LLMベースのエージェント評価における統一フレームワークの必要性
現在の大規模言語モデル(LLM)を基盤としたエージェントの評価は、研究者ごとに異なる独自のフレームワークに依存しており、システムプロンプトやツールの設定、環境の動態といった外部要因が評価結果に大きな影響を与えている。
TL;DR(結論)
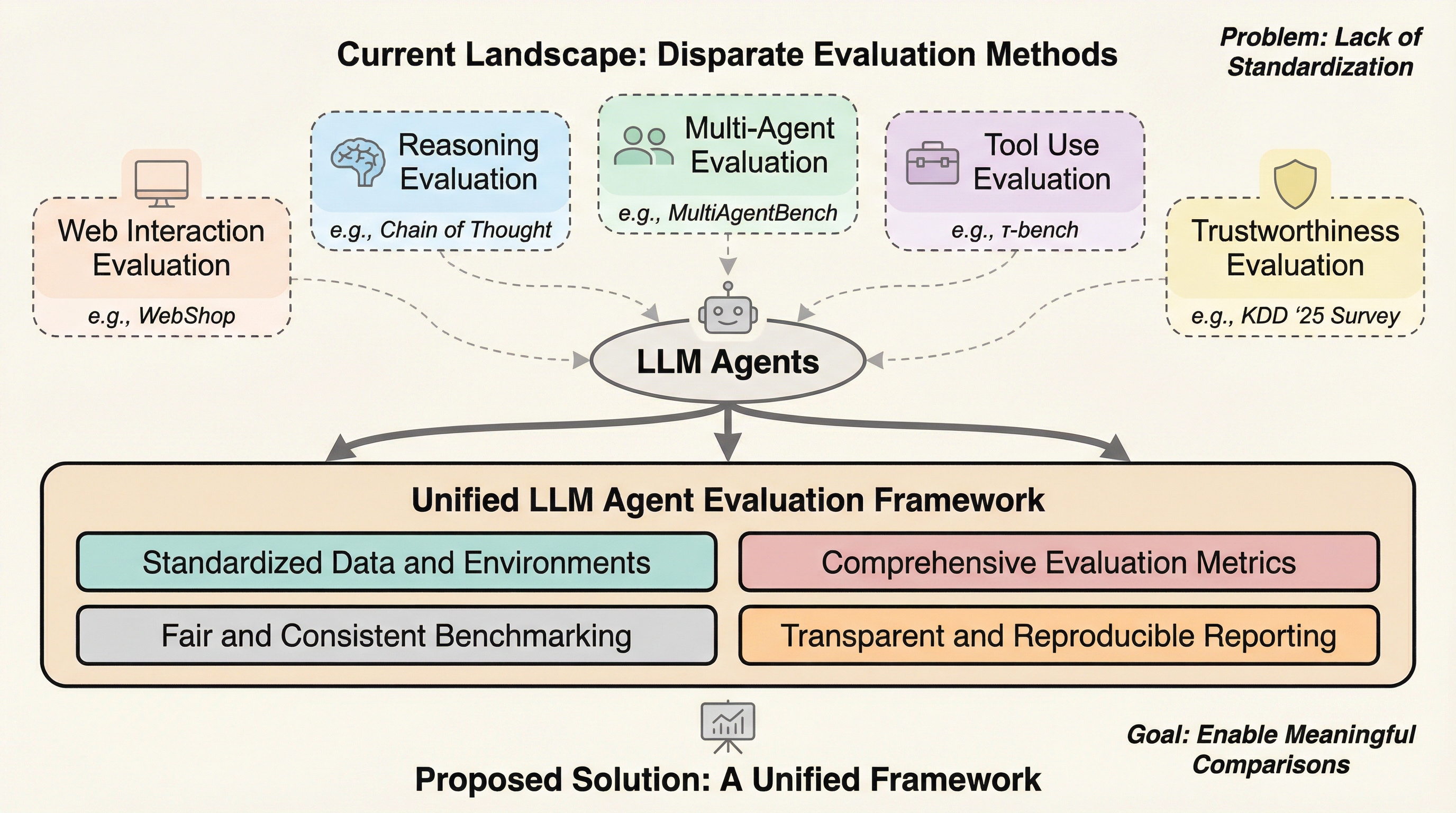
現在の大規模言語モデル(LLM)を基盤としたエージェントの評価は、研究者ごとに異なる独自のフレームワークに依存しており、システムプロンプトやツールの設定、環境の動態といった外部要因が評価結果に大きな影響を与えている。既存のベンチマークでは、性能の向上がモデル自体の能力によるものか、あるいは特定のプロンプトエンジニアリングやメモリ管理手法によるものかが判別できず、評価の公平性や再現性が著しく損なわれているという構造的な欠陥が指摘されている。本論文は、エージェント評価の厳密な進展には「サンドボックス」と「評価手法」を標準化した統一フレームワークが不可欠であると主張し、モデル本来の能力を正確に測定するための具体的な標準化案を提示している。
なぜこの問題か
従来のLLM評価は、固定されたプロンプトに対して回答の質を測定する静的な入力・出力システムとして機能してきた。これらは言語理解や数学的推論、コード生成といった基礎的な能力を測るには有効であったが、LLMがエージェントとして展開されるようになると、この評価パラダイムは不十分なものとなる。エージェントは単なる受動的な応答者ではなく、計画立案やメモリ、外部ツールとの相互作用を通じて環境を変化させながら多段階の意思決定を行う統合システムである。そのため、評価の対象は単一の出力から、エージェントと変化し続ける環境状態との間のクローズドループな相互作用の結果へと拡大している。しかし、エージェントの能力を測定するためのベンチマークが急速に増加している一方で、それらは孤立した研究者独自のフレームワーク内で開発されている。その結果、ベンチマークの結果が特定の環境設計やシステムプロンプト、メモリメカニズムと密接に結びついてしまっている。このような現状では、報告された性能向上がモデル本来の自律的な意思決定能力の向上を反映しているのか、それともフレームワーク固有の設計選択による副産物なのかを区別することが困難である。…
核心:何を提案したのか
本論文は、LLMベースのエージェント評価における統一フレームワークの構築が、単なる選択肢ではなく「必須」であるという立場を明確にしている。提案の核心は、エージェント評価を構成する要素を「サンドボックス(実行環境)」と「評価手法」の2つの主要な要素に分解し、それぞれが満たすべき特性を定義することにある。これにより、外部要因による変動を最小限に抑え、観察された性能差をLLMのエージェントとしての能力そのものに帰属させることを目指している。具体的には、推論設定、プロンプトと計画戦略、メモリメカニズム、ツールの呼び出し、そして外部環境という5つの主要な変動要因を分析し、これらを標準化することを提案している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related