マルチエージェント強化学習によるChain-of-Thoughtの自己圧縮
大規模推論モデル(LRM)における冗長な思考プロセスが引き起こす推論コストの増大と、従来の長さペナルティ手法が抱える「簡潔さと正確性のトレードオフ」を解決するため、マルチエージェント強化学習(MARL)を用いた自己圧縮フレームワーク「SCMA」が提案されました。
TL;DR(結論)
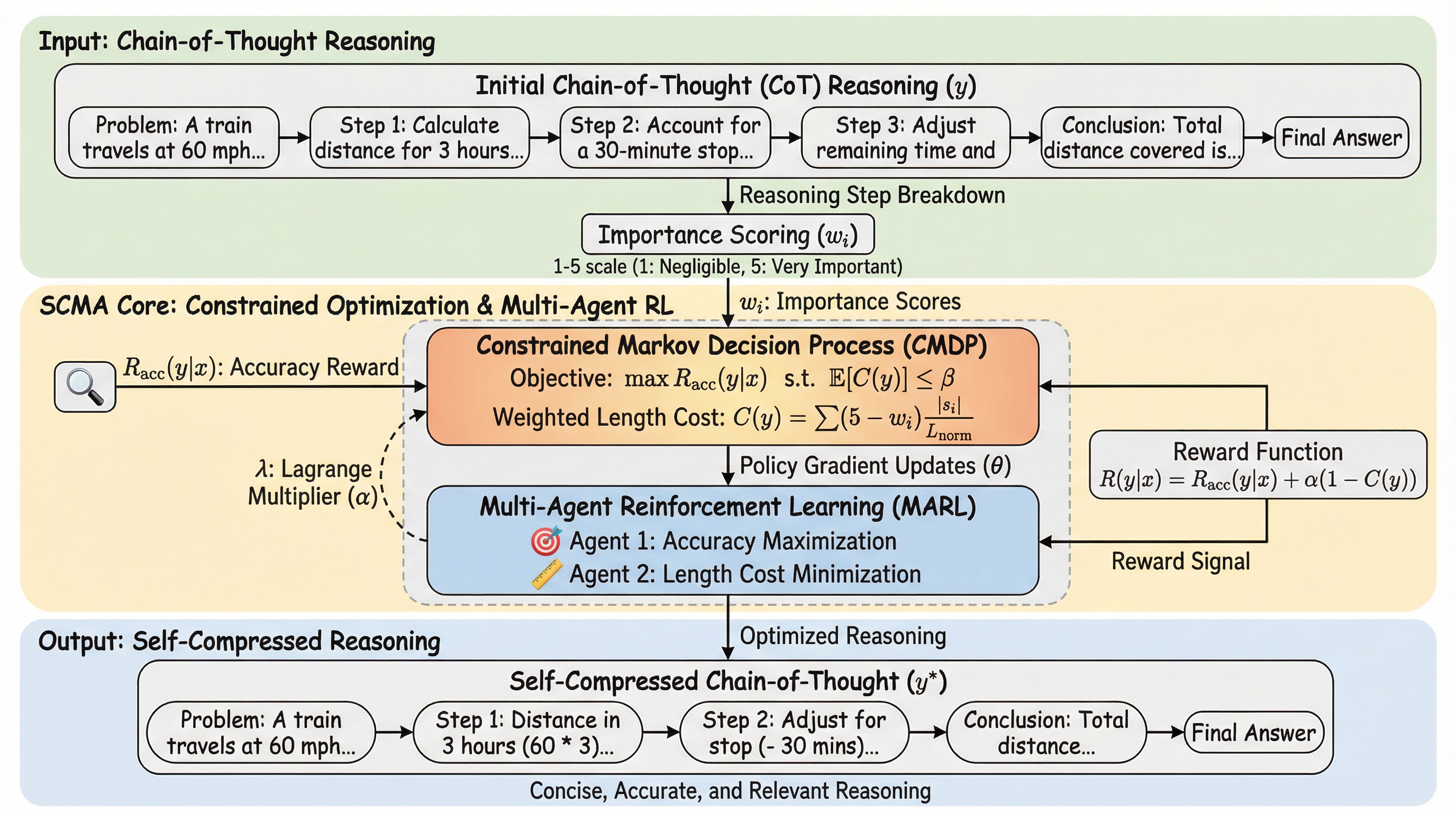
大規模推論モデル(LRM)における冗長な思考プロセスが引き起こす推論コストの増大と、従来の長さペナルティ手法が抱える「簡潔さと正確性のトレードオフ」を解決するため、マルチエージェント強化学習(MARL)を用いた自己圧縮フレームワーク「SCMA」が提案されました。 SCMAは、思考プロセスを生成する「推論エージェント」、論理的な塊に分割する「セグメンテーション・エージェント」、各塊の重要度を評価する「スコアリング・エージェント」の3つの役割を単一のモデル内で協調させ、重要度に基づいた重み付き長さペナルティを導入します。 実験の結果、SCMAは推論の長さを11.1%から39.0%削減しながら、正解率を4.33%から10.02%向上させることに成功し、従来の単一エージェントによる強化学習手法と比較して、追加の推論コストをかけずに効率的で強力な推論能力を獲得できることが実証されました。
なぜこの問題か
近年、大規模推論モデル(LRM)は、詳細な思考連鎖(CoT)を用いることで、自己反省やバックトラッキング、検証といった複雑な問題解決能力を示しています。しかし、この「深く考える」能力は、強化学習(RL)の最適化プロセスにおいて、スパースな結果ベースの報酬に依存しているため、効率性のボトルネックを生じさせています。モデルは報酬の確実性を最大化しようとするあまり、本質的ではないステップや繰り返しの検証を含む、過度に長い推論経路を生成する「オーバーシンキング(考えすぎ)」の状態に陥りやすくなっています。このような冗長な推論は、デプロイ時の推論レイテンシを大幅に増大させ、ユーザーとのインタラクティブな体験を損なう原因となります。 既存の解決策として、推論の長さにペナルティを課す手法が提案されていますが、これらには重大な欠陥があります。従来の長さペナルティは、推論ステップの個別の価値を考慮せず、シーケンス全体の長さを一律に罰する「未分化な戦略」を採用しています。このため、モデルは長さの制約を満たすために、正解を導き出すために不可欠な重要な論理ステップまで犠牲にしてしまうリスクがあります。…
核心:何を提案したのか
本研究では、マルチエージェント強化学習(MARL)を活用したエンドツーエンドのフレームワーク「SCMA(Self-Compression via MARL)」を提案しています。SCMAは、思考プロセスの圧縮タスクを「協調ゲーム」として再定義し、3つの専門的な役割を持つエージェントを導入します。具体的には、解の探索と推論パスの生成を担う「推論エージェント(Reasoning Agent)」、推論パスを離散的な論理的塊(チャンク)に構造的に解析する「セグメンテーション・エージェント(Segmentation Agent)」、そして各チャンクが最終的な導出にどれだけ実質的に貢献したかを定量化する「スコアリング・エージ…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related