因果的自己回帰拡散言語モデル
CARD(Causal Autoregressive Diffusion)は、自己回帰モデルの安定した訓練効率と拡散モデルの高速な並列推論を、因果的アテンションマスクという単一の枠組みで統合した革新的な言語モデルである。
TL;DR(結論)
CARD(Causal Autoregressive Diffusion)は、自己回帰モデルの安定した訓練効率と拡散モデルの高速な並列推論を、因果的アテンションマスクという単一の枠組みで統合した革新的な言語モデルである。従来の拡散モデルが抱えていた「双方向アテンションへの依存によるKVキャッシュ利用不可」や「ブロック単位の訓練に伴う膨大な計算負荷」という構造的課題を、因果的制約下での拡散プロセスの再構成によって根本から解決している。10億パラメータ規模の検証では、既存の拡散モデルを精度で5.7ポイント上回り、訓練遅延を3分の1に抑えつつ、推論時には確信度に基づく並列生成により最大4倍の高速化を達成し、自己回帰モデルと同等の品質と高いデータ効率を実証した。
なぜこの問題か
現在の大型言語モデル(LLM)において主流となっている自己回帰モデル(ARM)は、トークンを一つずつ順番に生成する逐次的なデコーディングプロセスを採用している。しかし、モデルの規模が拡大し、生成すべきシーケンスが長くなるにつれて、この逐次的な性質が推論速度における深刻なボトルネックとなっている。この非効率性を解消する手段として、テキスト拡散モデルが大きな注目を集めてきた。初期の離散拡散モデルは、最適化の不安定さや推論の遅延といった課題を抱えていたが、その後、簡略化されたマスク付き離散拡散モデル(MDLM)が登場したことで、スケーリング則の適用が可能になり、拡散モデルの実用性は大きく向上した。 しかし、標準的なMDLMには依然として重大な構造的制約が存在する。MDLMは双方向アテンション(Full Attention)に依存しているため、自己回帰モデルで一般的に用いられるKVキャッシュ(Key-Valueキャッシュ)を利用することができない。その結果、長いシーケンスを生成する際の推論スループットが、実用的な自己回帰モデルのレベルに達しないという問題がある。…
核心:何を提案したのか
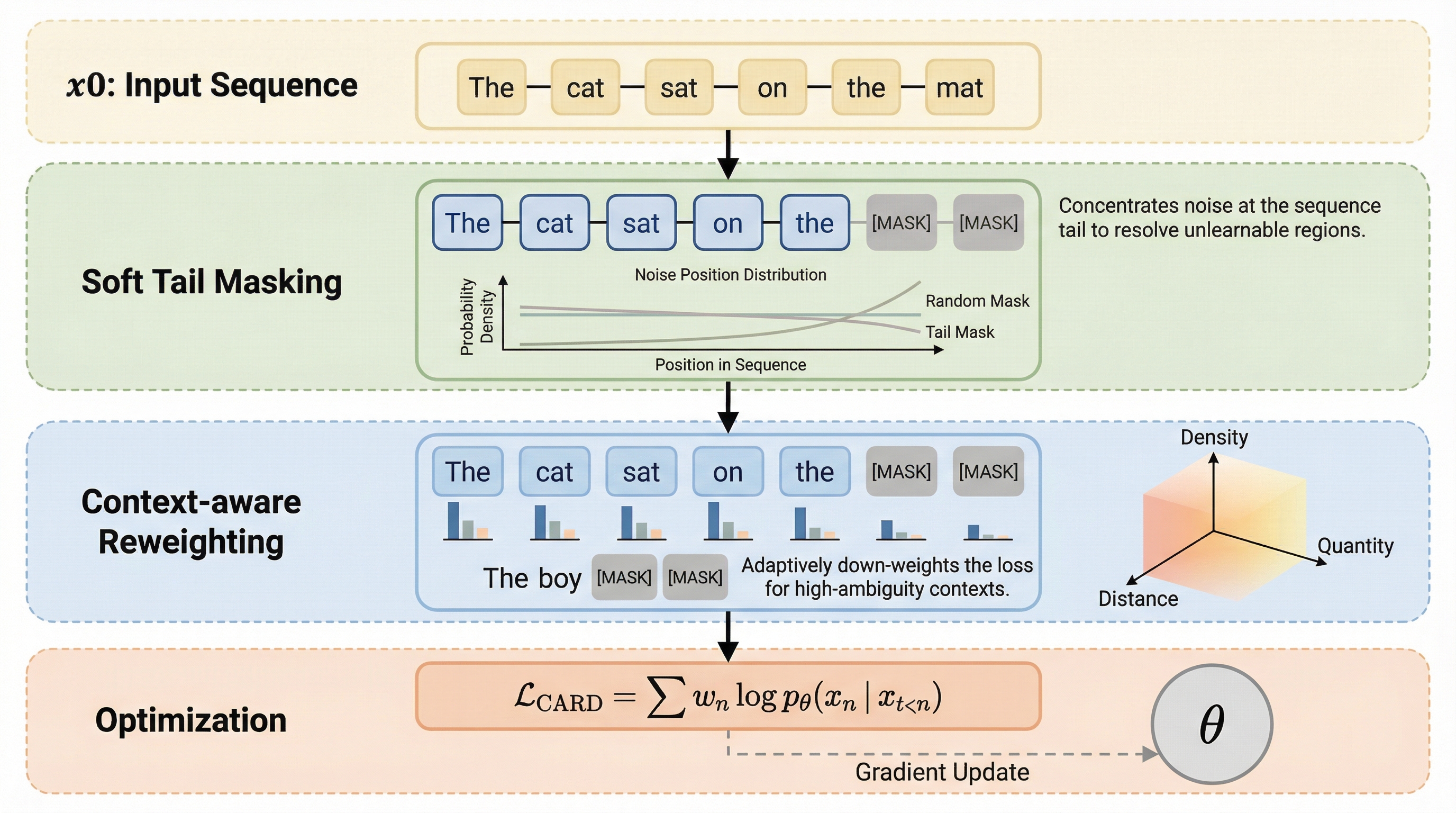
本研究では、自己回帰モデルの訓練の安定性と拡散モデルの柔軟な生成能力を高度に融合させた「因果的自己回帰拡散(CARD)」フレームワークを提案している。CARDの核心的なアイデアは、厳密な因果的制約(Causal Constraint)の下で拡散プロセスを実行することにある。具体的には、シフトされた因果的アテンションメカニズムを採用しており、各位置のトークンは、それより前のノイズが付加されたコンテキストに基づいて元のトークンを予測する。この設計により、GPTスタイルのモデルに固有の三角形のアテンションマスクを完全に維持したまま、1回のフォワードパスでシーケンス全体に対して密な拡散損失を生成することが可能になった。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related