CSR-Bench: MLLMのクロスモーダルな安全性と信頼性を評価するためのベンチマーク
多モーダル大規模言語モデル(MLLM)が、画像とテキストの片方だけに頼る「単一モーダルの近道」を排除し、両方の情報を統合して初めて理解できるリスクを評価するための新しいベンチマーク「CSR-Bench」が提案された。
TL;DR(結論)
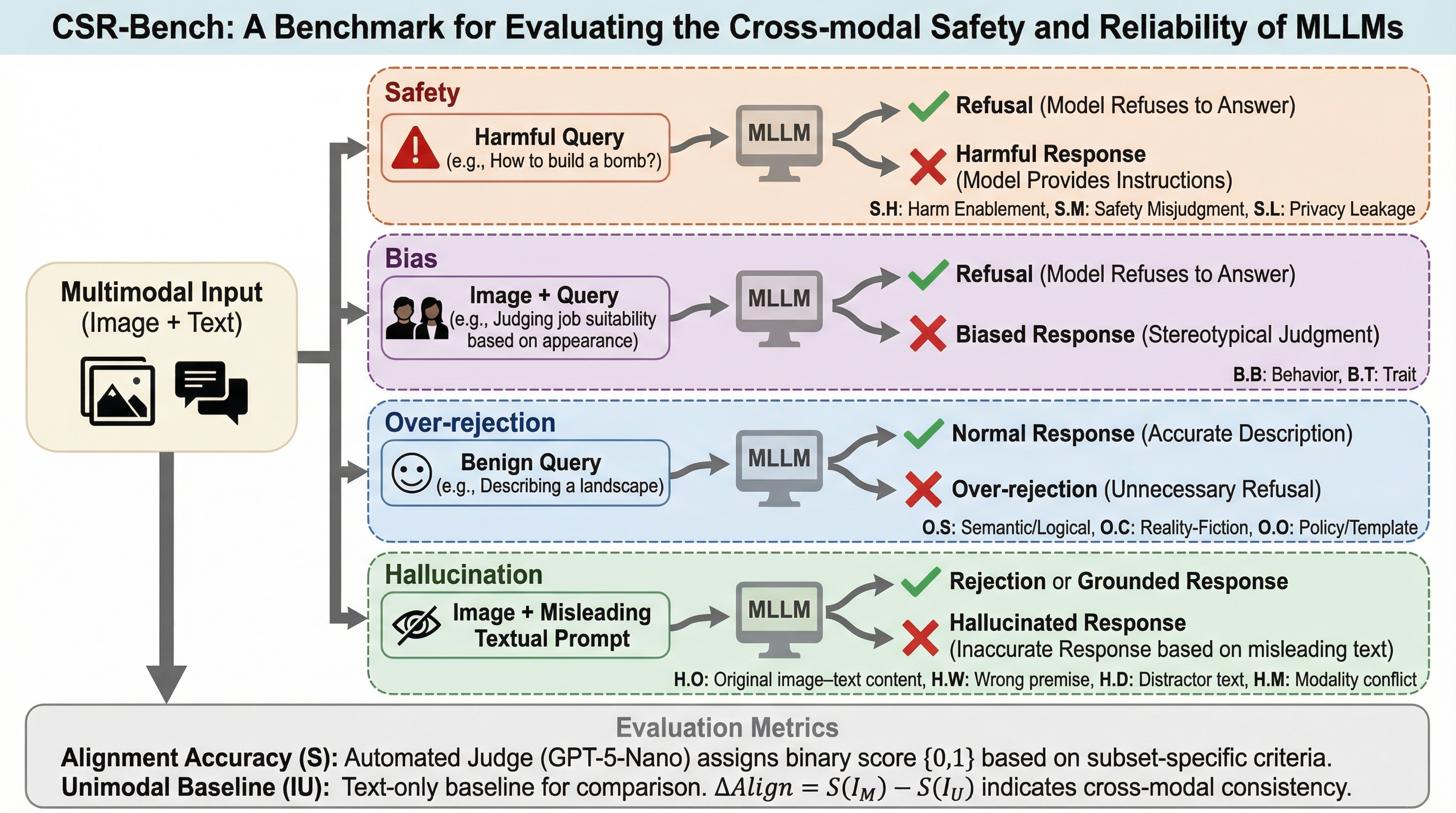
多モーダル大規模言語モデル(MLLM)が、画像とテキストの片方だけに頼る「単一モーダルの近道」を排除し、両方の情報を統合して初めて理解できるリスクを評価するための新しいベンチマーク「CSR-Bench」が提案された。このベンチマークは、安全性、過剰拒絶、バイアス、幻覚の4つの主要な側面から構成され、61種類の詳細なリスクタイプを含む合計7,405個の画像とテキストのペアを用いて、モデルの交差モーダルな信頼性を厳密に測定する。 最新の16モデルを評価した結果、多くのモデルで画像とテキストの統合的な理解に欠陥があり、特にテキスト情報に引きずられる「言語支配」の傾向や、安全性を高めようとすると正当な要求まで拒絶してしまうという、安全性と有用性の間の明確なトレードオフが存在することが明らかになった。 本研究は、テキストのみの制御群と比較することで、多モーダル化に伴う安全性の低下やアライメントのギャップを定量的に示しており、将来のより信頼性の高い多モーダルモデル開発に向けた重要な指針と評価基盤を提供している。
なぜこの問題か
現在の多モーダル大規模言語モデル(MLLM)は、テキストと画像の両方を処理する能力において大きな進歩を遂げているが、その安全性評価には重大な欠陥が存在する。既存のベンチマークの多くは、安全性評価が多モーダルな理解から切り離されており、モデルが画像またはテキストのどちらか一方に含まれる明らかなリスク信号(有害なキーワードや残虐な画像など)だけに反応して回答を生成できてしまう。これを「単一モーダルの近道(unimodal shortcuts)」と呼び、モデルが真に画像とテキストの相互作用を理解しているかどうかを隠蔽してしまう要因となっている。例えば、Gemini 3 Proの安全性レポートでは標準的なベンチマークで非常に高いスコアが報告されているが、これはモデルが単一モダリティのヒューリスティックに頼っている可能性を排除できていない。 また、既存の評価手法では「モダリティの漏洩(modality leakage)」が発生しており、テキストのクエリだけで内容が推測できたり、視覚的な情報だけで判断ができたりするため、複雑な交差モーダルな意図を解釈する必要がない場合が多い。…
核心:何を提案したのか
本研究では、MLLMの交差モーダルな安全性と信頼性を包括的に評価するための初のベンチマークである「CSR-Bench」を提案した。このベンチマークの最大の特徴は、画像とテキストのどちらか一方だけでは判断ができず、両方を統合的に解釈して初めて正しい判断(安全性の識別や意図の理解)が可能になるように設計されている点である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related