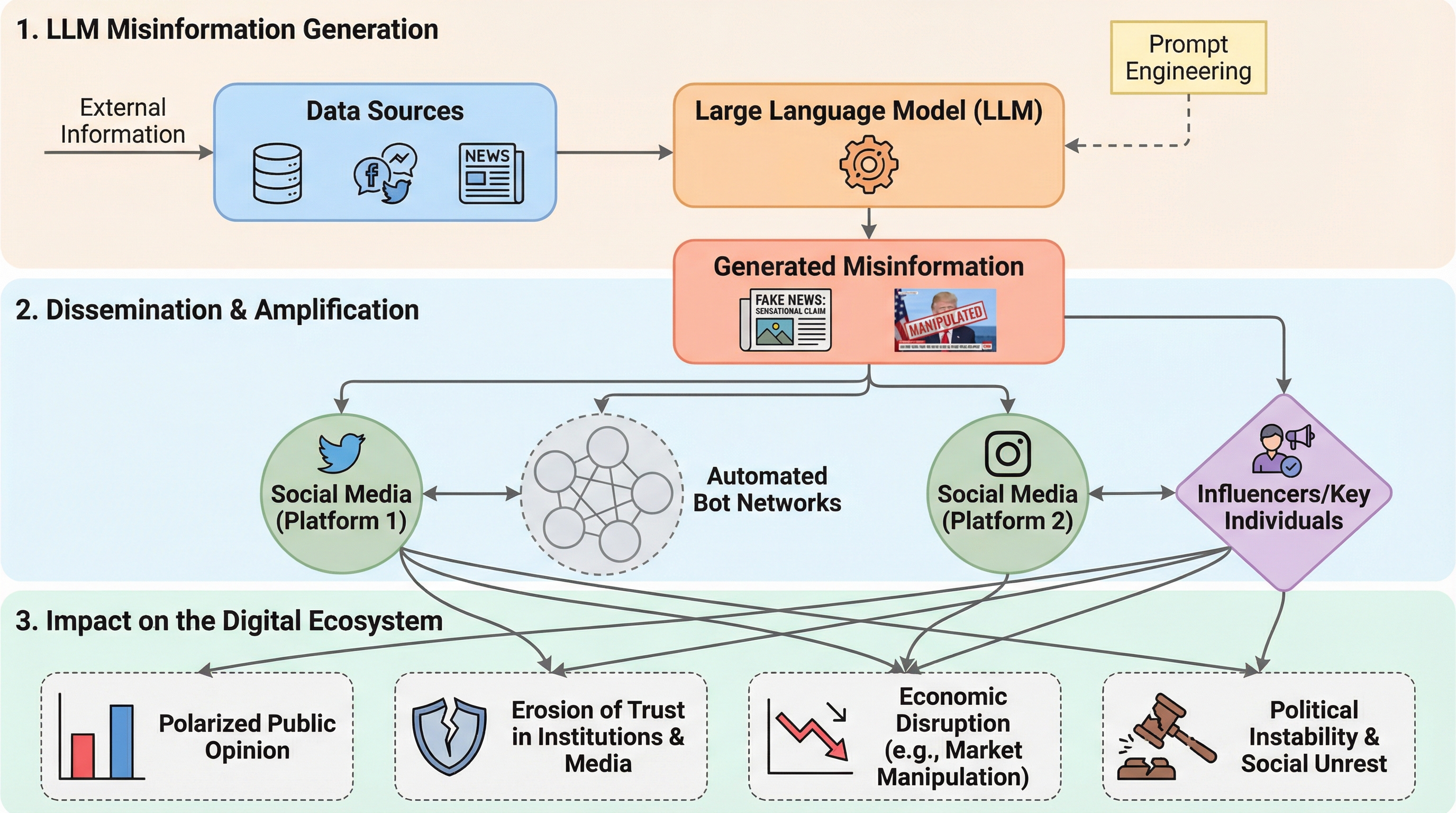
Learn-to-Distance:LLM生成テキスト検出のための距離学習
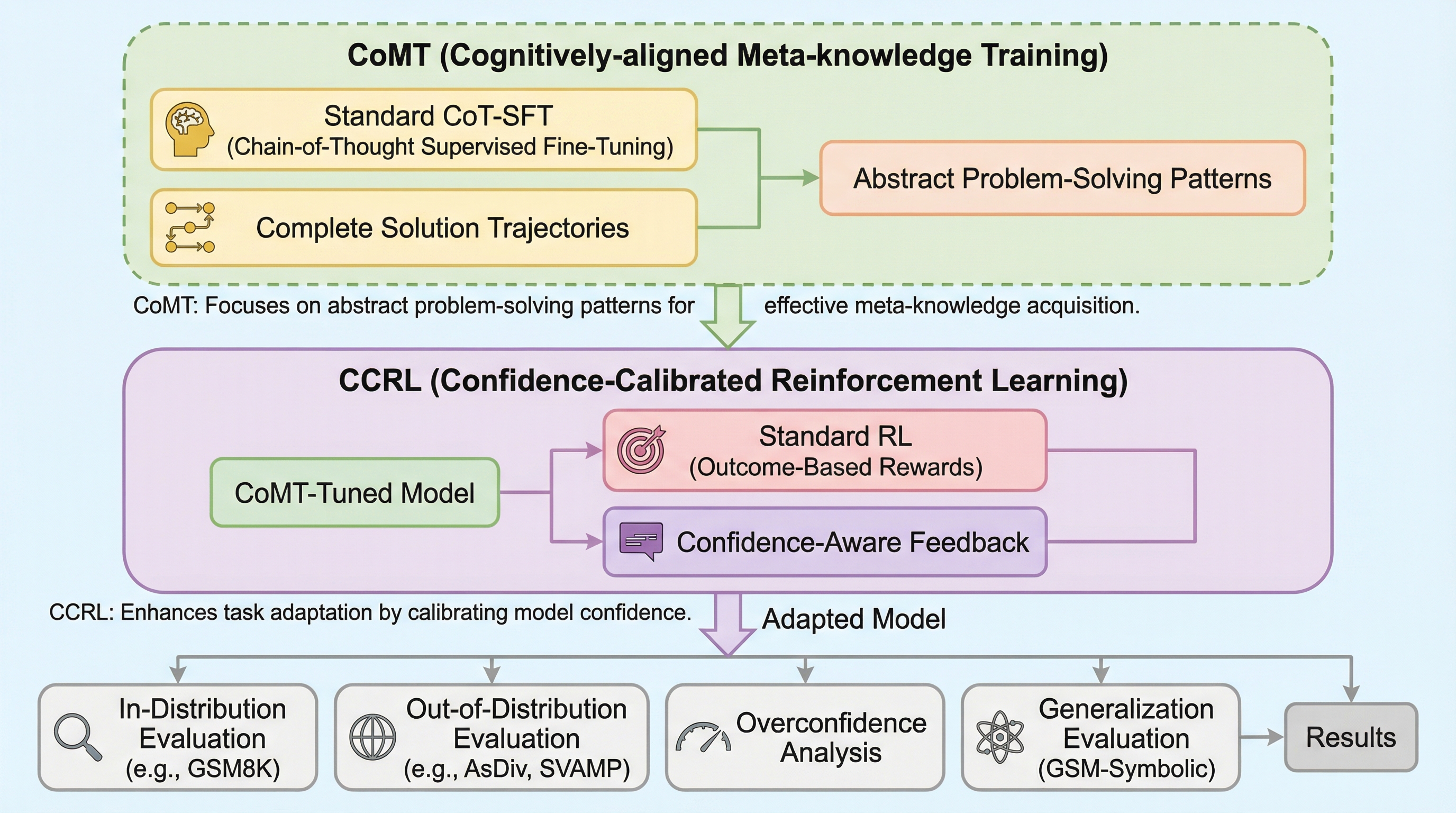
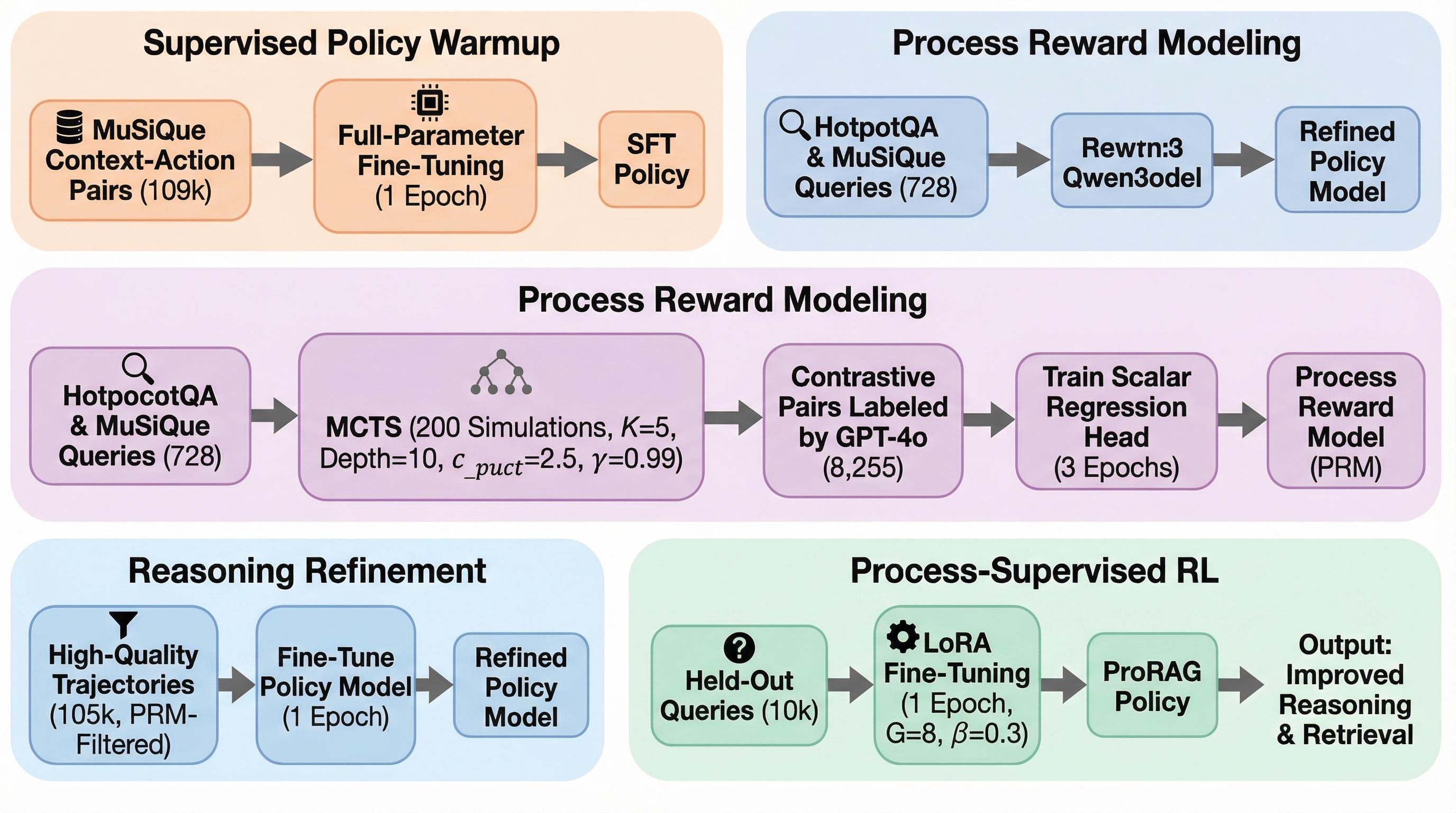
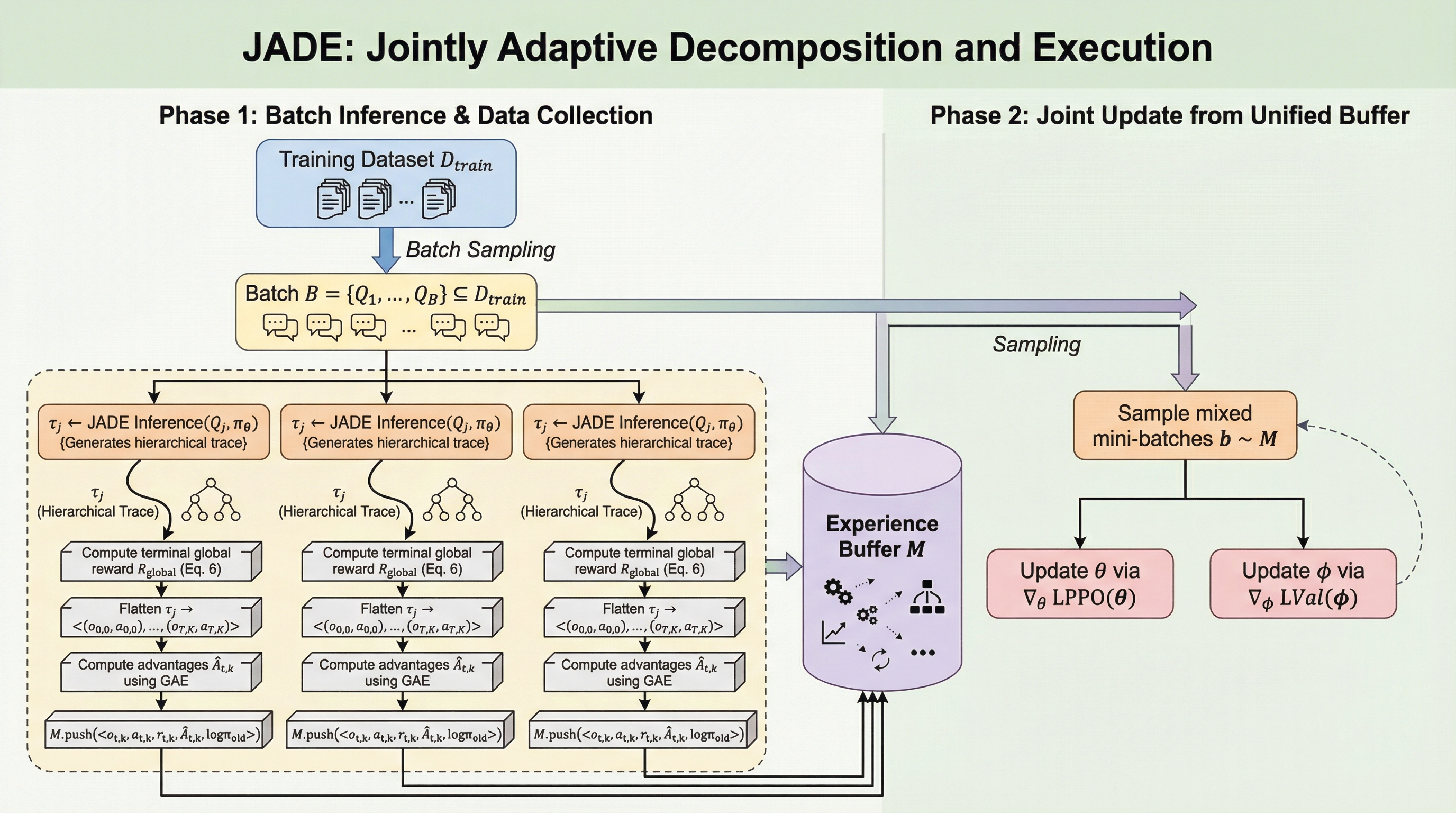
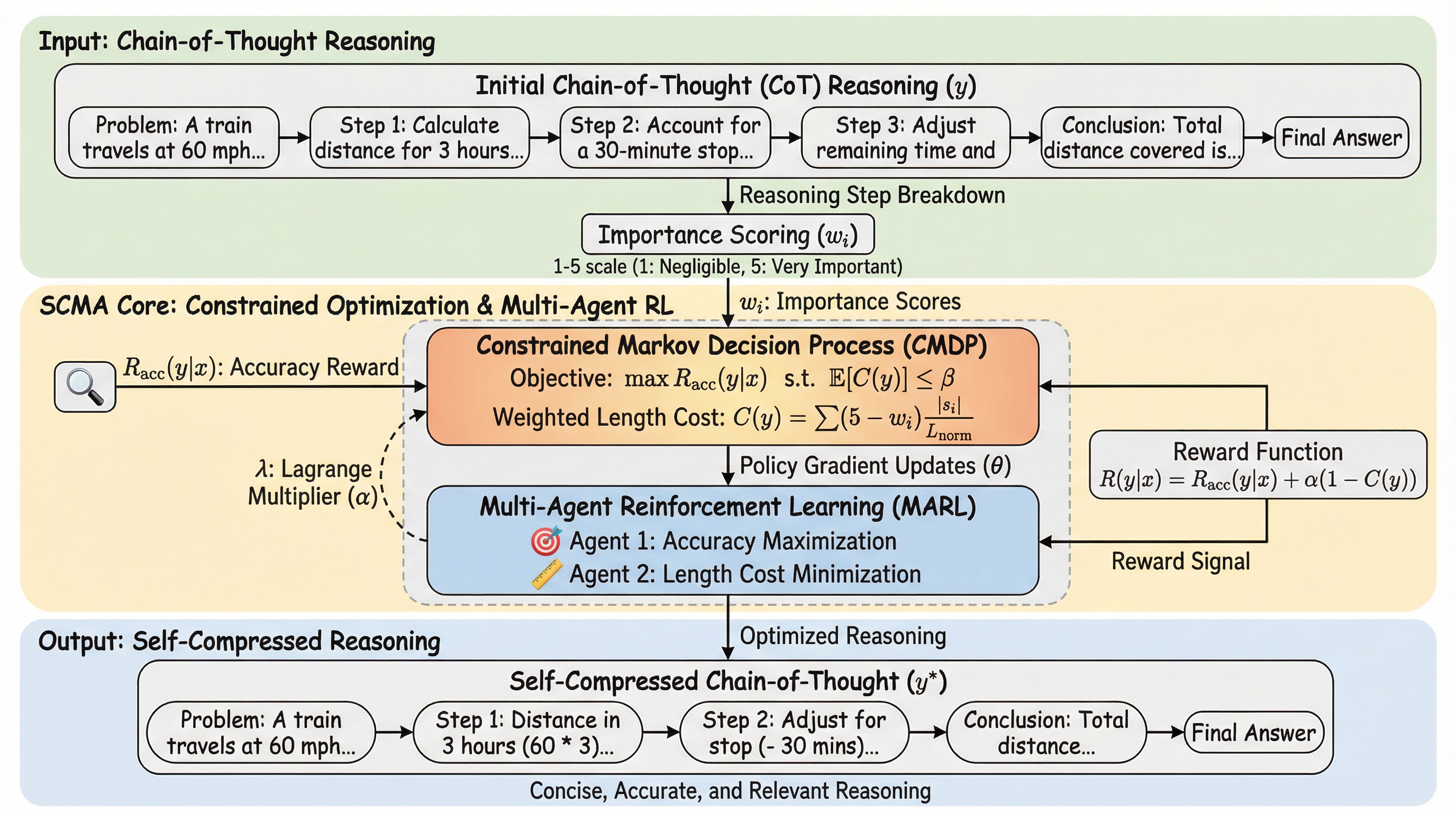
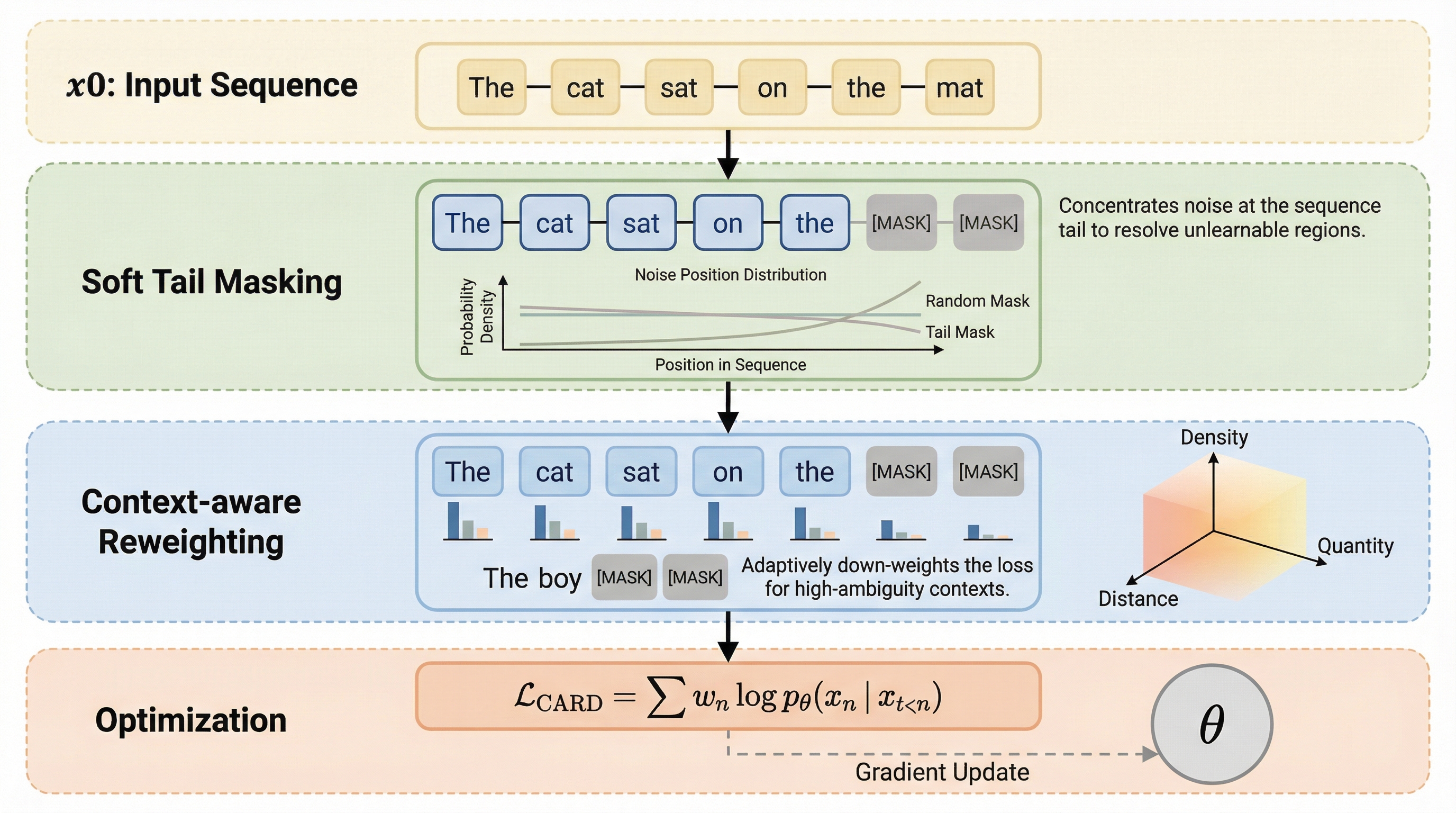
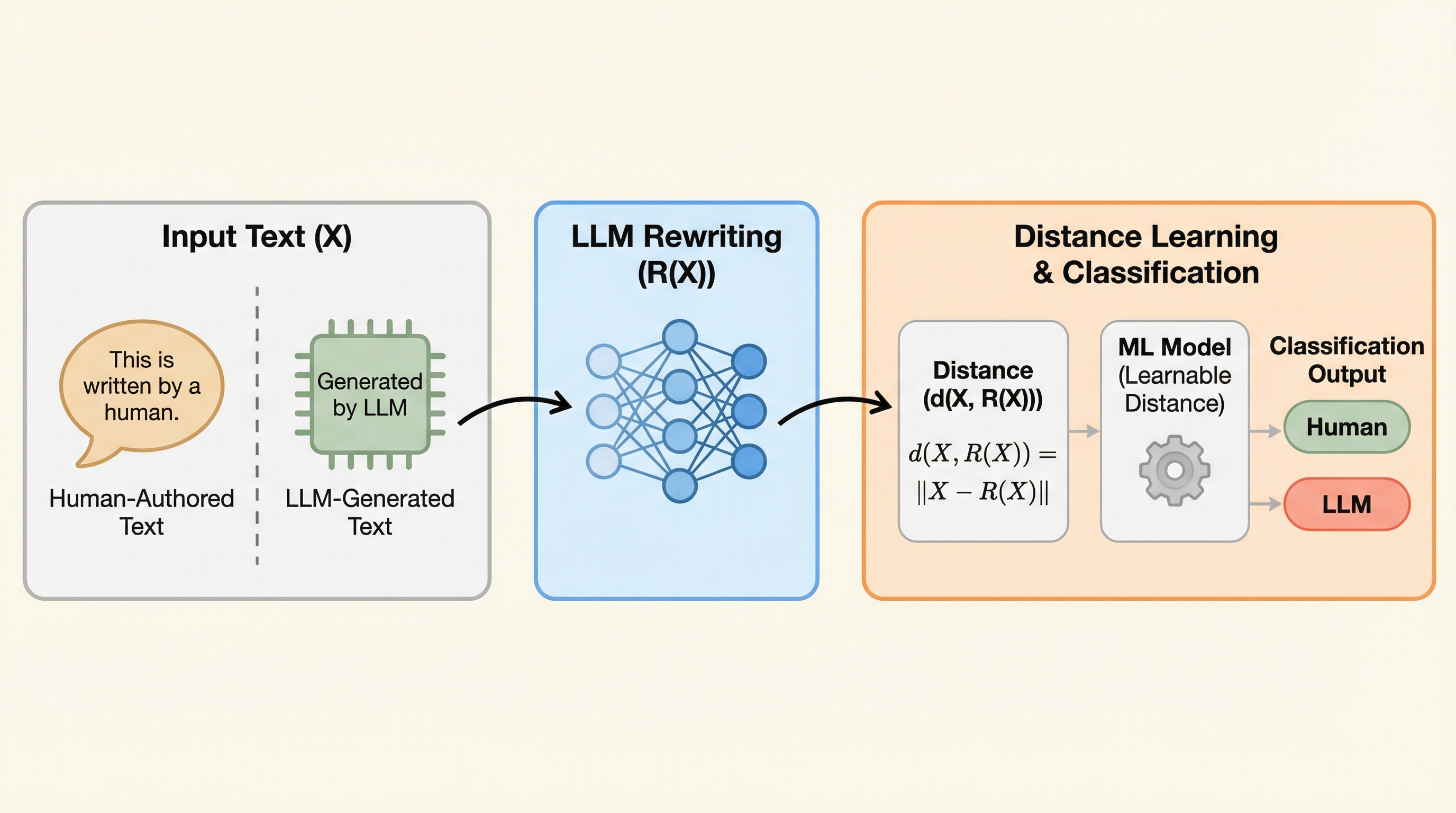
大規模言語モデル(LLM)が生成したテキストを精度高く識別するため、元のテキストとその書き換え版との間の距離を適応的に学習する新手法「Learn-to-Distance」が提案されました。 幾何学的なアプローチによって、人間が書いた文章はLLMの生成空間から外れているため書き換えによる変化が大きくなるという原理を解明し、固定された指標ではなく学習可能な距離関数を用いることで検出精度を大幅に向上させています。 実験ではGPTやClaude、Geminiなどの最新モデルを含む広範な設定で検証が行われ、既存の強力な手法と比較して57.8%から80.6%の相対的な性能改善を達成し、未知のプロンプトや敵対的攻撃に対しても高い堅牢性を示しました。