OVD: 教師モデルの言語スコアを活用した効率的なオンポリシー蒸留手法
従来の知識蒸留は、教師モデルの全語彙にわたる確率分布を生徒モデルに一致させる必要があり、膨大なメモリ消費と生徒の探索能力の制限が大きな課題となっていた。本研究が提案する「OVD(オンポリシー言語蒸留)」は、詳細なロジット情報の代わりに教師モデルが出力する0から9の離散的な言語スコアを用いた軌跡マッチングを行うことで、メモリ消費を劇的に削減しつつ、生徒モデルが自身の分布に基づいた自由な探索を行うことを可能にする。Web質問応答や数学的推論タスクにおける実験の結果、OVDは既存手法を大幅に上回る性能を示し、Web質問応答で最大12.9%、数学ベンチマークで最大25.7%の正解率向上を達成するとともに、メモリ効率を数万倍に改善することで、これまで困難だった長大な推論チェーンの学習を現実的なものとした。
TL;DR(結論)
従来の知識蒸留は、教師モデルの全語彙にわたる確率分布を生徒モデルに一致させる必要があり、膨大なメモリ消費と生徒の探索能力の制限が大きな課題となっていた。本研究が提案する「OVD(オンポリシー言語蒸留)」は、詳細なロジット情報の代わりに教師モデルが出力する0から9の離散的な言語スコアを用いた軌跡マッチングを行うことで、メモリ消費を劇的に削減しつつ、生徒モデルが自身の分布に基づいた自由な探索を行うことを可能にする。Web質問応答や数学的推論タスクにおける実験の結果、OVDは既存手法を大幅に上回る性能を示し、Web質問応答で最大12.9%、数学ベンチマークで最大25.7%の正解率向上を達成するとともに、メモリ効率を数万倍に改善することで、これまで困難だった長大な推論チェーンの学習を現実的なものとした。
なぜこの問題か
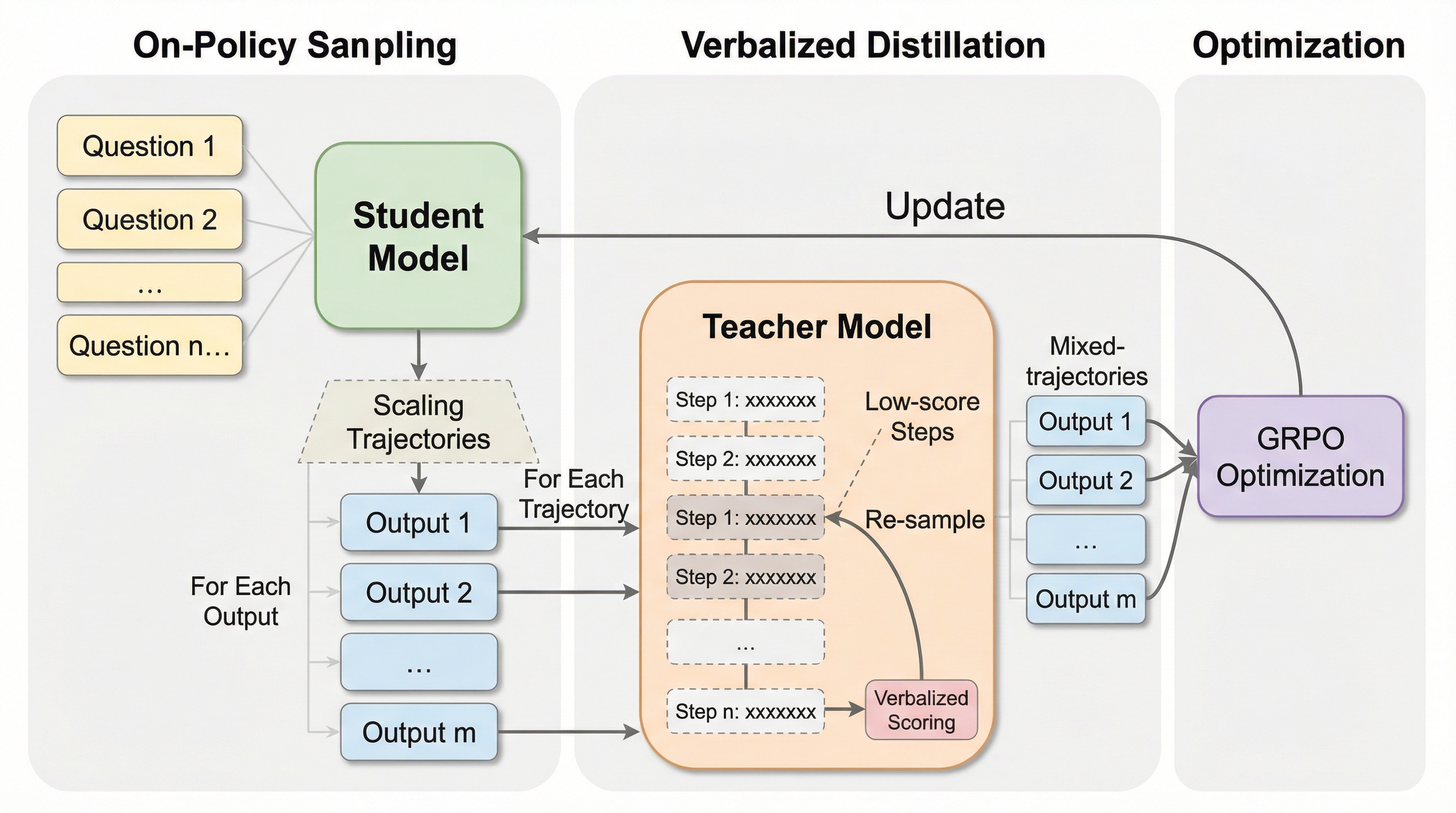
大規模言語モデルは多様なタスクで優れた能力を示すが、複雑な多段階の推論を実行することは依然として根本的な課題である。強化学習はこの推論能力を向上させる有望な手段であるが、大規模な推論モデルのトレーニングには膨大な計算コストとリソースが必要であり、広範な展開の障壁となっている。知識蒸留は、強力な教師モデルから効率的な生徒モデルへ推論能力を転移させる解決策を提供するが、既存の蒸留手法を強化学習に適用する際には、特にメモリ効率と環境からの言語フィードバックの活用において限界がある。従来の知識蒸留はトークンレベルで動作し、教師モデルが各デコードステップで語彙全体にわたる確率分布を出力することを要求する。この詳細な監視は豊富な勾配信号を提供する一方で、強化学習において深刻なメモリボトルネックを引き起こす。 例えば、バッチサイズやサンプル数、シーケンス長、語彙サイズを考慮すると、ロジットの保存だけで数百ギガバイトのメモリを消費し、現代のアクセラレータの容量をはるかに超えてしまう。…
核心:何を提案したのか
本研究では、従来のトークンレベルの確率一致を、教師モデルからの離散的な言語スコアを用いた軌跡マッチングに置き換える、メモリ効率の高いフレームワークである「OVD(オンポリシー言語蒸留)」を提案した。OVDは、語彙全体のロジットを監視する代わりに、教師モデルが推論の正しさについて提供する0から9までの言語スコアを活用することで、メモリ消費を劇的に削減する。この設計により、生徒モデルはトークンレベルの制約を受けることなく出力空間を自由に探索できるようになり、環境からの対話的なフィードバックを効果的に利用することが可能になる。OVDは、蒸留をトークンごとの一致ではなく、軌跡全体の最適化として再定式化することで、言語的なフィードバックをオンポリシーの蒸留プロセスに統合した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related