BlockRR: ラベル差分プライバシーのための統合されたランダム化回答フレームワーク
BlockRRは、既存の多様なランダム化回答(RR)手法を一つの数理的枠組みで統合し、ラベル空間を多数派と少数派のブロックに分割して制御する新しいラベル差分プライバシー(Label DP)フレームワークである。
TL;DR(結論)
BlockRRは、既存の多様なランダム化回答(RR)手法を一つの数理的枠組みで統合し、ラベル空間を多数派と少数派のブロックに分割して制御する新しいラベル差分プライバシー(Label DP)フレームワークである。 この手法は、事前情報に基づいた重み行列を活用してラベルの摂動確率を動的に最適化することで、高いプライバシー保護強度($\epsilon \le 3.0$)においても、特定のクラスが学習不能になる「クラス崩壊」を防ぎ、全体の精度とクラス間の公平性を高い水準で両立させる。 不均衡なデータセットを用いた検証では、従来のRRWithPriorなどの手法で見られた性能の不安定さや分散を大幅に軽減し、プライバシー予算が潤沢な場合には標準的なRRへと自動的に収束する柔軟性を備えていることが実証された。
なぜこの問題か
現代のデータ駆動型社会において、広告のクリック予測や社会調査、医療データの分析など、個人の機密情報を含むデータの活用は不可欠となっている。しかし、これらのデータには個人の嗜好や行動、特定の属性といった極めて敏感な情報が含まれており、プライバシー保護が大きな課題となっている。従来の差分プライバシー(DP)は、データセット内の特徴量とラベルの両方を一括して保護対象とするが、実世界の多くのシナリオでは、ユーザーの行動履歴などの特徴量自体は公開可能であっても、その結果としての「ラベル(クリックの有無や具体的な回答内容)」のみが秘匿されるべき情報である場合が多い。このような背景から、保護の対象をラベルのみに限定することで、同じプライバシー予算($\epsilon$)の下でより高いモデルの有用性を引き出す「ラベル差分プライバシー(Label DP)」という概念が注目を集めている。 ラベル差分プライバシーを実現するための主要な技術として、1965年に提案されたランダム化回答(RR)メカニズムがある。これは、真のラベルを一定の確率で別のラベルに変換(摂動)することで、個々のデータの真の値を隠蔽しつつ、統計的な性質を維持する手法である。…
核心:何を提案したのか
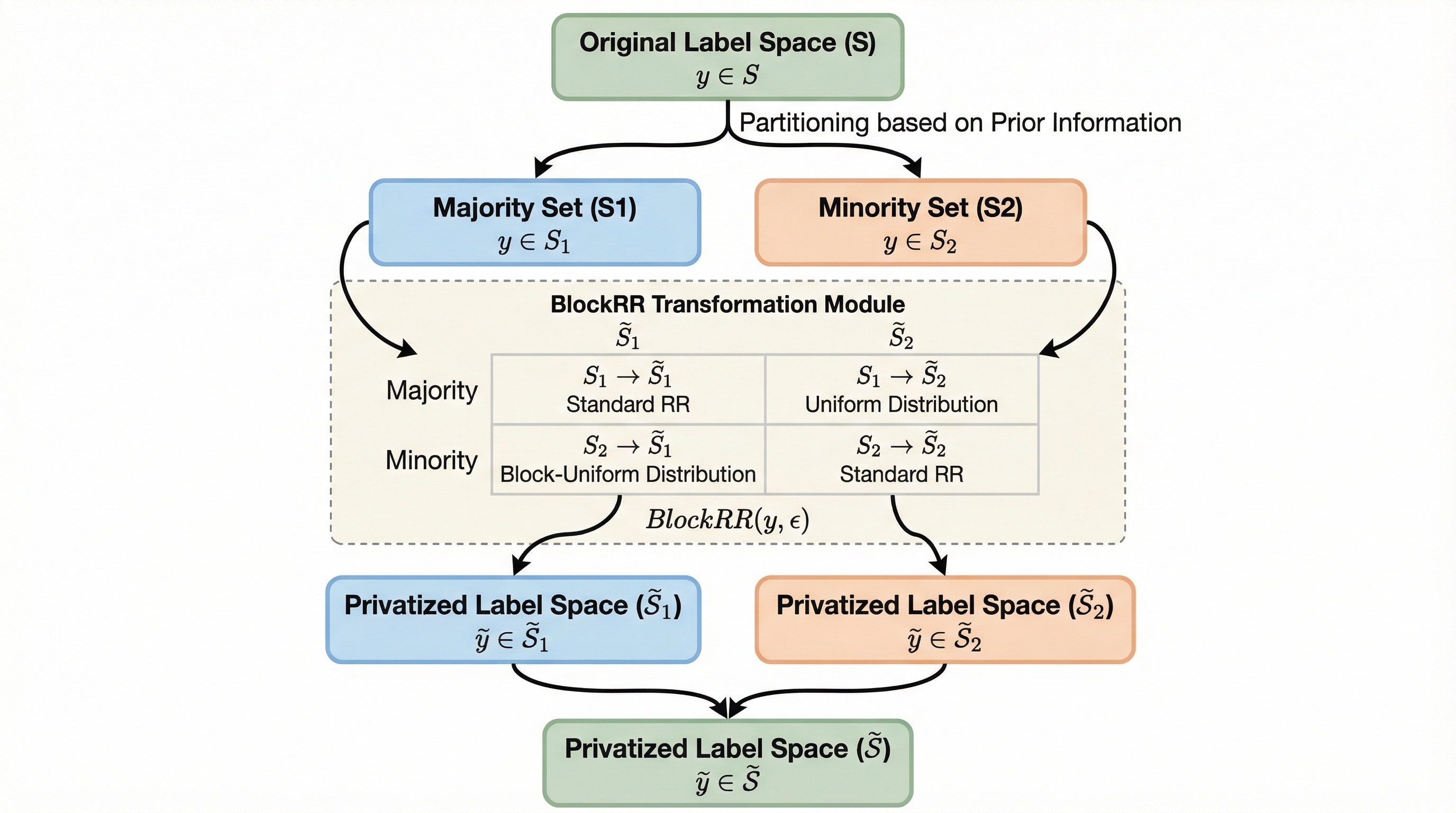
本研究の核心的な提案は、ラベル差分プライバシーのための統合されたランダム化回答メカニズムである「BlockRR」の構築である。このフレームワークの最大の特徴は、元のラベル空間とプライバシー保護後のラベル空間を複数の「ブロック」に分割し、それぞれのブロックの組み合わせに対して個別に調整された摂動ルールを適用するという点にある。具体的には、データセット内で頻出する多数派ラベルの集合($S1$)と、出現頻度が低い、あるいは重要度が相対的に低い少数派ラベルの集合($S2$)に分割する。そして、出力されるラベル空間もこれに対応する形で分割し、入力と出力のペアを四つの領域(クアドラント)として定義する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related