ATACompressor: LLMの長いコンテキスト処理を効率化する適応型タスク認識圧縮技術
ATACompressorは、大規模言語モデル(LLM)が長大な入力文を処理する際に、重要な情報が埋もれてしまう「情報の埋没(lost in the middle)」問題を解決するために開発された、革新的な適応型コンテキスト圧縮技術である。
TL;DR(結論)
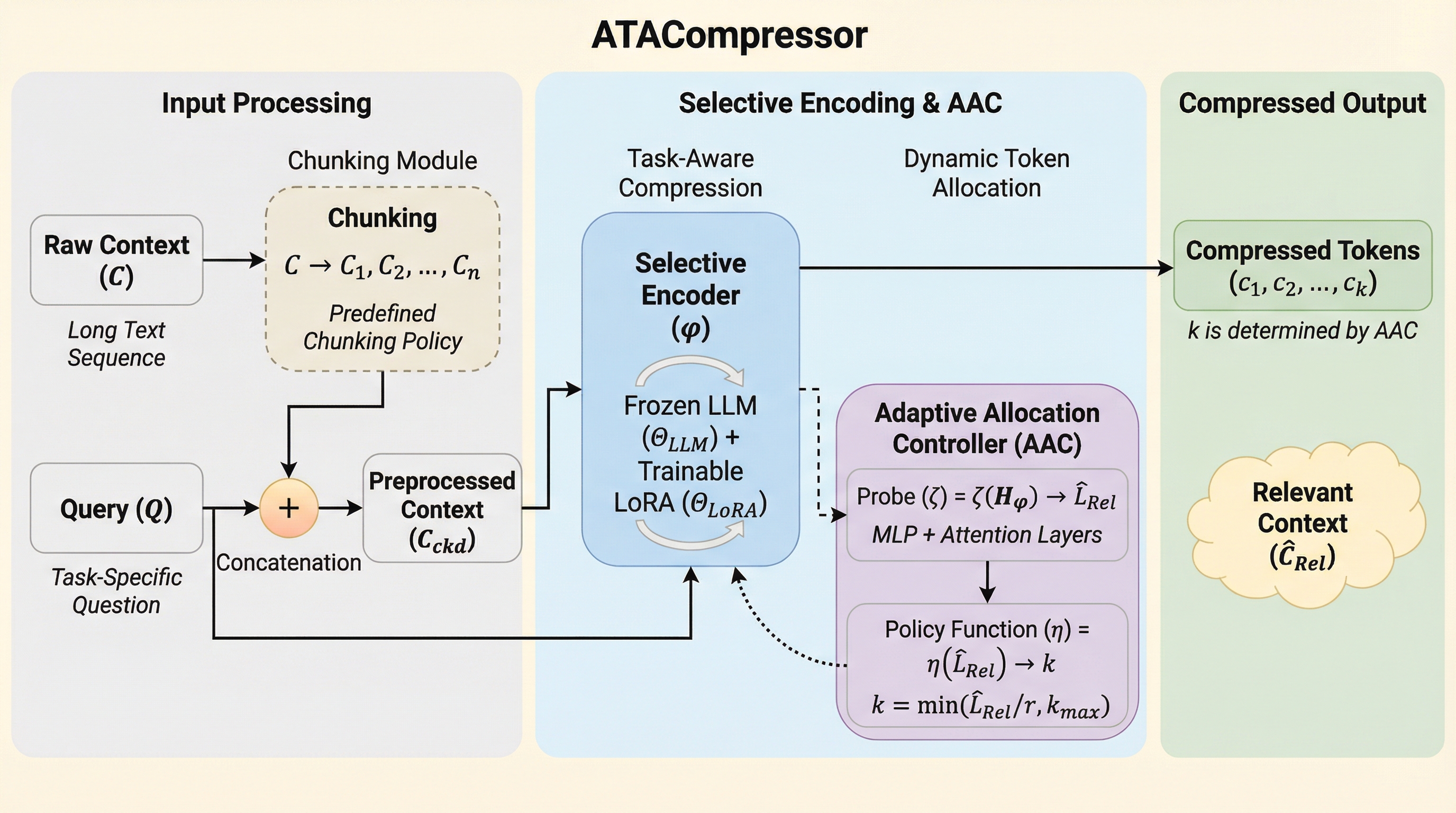
ATACompressorは、大規模言語モデル(LLM)が長大な入力文を処理する際に、重要な情報が埋もれてしまう「情報の埋没(lost in the middle)」問題を解決するために開発された、革新的な適応型コンテキスト圧縮技術である。 この手法は、入力された問いに対して関連する情報のみを特定して抽出する「選択的エンコーダ」と、その情報の量に応じて圧縮後のトークン数を動的に最適化する「適応型割り当てコントローラ(AAC)」という二つの主要なコンポーネントで構成されている。 複数の公開データセットを用いた検証の結果、ATACompressorは従来の固定的な圧縮手法と比較して、情報の保持能力と計算効率の両面で優れた性能を発揮し、高い回答精度を維持しながらリソース消費を最小限に抑えることに成功した。
なぜこの問題か
大規模言語モデル(LLM)は、自然言語理解や文章生成、質問回答などの多様なタスクで驚異的な性能を示しているが、モデル自体が静的であるという根本的な課題を抱えている。モデルは学習が完了した後に、新しい情報を自律的に更新したり、特定の専門領域に適応したりすることができない。このため、最新の知識や特定の文脈をモデルに注入するには、外部のコンテキストを利用する必要がある。この課題を解決するために、外部ソースから関連情報を取得してモデルに提供する検索拡張生成(RAG)などの技術が広く普及している。しかし、生のドキュメントをそのままモデルの入力に追加する単純なRAGの手法では、入力文が極端に長くなってしまうという副作用が生じる。 入力が長大になると、LLMはコンテキストの中央部分にある重要な情報を識別することが困難になり、結果として回答の精度が著しく低下する「lost in the middle」と呼ばれる現象が発生する。また、長いテキストの処理は計算コストの増大や推論の遅延を招き、リアルタイム性が求められる用途や、計算リソースが限られた環境での利用を大きく制限することになる。…
核心:何を提案したのか
本論文では、LLMの長いコンテキスト処理を効率化するための適応型タスク認識圧縮技術である「ATACompressor」を提案している。この手法の核心は、タスクに関連する情報のみを賢く選択して圧縮し、さらにその圧縮率を状況に応じて動的に変化させる点にある。ATACompressorは、主に「選択的エンコーダ(Selective Encoder)」、「適応型割り当てコントローラ(AAC)」、そして「ターゲットLLM(デコーダ)」の三つの主要なコンポーネントで構成されている。これにより、従来の圧縮手法が抱えていた情報の欠落や柔軟性の欠如という問題を根本から克服している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related