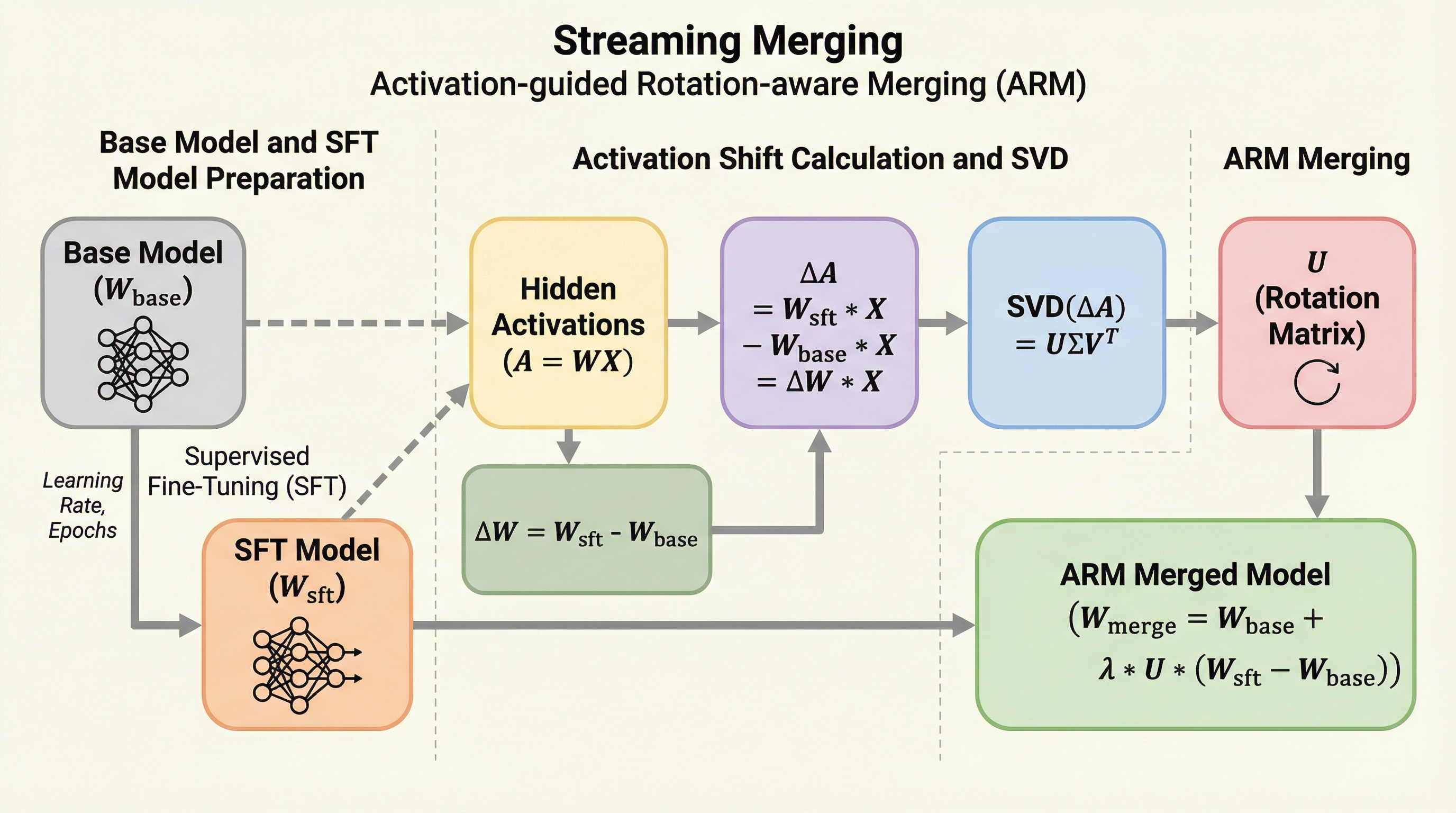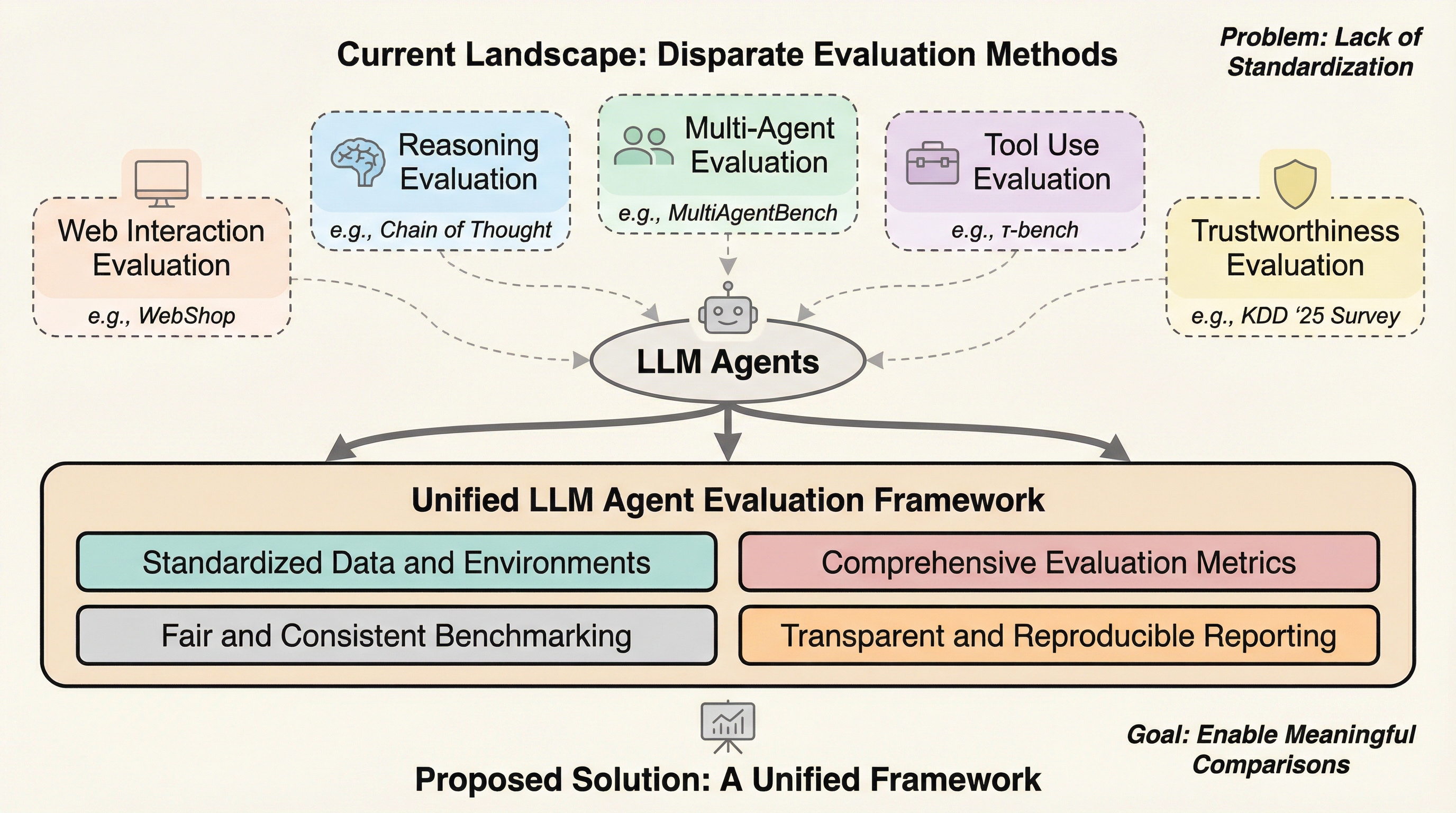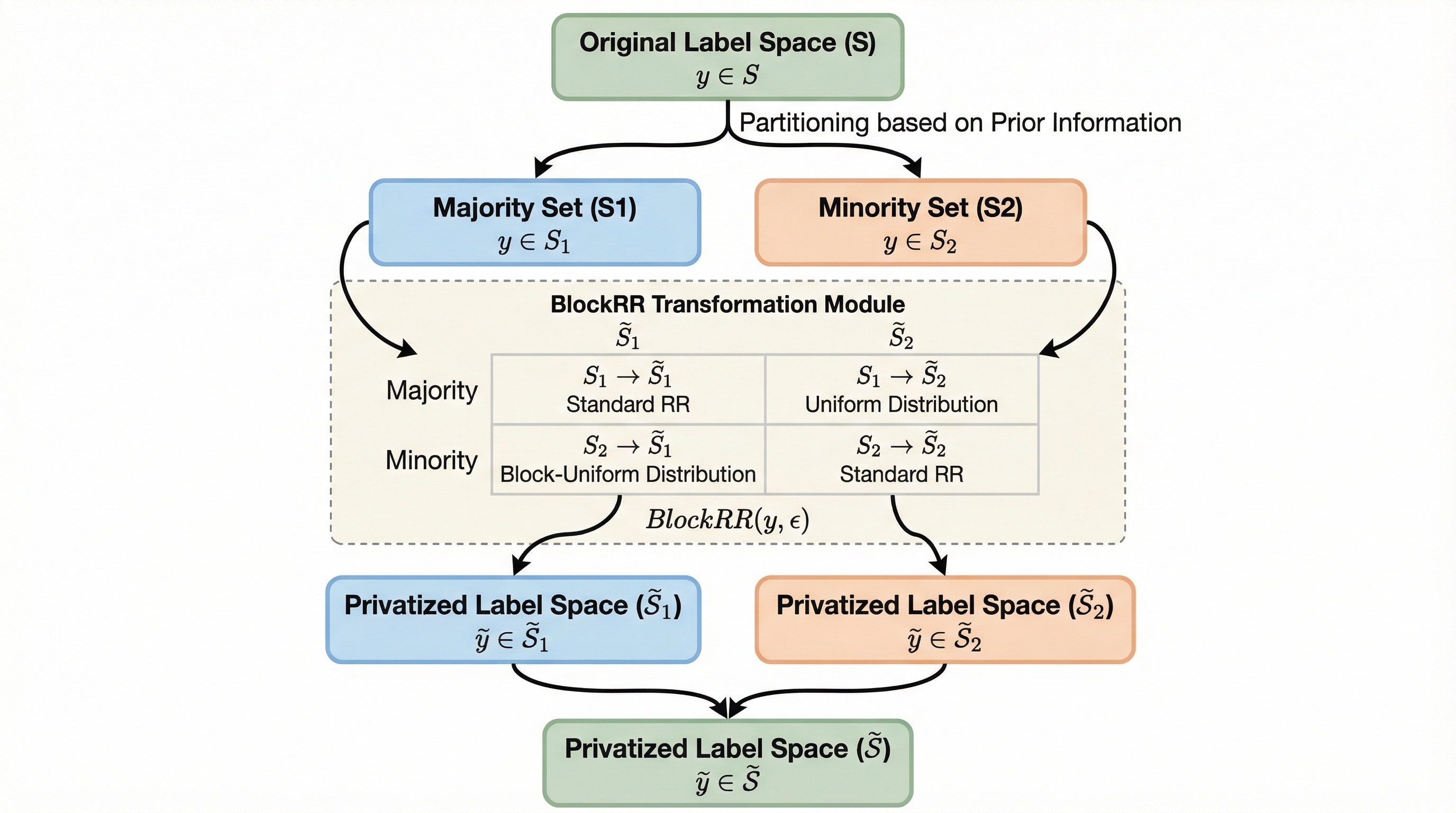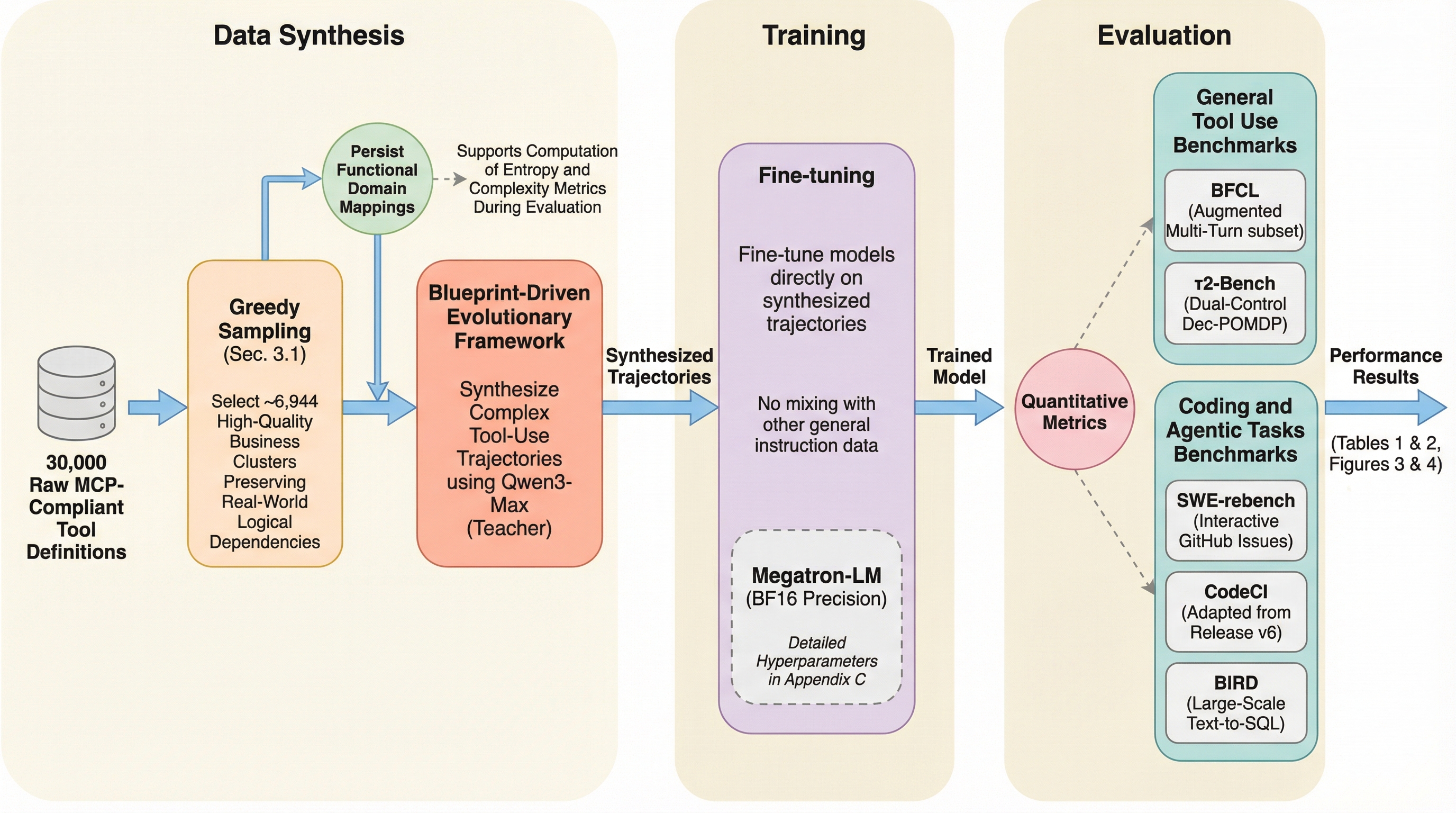
量を超えて:コードエージェントのための軌跡の多様性のスケーリング
従来のコードエージェント学習は合成データの「量」に依存していましたが、低品質なデータの蓄積による性能の飽和と、未知のツールへの適応力不足という限界に直面していました。本研究が提案する「TDScaling」は、データの量ではなく「軌跡の多様性」を優先する新しいフレームワークであり、ビジネスクラスタリングや適応的な進化メカニズムを通じて、極めて高いデータ効率を実現します。検証の結果、わずか500件の多様なデータで学習した30B規模のモデルが、標準的なデータで学習した480B規模の巨大モデルを凌駕する性能を示し、ツール利用能力と本来のコード生成能力を同時に向上させることに成功しました。