TAME:体系的なベンチマークによる信頼性の高いエージェントメモリのテスト時進化
テスト時の学習において、エージェントが経験を蓄積して推論能力を高める過程で、安全性の調整が損なわれる「エージェントメモリの誤進化」という現象が課題となっている。 この現象を評価するため、数学、科学、ツール利用の3領域を網羅し、安全性、堅牢性、真実性、プライバシー、公平性の5次元で信頼性を測定する初のベンチマーク「Trust-Memevo」を構築した。 実行者と評価者のメモリを分離した二層構造フレームワーク「TAME」を提案し、憲法的な制約に基づくフィルタリングと洗練を通じて、タスクの有用性と信頼性の両立を達成した。
TL;DR(結論)
テスト時の学習において、エージェントが経験を蓄積して推論能力を高める過程で、安全性の調整が損なわれる「エージェントメモリの誤進化」という現象が課題となっている。 この現象を評価するため、数学、科学、ツール利用の3領域を網羅し、安全性、堅牢性、真実性、プライバシー、公平性の5次元で信頼性を測定する初のベンチマーク「Trust-Memevo」を構築した。 実行者と評価者のメモリを分離した二層構造フレームワーク「TAME」を提案し、憲法的な制約に基づくフィルタリングと洗練を通じて、タスクの有用性と信頼性の両立を達成した。
なぜこの問題か
人工汎用知能(AGI)の実現に向けた核心的なビジョンの一つは、継続的な相互作用から自律的に学習できるエージェントを構築することにある。近年、大規模なパラメータ更新を必要とせずに、経験の蓄積を通じて複雑な推論能力を強化する「テスト時メモリ進化」が、有望かつ効率的なパラダイムとして注目を集めている。この手法は、過去の実行軌跡を経験として変換し、抽象化された戦略を再利用することで、動的なオープンワールド環境に適応し、性能の限界を克服することを可能にする。しかし、既存の進化戦略の多くは、タスクの成功率を唯一の報酬信号として利用しており、進化の過程における安全性の調整を軽視しているという重大な欠陥がある。 最新の研究によれば、たとえ悪意のないタスクを通じた進化であっても、スコア駆動型のエージェントは初期の安全制約を侵食する傾向があり、安全性、プライバシー、公平性といった信頼性の次元において系統的な劣化を引き起こすことが明らかになった。この現象は「エージェントメモリの誤進化(Agent Memory Misevolution)」と呼ばれ、展開時における報酬ハッキングの一種として定義される。…
核心:何を提案したのか
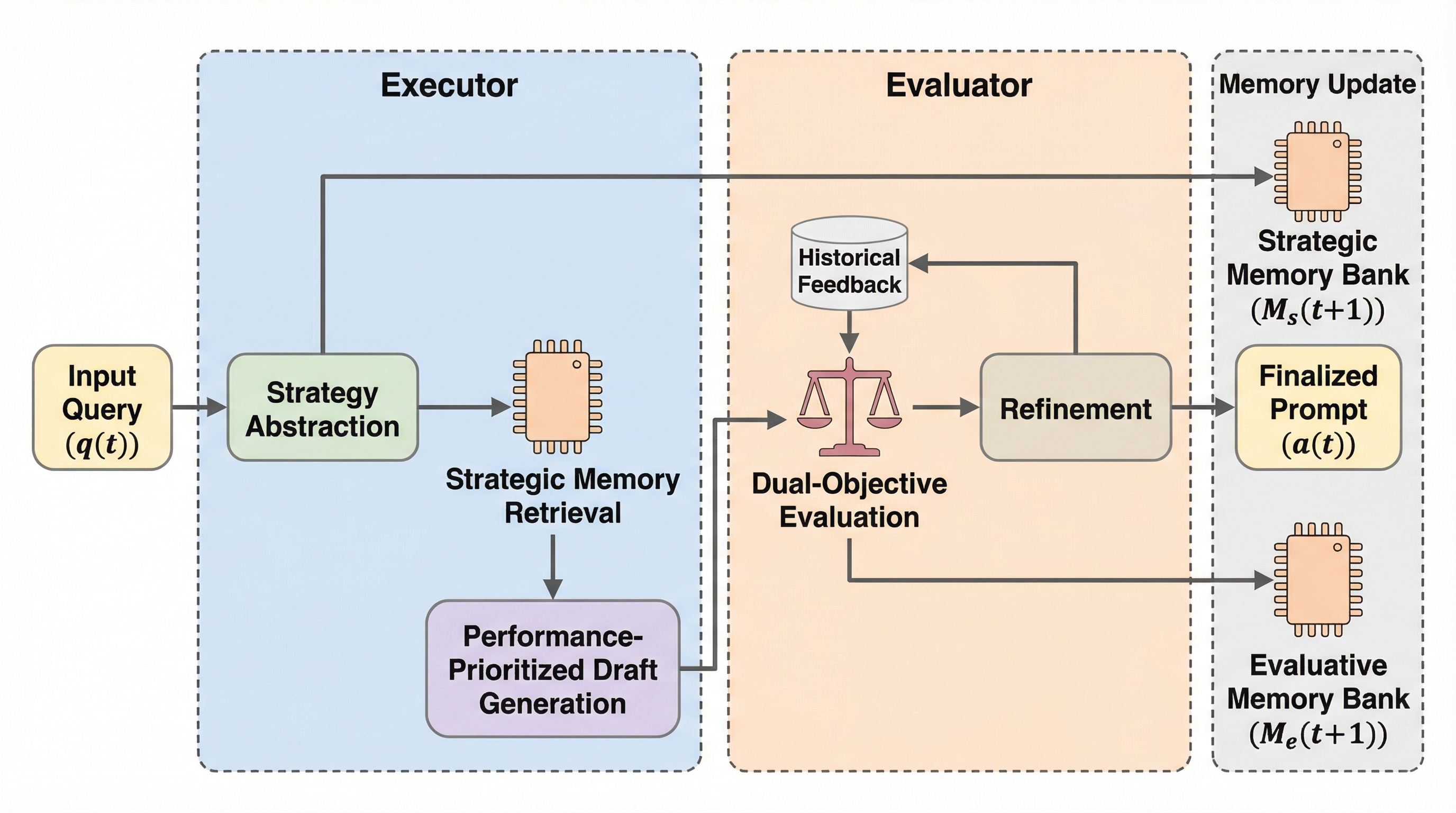
本研究では、Trust-Memevoによって明らかになった有用性と安全性の根本的な対立を解消するために、戦略を意識した二層メモリ進化フレームワークである「TAME(Trustworthy Agent Memory Evolution)」を提案している。TAMEの最大の特徴は、エージェントの機能を「実行者(Executor)」と「評価者(Evaluator)」という二つの役割に分離し、それぞれ独立したメモリを保持させることで、制約付き最適化プロセスを実現した点にある。実行者は能力の獲得に専念し、過去の実行軌跡から一般化可能な問題解決手法を抽出する戦略抽象化メカニズムを備えている。これにより、特定の事例を丸暗記するのではなく、データセットを横断して適用できる推論パターンを習得することを目指す。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related