メタ思考から実行まで:汎用的かつ信頼性の高いLLM推論のための認知的に整合した事後学習
本研究は、人間の認知プロセスを模倣し、抽象的な戦略獲得(CoMT)と具体的なタスク適応(CCRL)を分離した新しいLLM事後学習フレームワークを提案しました。 この手法は、中間ステップの確信度に基づく報酬設計により、数学的推論において分布内データで2.19%、分布外データで4.
TL;DR(結論)
本研究は、人間の認知プロセスを模倣し、抽象的な戦略獲得(CoMT)と具体的なタスク適応(CCRL)を分離した新しいLLM事後学習フレームワークを提案しました。 この手法は、中間ステップの確信度に基づく報酬設計により、数学的推論において分布内データで2.19%、分布外データで4.63%の精度向上を達成し、未知の問題への高い汎用性を示しています。 従来の学習手法と比較して学習時間を65〜70%短縮し、トークン消費量を50%削減するという、極めて高い学習効率と推論の信頼性を両立させることに成功しました。
なぜこの問題か
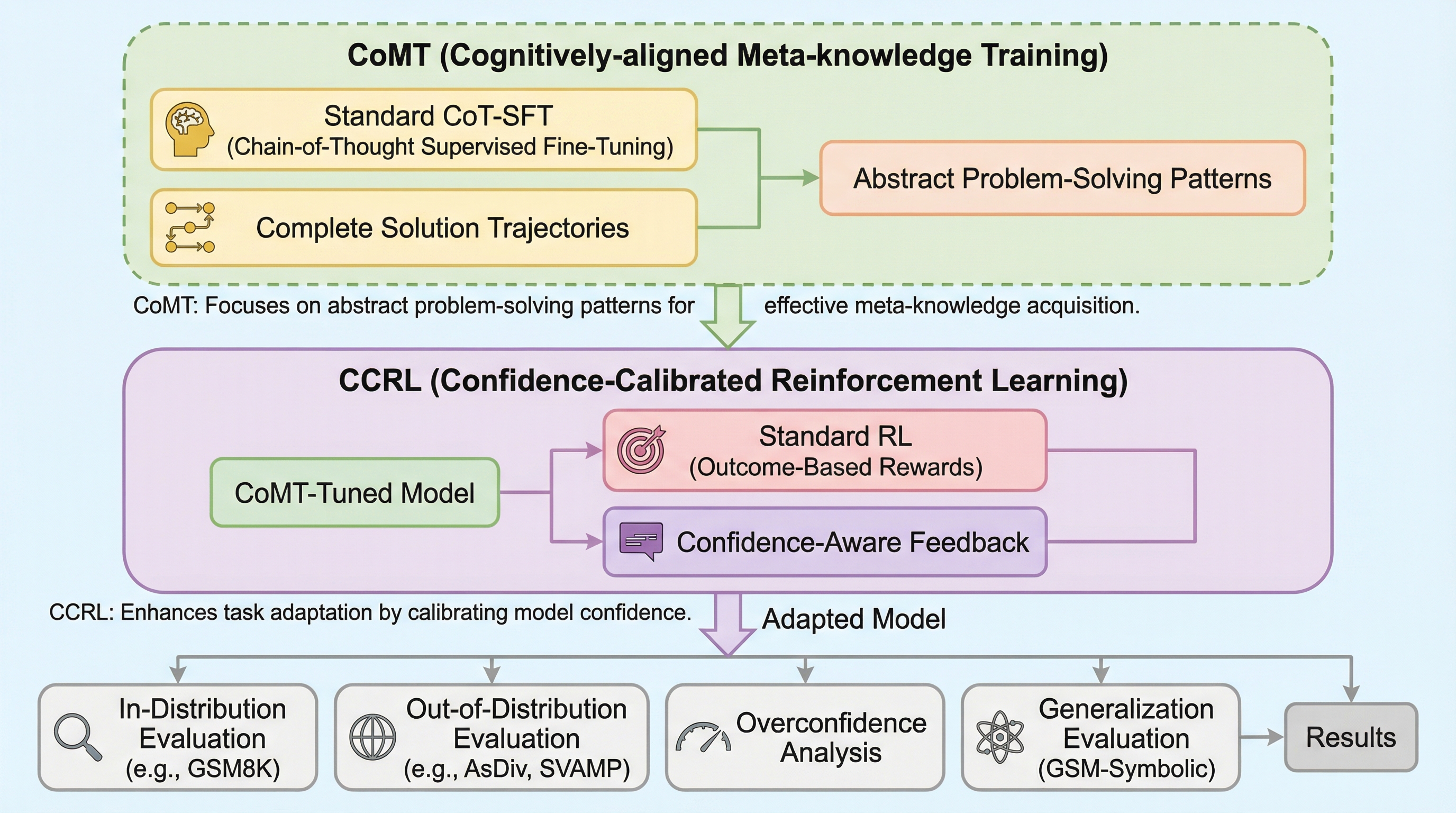
現在の大規模言語モデル(LLM)における事後学習の主流は、教師あり微調整(SFT)で推論の軌跡を模倣させ、その後に報酬に基づく強化学習(RL)を行う手法ですが、これには人間が問題を解決するプロセスと根本的に乖離しているという大きな課題があります。認知科学の知見によれば、人間はまず異なる問題に共通して利用できる抽象的な戦略、すなわち「メタ知識」を習得し、その後にその戦略を個別の事例に適応させるという2段階のプロセスを踏むことが知られています。これに対し、従来の学習手法は推論の全行程を一つの単位として扱うため、抽象的な戦略と具体的な実行プロセスが混同されてしまう「問題中心」の学習に陥っていました。 このような混同が生じると、モデルは「どのような一般戦略を習得すべきか」と「それを特定の事例にどう適応させるか」という、本来区別されるべき2つのプロセスを別々に内部化することが困難になります。その結果、学習した経験を未知の新しい状況へと応用する汎用能力が制限されてしまうのです。…
核心:何を提案したのか
本論文では、人間の認知プロセスを明示的に反映した、2段階の新しい事後学習フレームワークを提案しています。このフレームワークの核心は、学習プロセスを「メタ知識の獲得」と「タスクへの適応」という2つの独立したステージに切り離したことにあります。これにより、従来の「問題中心」の最適化から「戦略中心」の学習へと転換を図っています。第1ステージである「メタ知識の獲得」では、Chain-of-Meta-Thought(CoMT)と呼ばれる手法を導入しました。これは、具体的な数値計算などの実行詳細を含まない、抽象的な推論パターンのみを学習させる教師あり微調整です。モデルは具体的な答えを出すことよりも、問題の構造を理解し、どのような手順で解くべきかという抽象的な戦略を記述することに集中します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related