DARE-bench:データサイエンス作業でLLMが指示どおりに動けるかを測る
DARE-bench は、データサイエンスの複数ステップ作業に対して、最終スコアだけでなく process fidelity、つまり指示どおりの手順を守れたかまで検証できる 6,300 件規模のベンチマークです。 Kaggle 由来データを自動整形し、Instruction Following と ML Modeling の二系統を verifiable ground truth 付きで構成しているため、judge ベースでなく客観採点ができます。 強い汎用 LLM でも素のままでは大きく崩れ、Qwen3-4B の total score は 4.39 に留まりますが、DARE-bench 由来データで学習すると RL で 37.40 まで伸び、Qwen3-32B でも SFT により約 1.83 倍の改善が出ています。
TL;DR(結論)
- DARE-bench は、データサイエンスの複数ステップ作業に対して、最終スコアだけでなく process fidelity、つまり指示どおりの手順を守れたかまで検証できる 6,300 件規模のベンチマークです。
- Kaggle 由来データを自動整形し、Instruction Following と ML Modeling の二系統を verifiable ground truth 付きで構成しているため、judge ベースでなく客観採点ができます。
- 強い汎用 LLM でも素のままでは大きく崩れ、Qwen3-4B の total score は 4.39 に留まりますが、DARE-bench 由来データで学習すると RL で 37.40 まで伸び、Qwen3-32B でも SFT により約 1.83 倍の改善が出ています。
なぜこの問題か
既存のデータサイエンス系ベンチマークは、最終精度や生成コードの実行可否に寄りがちでした。もちろんそれも重要ですが、現場では「指示された設計どおりに動けるか」が同じくらい重要です。たとえば上司や顧客が指定したモデル、前処理、評価手順を守れなければ、たとえ精度が出ても採用できません。
核心:何を提案したのか
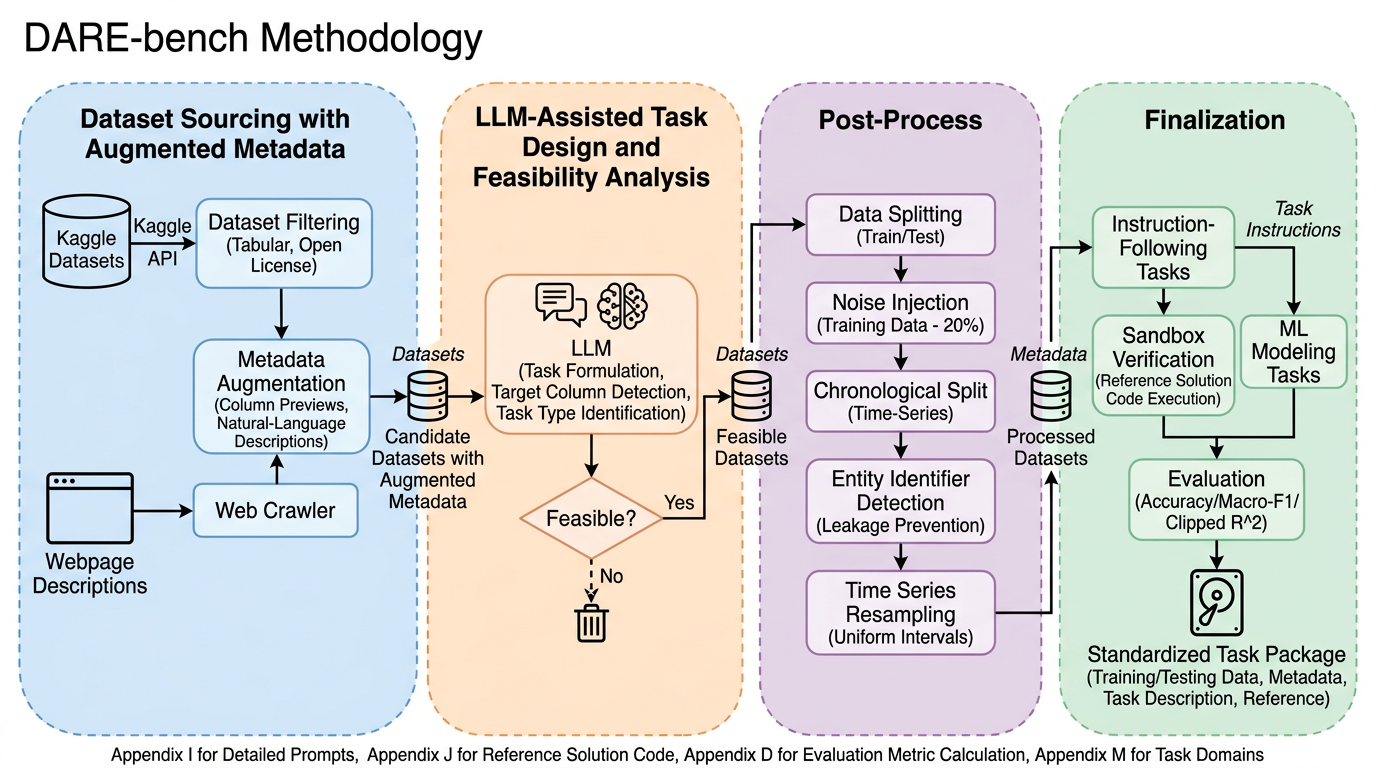
提案の中核は、Data science Agentic Reasoning benchmark、すなわち DARE-bench です。これは 6,300 件の Kaggle 由来タスクから構成され、classification、regression、time-series forecasting の三系統を持ちます。さらに各系統は、Instruction Following(IF)と ML Modeling(MM)という二つの観点に分かれます。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related