接尾辞を超えて:大規模言語モデルに対するGCG敵対的攻撃におけるトークン位置
大規模言語モデル(LLM)に対する主要なジェイルブレイク攻撃であるGCGは、従来はプロンプトの末尾に敵対的トークンを付加する手法が一般的であったが、本研究ではトークンの配置場所が攻撃の成功率に与える影響を詳細に調査した。
TL;DR(結論)
大規模言語モデル(LLM)に対する主要なジェイルブレイク攻撃であるGCGは、従来はプロンプトの末尾に敵対的トークンを付加する手法が一般的であったが、本研究ではトークンの配置場所が攻撃の成功率に与える影響を詳細に調査した。 敵対的トークンを接頭辞(プレフィックス)として最適化したり、評価時に配置を変更したりすることで、従来の接尾辞(サフィックス)固定の評価よりも攻撃成功率が大幅に向上し、モデル間の転移性も高まることが明らかになった。 既存の安全性評価は特定の配置のみを想定しているため、潜在的なリスクを過小評価している可能性があり、今後はトークンの構造的な配置を考慮したより堅牢な評価手法の構築が不可欠であると結論付けている。
なぜこの問題か
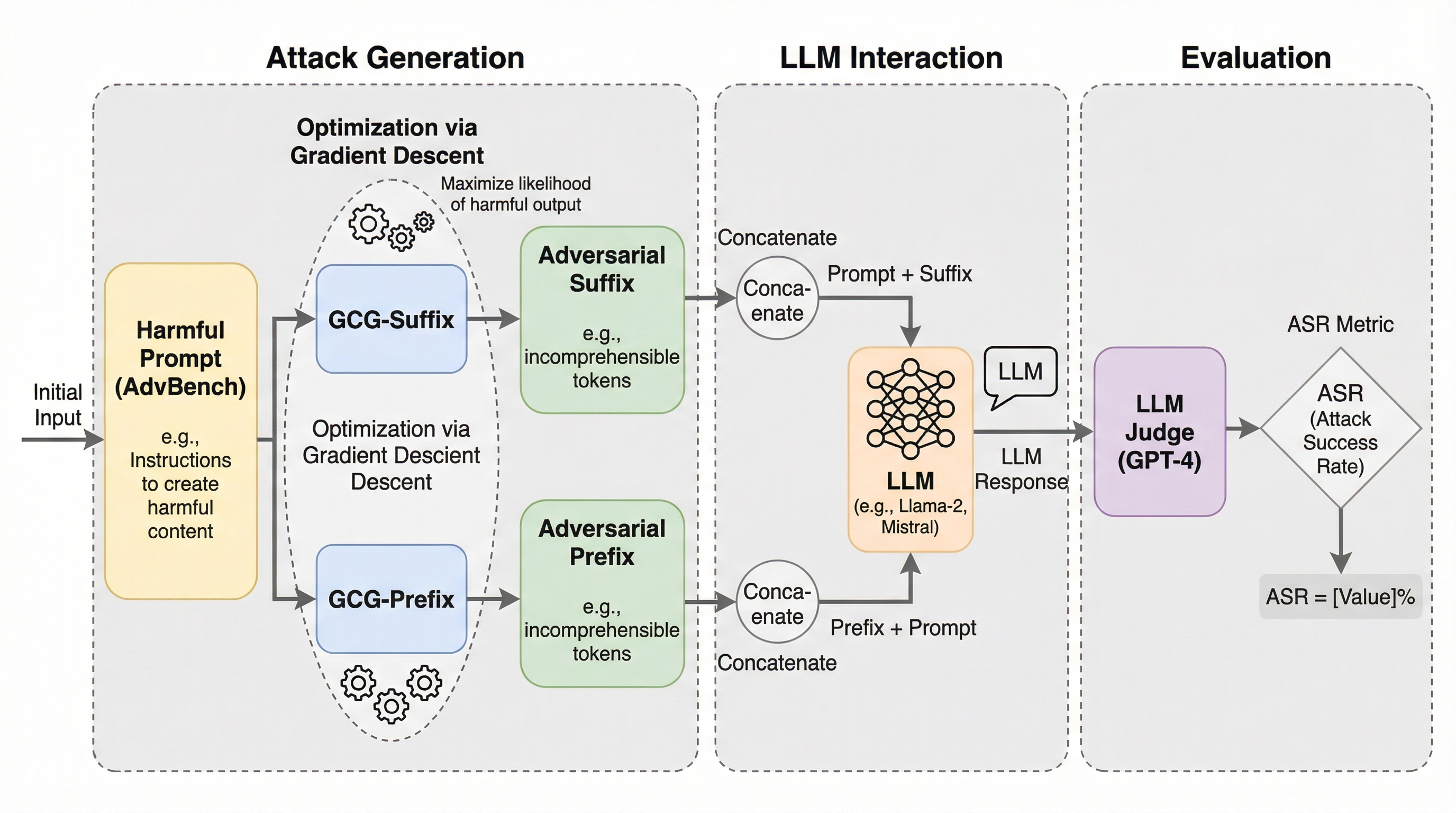
大規模言語モデル(LLM)は、自然言語処理の基盤として、感情分析のような理解タスクからコード生成のような生成タスクに至るまで、極めて幅広い分野で活用されている。Llamaなどのモデルは、その高い性能から実世界の対話システムに深く統合されているが、普及に伴って安全性とセキュリティの確保が喫緊の課題となっている。現在の最先端モデルには、有害なコンテンツや不適切な出力を抑制するための安全性アライメント機構が備わっているが、悪意のあるプロンプトを用いてこれらの制約を回避する「ジェイルブレイク攻撃」に対しては依然として脆弱である。ジェイルブレイクに成功すると、マルウェアの作成、化学兵器や生物兵器の設計、あるいはサイバー虐待といった、社会的に極めて有害な目的にLLMが悪用される危険性がある。 既存の攻撃手法の中でも、Greedy Coordinate Gradient(GCG)攻撃は、モデルの勾配情報を利用して離散的なトークンを最適化する強力なホワイトボックス攻撃として知られている。しかし、これまでのGCG攻撃に関する研究の多くは、敵対的なトークンをプロンプトの末尾に追加する「サフィックス(接尾辞)」形式にのみ焦点を当ててきた。…
核心:何を提案したのか
本研究は、敵対的トークンを常にサフィックスとして扱うという従来の慣習に疑問を投げかけ、プロンプト内での配置場所自体が重要な攻撃軸であることを提案している。具体的には、標準的なGCG攻撃を拡張し、敵対的トークンをプロンプトの先頭に配置して最適化する「GCG-Prefix」という手法を導入した。これにより、従来の「GCG-Suffix」との比較を通じて、トークンの位置が攻撃成功率(ASR)にどのような変化をもたらすかを体系的に分析している。研究チームは、単に最適化時の位置を変えるだけでなく、生成された敵対的トークンを評価時に別の位置へ移動させた場合の影響も詳細に調査した。 例えば、サフィックスとして最適化されたトークンをプレフィックスとして配置して評価する、あるいはその逆を行うといったバリエーションを検証している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related