量を超えて:コードエージェントのための軌跡の多様性のスケーリング
従来のコードエージェント学習は合成データの「量」に依存していましたが、低品質なデータの蓄積による性能の飽和と、未知のツールへの適応力不足という限界に直面していました。本研究が提案する「TDScaling」は、データの量ではなく「軌跡の多様性」を優先する新しいフレームワークであり、ビジネスクラスタリングや適応的な進化メカニズムを通じて、極めて高いデータ効率を実現します。検証の結果、わずか500件の多様なデータで学習した30B規模のモデルが、標準的なデータで学習した480B規模の巨大モデルを凌駕する性能を示し、ツール利用能力と本来のコード生成能力を同時に向上させることに成功しました。
TL;DR(結論)
従来のコードエージェント学習は合成データの「量」に依存していましたが、低品質なデータの蓄積による性能の飽和と、未知のツールへの適応力不足という限界に直面していました。本研究が提案する「TDScaling」は、データの量ではなく「軌跡の多様性」を優先する新しいフレームワークであり、ビジネスクラスタリングや適応的な進化メカニズムを通じて、極めて高いデータ効率を実現します。検証の結果、わずか500件の多様なデータで学習した30B規模のモデルが、標準的なデータで学習した480B規模の巨大モデルを凌駕する性能を示し、ツール利用能力と本来のコード生成能力を同時に向上させることに成功しました。
なぜこの問題か
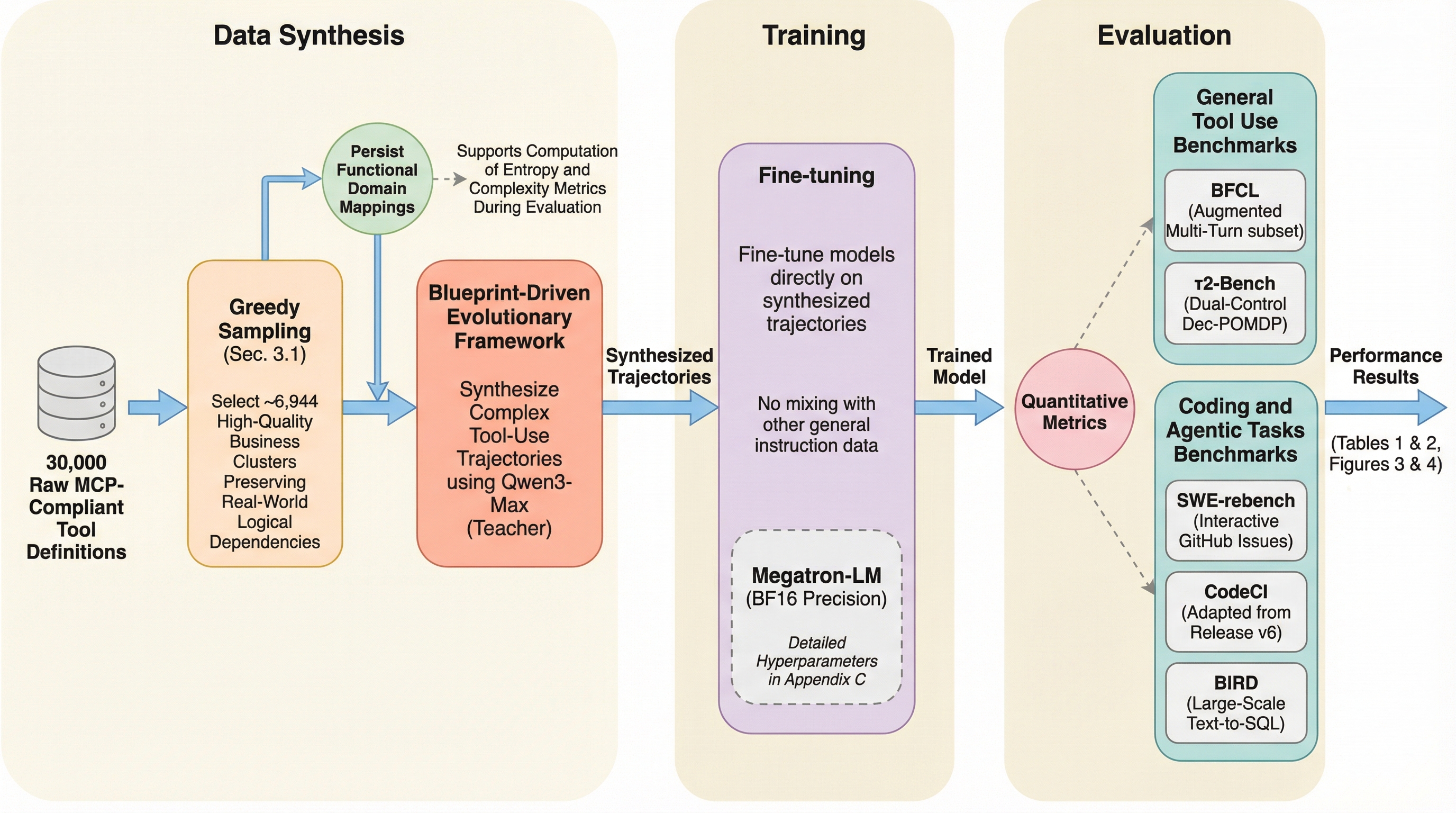
ソフトウェア開発の形態が進化する中で、AIモデルは単にコードを生成するだけでなく、Model Context Protocol(MCP)などのプロトコルを介して外部ツールを自在に操作する「エージェント」としての役割を期待されています。しかし、既存のコードLLM(大規模言語モデル)には深刻な課題が存在します。第一に、多くのモデルは学習時に経験した特定のAPIのパターンを暗記しているだけであり、未知のツールインターフェースや複雑な相互作用が必要な場面では、推論能力が著しく低下するという点です。これは、モデルが文脈から新しい仕様を理解する「インコンテキスト推論」ではなく、過去の記憶に頼る「パラメトリック想起」に依存していることを示唆しています。 第二に、この問題を解決するために合成データの「量」を増やすという従来のアプローチが、早期に性能の限界(ボトルネック)に達しているという事実があります。既存のデータセットはドメインが均一で、単純かつ反復的な操作に偏る傾向があります。…
核心:何を提案したのか
本研究は、データの量(Quantity)ではなく多様性(Diversity)に焦点を当てた合成データ生成フレームワーク「TDScaling(Trajectory Diversity Scaling)」を提案しています。このフレームワークの核心は、限られたトレーニング予算の中で、軌跡の多様性を高めることが、単に軌跡の数を増やすことよりも大きな性能向上をもたらすという「多様性スケーリング」の概念を確立した点にあります。TDScalingは、主に4つの革新的な要素で構成されています。 第一に、現実のサービスの論理的な依存関係を再現するために、MCPサーバーを「ビジネスクラスタ」として整理する仕組みを導入しました。これにより、個々のAPIをバラバラに扱うのではなく、関連するツール群を一つのサービス単位として捉え、意味的な広がりを最大化するようにサンプリングすることが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related