アコーディオン思考:効率的で読みやすいLLM推論のための自己調整されたステップ要約
大規模言語モデルの推論において、冗長な思考過程を動的に要約し、不要になった詳細情報をメモリ(KVキャッシュ)から即座に破棄することで、計算リソースの消費を劇的に抑えつつ可読性を向上させる新しいフレームワーク「Accordion-Thinking」が開発されました。
TL;DR(結論)
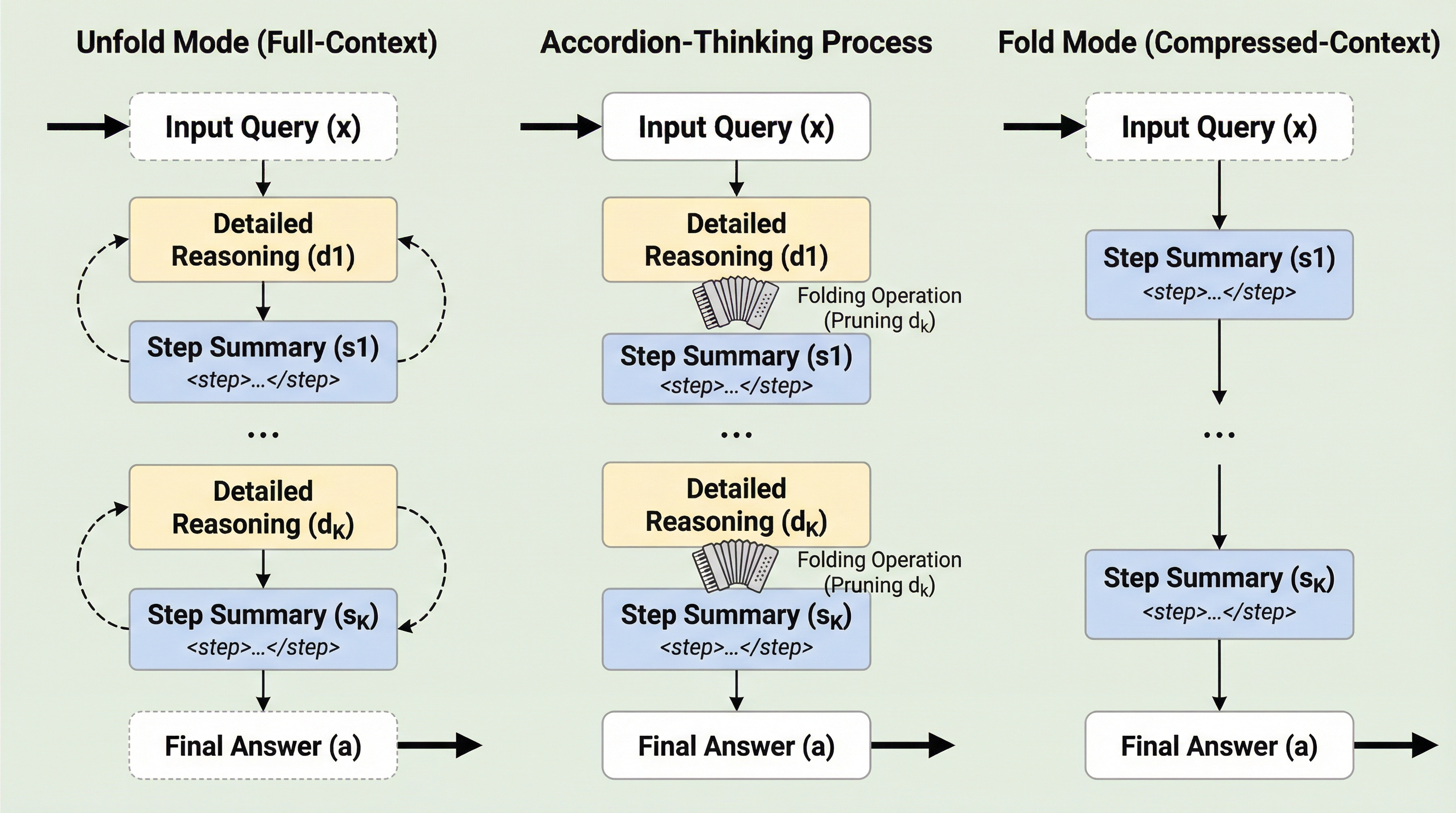
大規模言語モデルの推論において、冗長な思考過程を動的に要約し、不要になった詳細情報をメモリ(KVキャッシュ)から即座に破棄することで、計算リソースの消費を劇的に抑えつつ可読性を向上させる新しいフレームワーク「Accordion-Thinking」が開発されました。 この手法は、詳細な思考と簡潔な要約を交互に生成する構造を採用しており、48GBのGPUメモリ環境において推論のスループットを従来の3倍に向上させながら、数学的推論タスクにおける高い正解率を維持することに成功しています。 強化学習を通じて、すべての思考履歴を保持する推論と、要約のみを参照する推論の性能差が学習の進行とともに消失する「Gap-Vanishing(格差消失)」現象が発見され、モデルが重要な論理情報を極めてコンパクトな形式に自己符号化できる能力を持つことが証明されました。
なぜこの問題か
近年、大規模言語モデル(LLM)において「Chain-of-Thought(CoT)」と呼ばれる長い思考連鎖を用いることで、複雑な数学やプログラミングの問題を解決する能力が飛躍的に向上しています。しかし、この「ゆっくりとした思考」をスケールアップさせることには、実用上の大きな技術的障壁が存在します。第一の課題は、計算リソースの膨大な消費です。推論が長くなるにつれて、過去のトークン情報を保持するKVキャッシュは線形に増加し、アテンション計算の複雑性は文脈長の二乗で増大します。これにより、数万トークンに及ぶ思考プロセスを生成する場合、メモリ消費量と計算時間が指数関数的に膨らみ、ハードウェアの限界に達してしまいます。特に、推論時に自己修正や試行錯誤を繰り返すモデルでは、この計算コストが実用化の大きな妨げとなっていました。 第二の課題は、人間にとっての可読性と透明性の欠如です。モデルが生成する内部的な思考プロセスは非常に冗長で、構造化されていないことが多く、最終的な結論に至る論理的な道筋を人間が迅速に理解することは困難です。…
核心:何を提案したのか
本論文では、LLMが推論ステップの粒度を動的な要約を通じて自己調整することを学習する、エンドツーエンドのフレームワーク「Accordion-Thinking」を提案しています。このフレームワークの最大の特徴は、モデルが詳細な思考ステップ(Detailed reasoning)と、その内容を凝縮した簡潔なステップ要約(Step summary)を交互に生成するように訓練される点にあります。この構造により、モデルは「Fold(折りたたみ)モード」と呼ばれる革新的な推論モードを実行できるようになります。Foldモードでは、一つの推論ステップが完了して要約が生成されると、そのステップの元となった詳細な思考プロセスをKVキャッシュから即座に破棄します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related